如果你也在 怎样代写数据可视化Data visualization这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
数据可视化是将信息转化为视觉背景的做法,如地图或图表,使数据更容易被人脑理解并从中获得洞察力。数据可视化的主要目标是使其更容易在大型数据集中识别模式、趋势和异常值。
statistics-lab™ 为您的留学生涯保驾护航 在代写数据可视化Data visualization方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写数据可视化Data visualization代写方面经验极为丰富,各种代写数据可视化Data visualization相关的作业也就用不着说。
我们提供的数据可视化Data visualization及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|数据可视化代写Data visualization代考|Trying to Display Too Much Information
Another common mistake in building effective charts is trying to convey too much information on a single chart, which is a symptom of trying to communicate too many insights to the audience simultaneously.
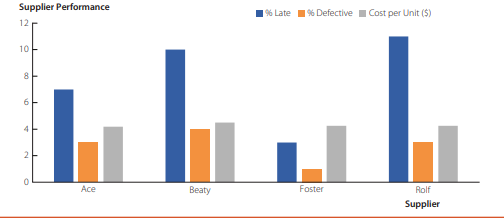
Consider the case of Keeland Industries, an online company that provides replacement parts for automobiles. It provides both original-equipment manufacturer (OEM) replacement parts and replacement parts made by different manufacturers that are known as aftermarket replacement parts. Because Keeland sells the replacement parts online, it sells parts to customers throughout the United States. For sales tracking and performance measurement purposes, Keeland divides the United States into 12 regions. Keeland’s management team is most interested in comparing the OEM sales across the 12 regions to see which are performing best for OEM sales and in comparing the Aftermarket sales across the 12 regions to see which are performing best for Aftermarket sales.
Figure $3.30$ displays the OEM and Aftermarket sales by region as a clustered column chart. The clustered column chart makes it easy to compare OEM sales to Aftermarket
sales in each region. However, if the potential markets for these different types of parts are different in each region, that comparison is not particularly useful.
Figure $3.31$ displays the OEM and Aftermarket sales by region as a stacked column chart. The stacked column chart makes it much easier to compare the total sales in the different regions. Therefore, a stacked column chart would be a good choice if the goal is to compare total sales (OEM plus Aftermarket) among the 12 regions. However, the stated goal of this visualization is to compare the OEM sales across regions separately from the Aftermarket sales. The best visualization to accomplish the stated goal is to use two separate column charts as shown in Figures $3.32$ and $3.33$.
统计代写|数据可视化代写Data visualization代考|Using Excel Default Settings for Charts
Microsoft Excel allows for the creation of a variety of charts and tables to visualize data. However, a common mistake is to use the default output from Excel without considering changes to the design and format of the visualizations it produces. Excel’s default settings are counter to many of the suggestions covered in this chapter (and the rest of this textbook) for creating good data visualizations. Consider Figure $3.34$. This column chart, which was produced using Excel, shows revenues for eight retail store locations in Texas. The company is interested in comparing revenues by location, and specifically in examining the relative performance of the store located in Laredo because this store has recently had a change in management.
Figure $3.34$ suffers from several flaws that prevent it from being an effective data isualization. The data-ink ratio for Figure $3.34$ is low, so we should consider ways of lecluttering the figure. Examining Figure $3.34$ shows that the chart uses ink in several Nays that are not useful in conveying the data. The gridlines used in this chart are not barticularly useful, so they can be removed. We see that Excel automatically titles the chart “Annual Revenue” and uses a legend with “Annual Revenue.” This is redundant nformation, and at least one of these labels should be removed. The following steps can be used to declutter the default chart produced by Excel, increase the data-ink atio, and make the chart more meaningful to the audience.
Step 1. Click anywhere on the chart in the file RetailRevenueChart
Step 2. Click the Chart Elements button $+$
Deselect the check box for Gridlines
Deselect the check box for Legend
Steps 1 and 2 increase the data-ink ratio by decluttering the chart. We can further mprove this chart by adding meaningful ink to the chart and making a few other modfications. For example, the revenue values shown in this chart are from the previous year and are in $1000 \mathrm{~s}$ of dollars. None of this is clear from the chart. To make it easier or the audience to compare the relative amounts of annual revenue by location, we can sort the columns in decreasing order. Finally, because the audience is particularly nterested in annual sales at the Laredo location, we can change the color of the colImn associated with Laredo to draw the audience’s attention to that part of the chart. The following steps create the finished column chart shown in Figure 3.35.
统计代写|数据可视化代写Data visualization代考|Too Many Attributes
In Section 3-1, we discuss the importance of using preattentive attributes in data visualizations to make them easy to understand by the audience. However, using too many preattentive attributes in the same visualization can cause confusion for the audience. Consider again the case of Stanley Consulting Group. The company wants to examine how consultant characteristics such as job title, length of time with the company, and highest educational degree attained are related to the amount of billable hours filed by that consultant. Figure $3.36$ attempts to show this information.
All of the information the company wants to consider is shown in Figure 3.36: the number of billable hours for each consultant (on the vertical axis), the length of time at the company (on the horizontal axis), the consultant’s job title (indicated by the color of the marker in the chart), and the highest degree attained by the consultant (indicated by the shape of the marker in the chart). Figure $3.36$ uses several preattentive attributes from Section 3-1 including spatial positioning, shape, and color. However, because we are using many different preattentive attributes, this chart is difficult for an audience to process. It requires the audience to scan back and forth between the markers in the chart, the legends, and the vertical and horizontal axes. Therefore, this is probably not a particularly useful chart.
