如果你也在 怎样代写化学计量学chemometrics这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
化学计量学是一门化学学科,它使用数学、统计学和其他采用形式逻辑的方法来设计或选择最佳的测量程序和实验,并通过分析化学数据来提供最大的相关化学信息。
将化学计量学方法与经典方法相比较,也许可以最好地理解它的特点。经典方法旨在理解效应–哪些因素是主要的,哪些因素是可以忽略的–而化学计量学方法则放弃了理解效应的必要性,并指出了其他目标,如预测、模式识别、分类等。
statistics-lab™ 为您的留学生涯保驾护航 在代写化学计量学chemometrics方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写化学计量学chemometrics代写方面经验极为丰富,各种代写化学计量学chemometrics相关的作业也就用不着说。
我们提供的化学计量学chemometrics及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|化学计量学作业代写chemometrics代考|Parametric Time Warping
In PTW, one approximates the time axis of the reference signal by applying a polynomial transformation of the time axis of the sample (Eilers 2004):
$$
\hat{S}\left(t_{k}\right)=S\left(w\left(t_{k}\right)\right)
$$
where $\hat{S}\left(t_{k}\right)$ is the value of the warped signal at time point $t_{k}$, where $k$ is an index. The warping function, $w$, is given by:
$$
w(t)=\sum_{j=0}^{J} a_{j} t^{j}
$$
with $J$ the maximal order of the polynomial. In general, only low-order polynomials are used. Since neighboring points on the time axis will be warped with almost the same amount, peak shape distortions are limited. Thus, the method finds the set of coefficients $a_{0}, \ldots, a_{J}$ that minimizes the difference between the sample $S$ and reference $R$, using whatever difference measure is desired. Especially for higher-degree warpings there is a real possibility that the optimization ends in a local optimum, and it is usually a good idea to use several different starting values.
This procedure is very suitable for modelling gradual changes, such as the slow deterioration of chromatographic columns, so that measurements taken days or weeks apart can still be made comparable. For situations where a few individual peak shifts have to be corrected (e.g., pH-dependent shifting of patterns in NMR spectra), the technique is less ideal (Giskeødegård et al. 2010).
The original implementation of ptw (corresponding to function argument mode = “backward”) predicts, for position $i$, which point $j$ in the signal will end up at position $i$. This is somewhat counterintuitive, and in later versions (from version $1.9 .1$ onwards) the default mode is “forward”, basically predicting the position of point $i$ after warping. The interpretation of the coefficients in the two modes is the same, just with reversed signs.
统计代写|化学计量学作业代写chemometrics代考|Dynamic Time Warping
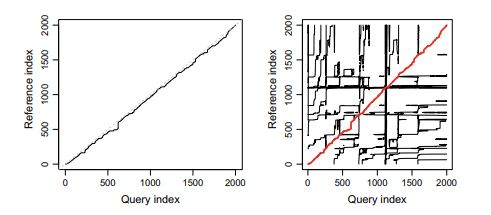
Dynamic Time Warping (DTW), implemented in package dtw (Giorgino 2009), provides a similar approach, constructing a warping function that provides a mapping from the indices in the query signal to the points in the reference signal ${ }^{1}$ :
$>$ warpfun. dtw <- dtw (ssamp, sref)
plot (warpfun. dtw)
$>$ abline ${0,1$, col $=$ “gray”, lty $=2}$
The result is shown in the left plot of Fig.3.11. Here, the warping function is not restricted to be a polynomial, as in PTW.
A horizontal segment indicates that several points in the query signal are mapped to the same point in the reference signal; the axis of the query signal is compressed by elimination (or rather, averaging) of points. Similarly, vertical segments indicate a stretching of the query signal axis by the duplication of points. Note that these horizontal and vertical regions in the warping function of Fig.3.11 may also lead to peak shape distortions.
DTW chooses the warping function that minimizes the (weighted) distance between the warped signals.
统计代写|化学计量学作业代写chemometrics代考|Practicalities
In almost all cases, a set of signals should be aligned in such a way that all features of interest are at the same positions in every trace. One strategy is to use the column means of the data matrix as a reference. This is only possible with very small shifts and will lead to peak broadening. Simply taking a random record from the set as a reference is better but still may be improved upon-it usually pays to perform some experiments to see which reference would lead to the smallest distortion of the other signals, while still leading to good alignment. If the number of samples is not too large, one can perform all possible combinations and see which one comes out best. Careful data pretreatment is essential-baselines may severely influence the results and should be removed before alignment. In fact, one of the motivations of the CODA algorithm is to select traces that do not contain a baseline (Windig et al. 1996). Another point of attention is the fact that features can have intensities differing several orders in magnitude. Often, the biggest gain in the alignment optimization is achieved by getting the prominent features in the right location. Sometimes, this dominance leads to suboptimal alignments. Also differences in intensity between sample and reference signals can distort the results. Methods to cope with these phenomena will be treated in Sect. 3.5. Finally, it has been shown that in some cases results can be improved when the signals are divided into segments which are aligned individually (Wang and Isenhour 1987). Especially with more constrained warping methods like PTW this adds flexibility, but again, there is a danger of warping too much and mapping features onto the wrong locations. Especially in cases where there may be differences between the samples (control versus diseased, for instance) there is a risk that a biomarker peak, present only in one of the two classes, is incorrectly aligned. This, again, is all the more probable when that particular peak has a high intensity.
