如果你也在 怎样代写优化算法optimisation algorithms这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
优化算法是一个通过比较各种解决方案来反复执行的程序,直到找到一个最佳或满意的解决方案。随着计算机的出现,优化已成为计算机辅助设计活动的一部分。
statistics-lab™ 为您的留学生涯保驾护航 在代写优化算法optimisation algorithms方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写优化算法optimisation algorithms代写方面经验极为丰富,各种代写优化算法optimisation algorithms相关的作业也就用不着说。
我们提供的优化算法optimisation algorithms及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等楖率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等楖率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
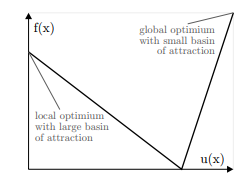
数学代写|优化算法作业代写optimisation algorithms代考|Problematic and Beneficial
Redundancy in the context of global optimization is a feature of the genotypephenotype mapping and means that multiple genotypes map to the same phenotype, i.e., the genotype-phenotype mapping is not injective. The role of redundancy in the genome is as controversial as that of neutrality [230]. There exist many accounts of its positive influence on the optimization process. Shackleton et al $[194,197]$, for instance, tried to mimic desirable evolutionary properties of RNA folding [106]. They developed redundant genotypephenotype mappings using voting (both, via uniform redundancy and via a non-trivial approach), Turing machine-like binary instructions, Cellular automata, and random Boolean networks [114]. Except for the trivial voting mechanism based on uniform redundancy, the mappings induced neutral networks which proved beneficial for exploring the problem space. Especially the last approach provided particularly good results $[194,197]$. Possibly converse
effects like epistasis (see Section 6 ) arising from the new genotype-phenotype mappings have not been considered in this study.
Redundancy can have a strong impact on the explorability of the problem space. When utilizing a one-to-one mapping, the translation of a slightly modified genotype will always result in a different phenotype. If there exists a many-to-one mapping between genotypes and phenotypes, the search operations can create offspring genotypes different from the parent which still translate to the same phenotype. The optimizer may now walk along a path through this neutral network. If many genotypes along this path can be modified to different offspring, many new solution candidates can be reached $[197]$. The experiments of Shipman et al $[198,196]$ additionally indicate that neutrality in the genotype-phenotype mapping can have positive effects.
Yet, Rothlauf [182] and Shackleton et al [194] show that simple uniform redundancy is not necessarily beneficial for the optimization process and may even slow it down. There is no use in introducing encodings which, for instance, represent each phenotypic bit with two bits in the genotype where 00 and 01 map to 0 and 10 and 11 map to $1 .$
数学代写|优化算法作业代写optimisation algorithms代考|Summary
Different from ruggedness which is always bad for optimization algorithms, neutrality has aspects that may further as well as hinder the process of finding good solutions. Generally we can state that degrees of neutrality $\nu$ very close to 1 degenerate optimization processes to random walks. Some forms of neutral networks $[14,15,27,105,208,222,223,237]$ accompanied by low (nonzero) values of $\nu$ can improve the evolvability and hence, increase the chance of finding good solutions.
Adverse forms of neutrality are often caused by bad design of the search space or genotype-phenotype mapping. Uniform redundancy in the genome should be avoided where possible and the amount of neutrality in the search space should generally be limited.
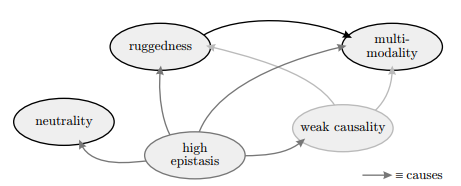
数学代写|优化算法作业代写optimisation algorithms代考|Epistasis
In biology, epistasis is defined as a form of interaction between different genes [163]. The term was coined by Bateson [16] and originally meant that one gene suppresses the phenotypical expression of another gene. In the context of statistical genetics, epistasis was initially called “epistacy” by Fisher [74]. According to Lush [132], the interaction between genes is epistatic if the effect on the fitness of altering one gene depends on the allelic state of other genes. This understanding of epistasis comes very close to another biological
expression: Pleiotropy, which means that a single gene influences multiple phenotypic traits [239]. In global optimization, such fine-grained distinctions are usually not made and the two terms are often used more or less synonymously.