A better chart than what is shown in Figure $3.36$ would concentrate on examining fewer relationships and using fewer preattentive attributes. The exact choice of which features to show on the chart depends on the goals of the chart and needs of the audience. If it is more important to examine the relationship between billable hours, length of time at the company, and the job title of the consultant, then a chart such as the one shown in Figure $3.37$ is preferred.
数据可视化代考
统计代写|数据可视化代写Data visualization代考|Trying to Display Too Much Information
建立有效图表的另一个常见错误是试图在单个图表上传达太多信息,这是试图同时向观众传达太多见解的症状。
以 Keeland Industries 为例,这是一家为汽车提供替换零件的在线公司。它提供原始设备制造商 (OEM) 替换零件和由不同制造商制造的替换零件,称为售后替换零件。由于 Keeland 在线销售替换零件,因此它向美国各地的客户销售零件。出于销售跟踪和绩效衡量的目的,Keeland 将美国划分为 12 个地区。Keeland 的管理团队最感兴趣的是比较 12 个地区的 OEM 销售情况,看看哪些地区的 OEM 销售表现最好,并比较 12 个地区的售后市场销售情况,看看哪些地区的售后市场销售表现最好。
数字3.30将按地区划分的 OEM 和售后市场销售额显示为簇状柱形图。簇状柱形图可轻松将 OEM 销售与售后市场进行比较
每个地区的销售额。但是,如果这些不同类型零件的潜在市场在每个地区都不同,那么这种比较就不是特别有用。
数字3.31将按地区划分的 OEM 和售后市场销售额显示为堆积柱形图。堆积柱形图使比较不同地区的总销售额变得更加容易。因此,如果目标是比较 12 个地区的总销售额(OEM 加售后市场),堆叠柱形图将是一个不错的选择。但是,此可视化的既定目标是将跨区域的 OEM 销售与售后市场销售分开进行比较。实现既定目标的最佳可视化是使用两个单独的柱形图,如图所示3.32和3.33.
统计代写|数据可视化代写Data visualization代考|Using Excel Default Settings for Charts
Microsoft Excel 允许创建各种图表和表格来可视化数据。但是,一个常见的错误是使用 Excel 的默认输出,而不考虑对其生成的可视化的设计和格式进行更改。Excel 的默认设置与本章(以及本教科书的其余部分)中关于创建良好数据可视化的许多建议背道而驰。考虑图3.34. 这个使用 Excel 生成的柱形图显示了德克萨斯州八个零售店位置的收入。该公司有兴趣按位置比较收入,特别是检查位于拉雷多的商店的相对业绩,因为这家商店最近发生了管理层变动。
数字3.34存在一些缺陷,使其无法成为有效的数据异构化。图的数据墨水比3.34低,所以我们应该考虑使数字变得混乱的方法。检查图3.34显示图表使用了几种对传达数据无用的墨水。此图表中使用的网格线并不是特别有用,因此可以将其删除。我们看到 Excel 自动将图表命名为“年收入”,并使用带有“年收入”的图例。这是多余的信息,至少应该删除这些标签中的一个。以下步骤可用于整理 Excel 生成的默认图表,增加数据墨水比例,并使图表对观众更有意义。
步骤 1. 单击文件 RetailRevenueChart 图表上的任意位置
步骤 2. 单击图表元素按钮+
取消选中 Gridlines 复选框
取消选中 Legend
Steps 1 和 2 复选框,通过整理图表来增加数据墨水比率。我们可以通过在图表中添加有意义的墨水并进行一些其他修改来进一步改进此图表。例如,此图表中显示的收入值来自上一年,并且在1000 s美元。从图表上看,这些都不是很清楚。为了让观众更容易按位置比较年收入的相对金额,我们可以按降序对列进行排序。最后,由于观众对拉雷多位置的年销售额特别感兴趣,我们可以更改与拉雷多相关的柱的颜色,以将观众的注意力吸引到图表的那部分。以下步骤创建完成的柱形图,如图 3.35 所示。
统计代写|数据可视化代写Data visualization代考|Too Many Attributes
在第 3-1 节中,我们讨论了在数据可视化中使用 preattentive 属性以使其易于被观众理解的重要性。但是,在同一个可视化中使用过多的 preattentive 属性可能会导致观众混淆。再次考虑斯坦利咨询集团的案例。公司想要检查顾问特征(例如职位、在公司工作的时间长度和获得的最高教育程度)与该顾问提交的计费小时数之间的关系。数字3.36试图显示此信息。
公司想要考虑的所有信息如图 3.36 所示:每位顾问的计费小时数(纵轴)、在公司的时间长度(横轴)、顾问的职位(标由图表中标记的颜色)和顾问达到的最高程度(由图表中标记的形状表示)。数字3.36使用第 3-1 节中的几个 preattentive 属性,包括空间定位、形状和颜色。但是,由于我们使用了许多不同的预注意属性,因此该图表很难让观众处理。它要求观众在图表中的标记、图例以及垂直和水平轴之间来回扫描。因此,这可能不是一个特别有用的图表。
比图中显示的更好的图表3.36将专注于检查更少的关系并使用更少的前注意属性。在图表上显示哪些功能的确切选择取决于图表的目标和观众的需求。如果更重要的是检查计费时间、公司工作时间和顾问职位之间的关系,那么如图所示的图表3.37是首选。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。