如果你也在 怎样代写tensorflow这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
TensorFlow是一个用于机器学习和人工智能的免费和开源的软件库。它可以用于一系列的任务,但特别关注深度神经网络的训练和推理。
statistics-lab™ 为您的留学生涯保驾护航 在代写tensorflow方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写tensorflow代写方面经验极为丰富,各种代写tensorflow相关的作业也就用不着说。
我们提供的tensorflow及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
机器学习代写|tensorflow代写|Understanding code as a graph
Consider a doctor who predicts the expected weight of a newborn to be $7.5$ pounds. You’d like to figure out how that prediction differs from the actual measured weight. Being an overly analytical engineer, you design a function to describe the likelihood of all possible weights of the newborn. A weight of 8 pounds is more likely than 10 pounds, for example.
You can choose to use the Gaussian (otherwise known as normal) probability distribution function. This function takes a number as input and outputs a non-negative number describing the probability of observing the input. This function shows up all the time in machine learning and is easy to define in TensorFlow. It uses multiplication, division, negation, and a couple of other fundamental operators.
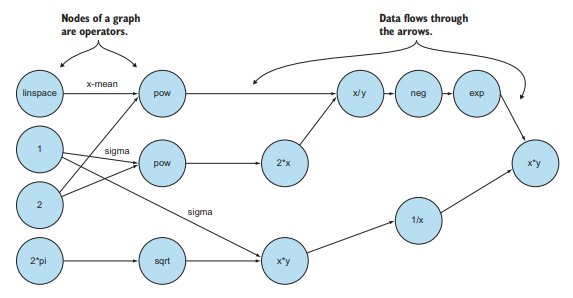
Think of every operator as being a node in a graph. Whenever you see a plus symbol (+) or any mathematical concept, picture it as one of many nodes. The edges between these nodes represent the composition of mathematical functions. Specifically, the negative operator we’ve been studying is a node, and the incoming/outgoing edges of this node are how the Tensor transforms. A tensor flows through the graph, which is why this library is called TensorFlow.
Here’s a thought: every operator is a strongly typed function that takes input tensors of a dimension and produces output of the same dimension. Figure $2.3$ is an example of how the Gaussian function can be designed with TensorFlow. The function is represented as a graph in which operators are nodes and edges represent interactions between nodes. This graph as a whole represents a complicated mathematical function (specifically, the Gaussian function). Small segments of the graph represent simple mathematical concepts, such as negation and doubling.
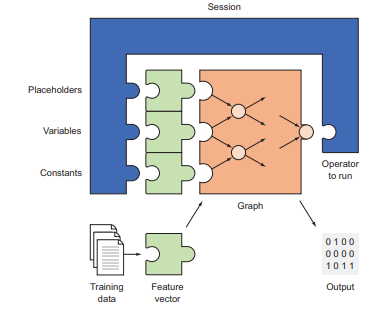
TensorFlow algorithms are easy to visualize. They can be described simply by flowcharts. The technical (and more correct) term for such a flowchart is a dataflow graph. Every arrow in a dataflow graph is called an edge. In addition, every state of the dataflow graph is called a node. The purpose of the session is to interpret your Python code into a dataflow graph and then associate the computation of each node of the graph to the CPU or GPU.
机器学习代写|tensorflow代写|Setting session configurations
You can also pass options to tf.Session. TensorFlow automatically determines the best way to assign a GPU or CPU device to an operation, for example, depending on what’s available. You can pass an additional option, log_device_placement=True, when creating a session. Listing $2.7$ shows you exactly where on your hardware the computations are evoked.
import tensorflow as tf
options = tf.RunOptions (output partition_graphs=True)
metadata = tf.RunMetadata ( )
result = sess . run (negMatrix, options=options, run_metadata=metadata) \& _ Prints the resulting value
print (result) print (metadata.partition_graphs)
This code outputs info about which CPU/GPU devices are used in the session for each operation. Running listing $2.7$ results in traces of output like the following to show which device was used to run the negation op:
Neg:/job:localhost/replica:0/task:0/cpu:0
Sessions are essential in TensorFlow code. You need to call a session to “run” the math. Figure $2.4$ maps out how the components on TensorFlow interact with the machinelearning pipeline. A session not only runs a graph operation, but also can take placeholders, variables, and constants as input. We’ve used constants so far, but in later sections, we’ll start using variables and placeholders. Here’s a quick overview of these three types of values:
- Placeholder-A value that’s unassigned but will be initialized by the session wherever it’s run. Typically, placeholders are the input and output of your model.
- Variable-A value that can change, such as parameters of a machine-learning model. Variables must be initialized by the session before they’re used.
- Constant-A value that doesn’t change, such as a hyperparameter or setting.
The entire pipeline for machine learning with TensorFlow follows the flow of figure 2.4. Most of the code in TensorFlow consists of setting up the graph and session. After you design a graph and hook up the session to execute it, your code is ready to use.
机器学习代写|tensorflow代写|Writing code in Jupyter
Because TensorFlow is primarily a Python library, you should make full use of Python’s interpreter. Jupyter is a mature environment for exercising the interactive nature of the language. It’s a web application that displays computation elegantly so that you can share annotated interactive algorithms with others to teach a technique or demonstrate code. Jupyter also easily integrates with visualization libraries like Python’s Matplotlib and can be used to share elegant data stories about your algorithm, to evaluate its accuracy, and to present results.
You can share your Jupyter notebooks with other people to exchange ideas, and you can download their notebooks to learn about their code. See the appendix to get started installing the Jupyter Notebook application.
From a new terminal, change the directory to the location where you want to practice TensorFlow code, and start a notebook server:
\$cd -/MyTensorFlowStuff
$\$$ jupyter notebook
Running this command should launch a new browser window with the Jupyter notebook’s dashboard. If no window opens automatically, you can navigate to http://localhost:8888 from any browser. You’ll see a web page similar to the one in figure $2.5$.