Definition 3 (Epistasis). In optimization, Epistasis is the dependency of the contribution of one gene to the value of the objective functions on the allelic state of other genes $[4,51,153]$.
We speak of minimal epistasis when every gene is independent of every other gene. Then, the optimization process equals finding the best value for each gene and can most efficiently be carried out by a simple greedy search [51]. A problem is maximally epistatic when no proper subset of genes is independent of any other gene $[205,153]$. Examples of problems with a high degree of epistasis are Kauffman’s NK fitness landscape $[113,115]$, the p-Spin model $[6]$, and the tunable model of Weise et al [232].
优化算法代考
数学代写|优化算法作业代写optimisation algorithms代考|Problematic and Beneficial
全局优化上下文中的冗余是基因型表型映射的一个特征,意味着多个基因型映射到相同的表型,即基因型-表型映射不是单射的。基因组中冗余的作用与中性的作用一样有争议[230]。有许多关于它对优化过程的积极影响的说法。沙克尔顿等人[194,197]例如,试图模拟 RNA 折叠的理想进化特性 [106]。他们使用投票(通过统一冗余和通过非平凡方法)、类似图灵机的二进制指令、元胞自动机和随机布尔网络 [114] 开发了冗余基因型表型映射。除了基于统一冗余的琐碎投票机制外,映射引入了中性网络,这被证明有利于探索问题空间。尤其是最后一种方法提供了特别好的结果[194,197]. 可能会交谈
本研究未考虑由新的基因型-表型映射引起的上位性(见第 6 节)等效应。
冗余对问题空间的可探索性有很大的影响。当使用一对一映射时,稍微修改的基因型的翻译总是会导致不同的表型。如果在基因型和表型之间存在多对一映射,则搜索操作可以创建与仍转化为相同表型的亲本不同的后代基因型。优化器现在可以沿着这条中性网络的路径行走。如果可以将这条路径上的许多基因型修改为不同的后代,则可以找到许多新的候选解决方案[197]. Shipman 等人的实验[198,196]另外表明基因型 – 表型映射中的中性可以产生积极影响。
然而,Rothlauf [182] 和 Shackleton 等人 [194] 表明,简单的统一冗余不一定有利于优化过程,甚至可能减慢优化过程。引入编码是没有用的,例如,用基因型中的两个位表示每个表型位,其中 00 和 01 映射到 0,而 10 和 11 映射到1.
数学代写|优化算法作业代写optimisation algorithms代考|Summary
与对优化算法总是不利的坚固性不同,中立性具有可能进一步阻碍寻找良好解决方案的过程的方面。一般来说,我们可以说中立度ν非常接近随机游走的 1 退化优化过程。某些形式的中性网络[14,15,27,105,208,222,223,237]伴随着低(非零)值ν可以提高可演化性,从而增加找到好的解决方案的机会。
不利形式的中立通常是由搜索空间或基因型-表型映射的不良设计引起的。应尽可能避免基因组中的统一冗余,并且通常应限制搜索空间中的中性量。
数学代写|优化算法作业代写optimisation algorithms代考|Epistasis
在生物学中,上位性被定义为不同基因之间相互作用的一种形式[163]。该术语由 Bateson [16] 创造,最初意味着一个基因抑制另一个基因的表型表达。在统计遗传学的背景下,上位性最初被 Fisher [74] 称为“上位性”。根据 Lush [132],如果改变一个基因对适应度的影响取决于其他基因的等位基因状态,则基因之间的相互作用是上位性的。这种对上位性的理解非常接近另一种生物学
表达:多效性,这意味着单个基因影响多个表型特征[239]。在全局优化中,通常不会进行这种细粒度的区分,并且这两个术语通常或多或少地用作同义词。
定义 3(上位性)。在优化中,上位性是一个基因对目标函数值的贡献对其他基因的等位基因状态的依赖性[4,51,153].
当每个基因都独立于其他基因时,我们说的是最小的上位性。然后,优化过程等于为每个基因找到最佳值,并且可以通过简单的贪心搜索最有效地执行 [51]。当没有适当的基因子集独立于任何其他基因时,问题是最大上位性的[205,153]. 高度上位性问题的例子是考夫曼的 NK 适应度景观[113,115], p-Spin 模型[6],以及 Weise 等人 [232] 的可调模型。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。