Packages dtw and ptw are by no means alone in tackling alignment. We already mentioned the VPdtw package: in addition, several Bioconductor packages, such as PROcess and xcms, implement both general and more specific alignment procedures, in most cases for mass-spectrometry data or hyphenated techniques like LC-MS.
化学计量学代写
统计代写|化学计量学作业代写chemometrics代考|Parametric Time Warping
在 PTW 中,通过应用样本时间轴的多项式变换来近似参考信号的时间轴(Eilers 2004):
小号^(吨ķ)=小号(在(吨ķ))
在哪里小号^(吨ķ)是时间点处扭曲信号的值吨ķ, 在哪里ķ是一个索引。翘曲函数,在, 是(谁)给的:
在(吨)=∑j=0Ĵ一种j吨j
和Ĵ多项式的最大阶数。通常,仅使用低阶多项式。由于时间轴上的相邻点将以几乎相同的量扭曲,因此峰形失真是有限的。因此,该方法找到系数集一种0,…,一种Ĵ最小化样本之间的差异小号和参考R,使用所需的任何差异度量。尤其是对于更高程度的扭曲,优化很有可能以局部最优结束,并且使用几个不同的起始值通常是一个好主意。
此过程非常适合模拟渐变的变化,例如色谱柱的缓慢劣化,因此间隔数天或数周的测量仍然可以进行比较。对于必须校正几个单独的峰位移的情况(例如,NMR 光谱中的 pH 依赖性模式位移),该技术不太理想(Giskeødegård 等人,2010 年)。
ptw 的原始实现(对应于函数参数 mode = “backward”)预测,对于位置一世, 哪一点j在信号将结束在位置一世. 这有点违反直觉,在以后的版本中(来自版本1.9.1onwards) 默认模式是“forward”,基本上是预测点的位置一世翘曲后。两种模式中系数的解释是相同的,只是符号相反。
统计代写|化学计量学作业代写chemometrics代考|Dynamic Time Warping
在包 dtw (Giorgino 2009) 中实现的动态时间规整 (DTW) 提供了类似的方法,构建了一个规整函数,该函数提供从查询信号中的索引到参考信号中的点的映射1 :
>经趣。dtw <- dtw(ssamp, sref)
情节(warpfun.dtw)
>下线0,1$,C这l$=$“Gr一种是”,l吨是$=2
结果如图 3.11 的左图所示。这里,翘曲函数不限于是多项式,如在 PTW 中。
水平线段表示查询信号中的几个点映射到参考信号中的同一点;查询信号的轴通过消除(或者更确切地说,平均)点来压缩。类似地,垂直线段通过点的重复表示查询信号轴的延伸。请注意,图 3.11 的翘曲函数中的这些水平和垂直区域也可能导致峰形失真。
DTW 选择最小化扭曲信号之间(加权)距离的扭曲函数。
统计代写|化学计量学作业代写chemometrics代考|Practicalities
在几乎所有情况下,一组信号都应该以这样一种方式对齐,即所有感兴趣的特征在每条迹线中都位于相同的位置。一种策略是使用数据矩阵的列均值作为参考。这只有在非常小的变化下才有可能,并且会导致峰展宽。简单地从集合中获取一个随机记录作为参考更好,但仍然可以改进——通常需要进行一些实验,看看哪个参考会导致其他信号的最小失真,同时仍然会导致良好的对齐。如果样本的数量不太大,可以执行所有可能的组合,看看哪一种效果最好。仔细的数据预处理是必不可少的 – 基线可能会严重影响结果,应在对齐之前删除。实际上,CODA 算法的动机之一是选择不包含基线的轨迹(Windig et al. 1996)。另一个值得注意的事实是,特征的强度可以有几个数量级的不同。通常,对齐优化的最大收获是通过在正确的位置获得突出的特征来实现的。有时,这种优势会导致次优对齐。此外,样品和参考信号之间的强度差异也会使结果失真。处理这些现象的方法将在 Sect. 3.5. 最后,已经表明,在某些情况下,当信号被分成单独对齐的段时,结果可以得到改善(Wang 和 Isenhour 1987)。尤其是像 PTW 这样的更受约束的变形方法,这增加了灵活性,但同样,存在过度扭曲并将特征映射到错误位置的危险。特别是在样本之间可能存在差异的情况下(例如,对照与患病),存在仅存在于两个类别之一中的生物标志物峰被错误对齐的风险。同样,当该特定峰具有高强度时,这种情况更有可能发生。
包 dtw 和 ptw 绝不是单独处理对齐问题。我们已经提到了 VPdtw 包:此外,一些 Bioconductor 包,例如 PROcess 和 xcms,实现了通用和更具体的对齐程序,在大多数情况下用于质谱数据或 LC-MS 等连字符技术。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。