TIP The jupyter notebook command didn’t work? Make sure that your PYTHONPATH environment variable includes the path to the jupyter script created when you installed the library. Also, this book uses both Python $3.7$ (recommended) and Python $2.7$ examples (due to the BregmanToolkit, which you’ll read about in chapter 7). For this reason, you will want to install Jupyter with Python kernels enabled. For more information, see https://ipython readthedocs.io/en/stable/install/kernel_install.html.
tensorflow代考
机器学习代写|tensorflow代写|Understanding code as a graph
考虑一位医生预测新生儿的预期体重为7.5磅。您想弄清楚该预测与实际测量的重量有何不同。作为一名过度分析的工程师,您设计了一个函数来描述新生儿所有可能体重的可能性。例如,8 磅的重量比 10 磅更有可能。
您可以选择使用高斯(也称为正态)概率分布函数。此函数将一个数字作为输入,并输出一个描述观察输入的概率的非负数。这个函数在机器学习中一直出现,并且在 TensorFlow 中很容易定义。它使用乘法、除法、否定和其他一些基本运算符。
将每个运算符视为图中的一个节点。每当您看到加号 (+) 或任何数学概念时,将其想象为许多节点之一。这些节点之间的边代表数学函数的组成。具体来说,我们一直在研究的负算子是一个节点,这个节点的入/出边就是 Tensor 的变换方式。一个张量流过图,这就是为什么这个库被称为 TensorFlow。
这里有一个想法:每个运算符都是一个强类型函数,它接受一个维度的输入张量并产生相同维度的输出。数字2.3是如何使用 TensorFlow 设计高斯函数的示例。该函数表示为一个图,其中算子是节点,边表示节点之间的交互。该图作为一个整体表示一个复杂的数学函数(特别是高斯函数)。图中的小段代表简单的数学概念,例如否定和加倍。
TensorFlow 算法易于可视化。它们可以简单地用流程图来描述。这种流程图的技术(更正确)术语是数据流图。数据流图中的每个箭头都称为边。此外,数据流图的每个状态都称为一个节点。会话的目的是将您的 Python 代码解释为数据流图,然后将图的每个节点的计算与 CPU 或 GPU 相关联。
机器学习代写|tensorflow代写|Setting session configurations
您还可以将选项传递给 tf.Session。TensorFlow 会自动确定将 GPU 或 CPU 设备分配给操作的最佳方式,例如,取决于可用的设备。您可以在创建会话时传递一个附加选项 log_device_placement=True。清单2.7向您准确显示在硬件上引发计算的位置。
将 tensorflow 导入为 tf
options = tf.RunOptions (output partition_graphs=True)
metadata = tf.RunMetadata ()
result = sess 。run (negMatrix, options=options, run_metadata=metadata) \& _ 打印结果值
print (result) print (metadata.partition_graphs)
此代码输出有关每个操作的会话中使用哪些 CPU/GPU 设备的信息。运行列表2.7产生如下输出痕迹,以显示用于运行否定操作的设备:
Neg:/job:localhost/replica:0/task:0/cpu:0
会话在 TensorFlow 代码中是必不可少的。你需要调用一个会话来“运行”数学。数字2.4绘制出 TensorFlow 上的组件如何与机器学习管道交互。会话不仅运行图形操作,还可以将占位符、变量和常量作为输入。到目前为止,我们已经使用了常量,但在后面的部分中,我们将开始使用变量和占位符。以下是这三种类型值的快速概览:
- 占位符 – 一个未分配的值,但无论在何处运行,会话都会对其进行初始化。通常,占位符是模型的输入和输出。
- 变量 – 可以更改的值,例如机器学习模型的参数。变量在使用之前必须由会话初始化。
- 常量 – 不会改变的值,例如超参数或设置。
使用 TensorFlow 进行机器学习的整个管道遵循图 2.4 的流程。TensorFlow 中的大部分代码都包括设置图和会话。设计图表并连接会话以执行它之后,您的代码就可以使用了。
机器学习代写|tensorflow代写|Writing code in Jupyter
因为 TensorFlow 主要是一个 Python 库,所以你应该充分利用 Python 的解释器。Jupyter 是一个成熟的环境,用于锻炼语言的交互性。它是一个优雅地显示计算的 Web 应用程序,因此您可以与他人共享带注释的交互式算法来教授技术或演示代码。Jupyter 还可以轻松地与 Python 的 Matplotlib 等可视化库集成,并可用于分享有关您的算法的优雅数据故事、评估其准确性并呈现结果。
您可以与其他人共享您的 Jupyter 笔记本以交流想法,也可以下载他们的笔记本以了解他们的代码。请参阅附录以开始安装 Jupyter Notebook 应用程序。
在新终端中,将目录更改为您要练习 TensorFlow 代码的位置,然后启动笔记本服务器:
$ cd -/MyTensorFlowStuff
$jupyter notebook
运行这个命令应该会启动一个带有 Jupyter notebook 仪表板的新浏览器窗口。如果没有自动打开窗口,您可以从任何浏览器导航到 http://localhost:8888。你会看到一个类似于图中的网页2.5.
提示 jupyter notebook 命令不起作用?确保您的 PYTHONPATH 环境变量包含安装库时创建的 jupyter 脚本的路径。此外,本书同时使用 Python3.7(推荐)和 Python2.7示例(由于 BregmanToolkit,您将在第 7 章中了解它)。出于这个原因,您需要在启用 Python 内核的情况下安装 Jupyter。有关更多信息,请参阅 https://ipython readthedocs.io/en/stable/install/kernel_install.html。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。