如果你也在 怎样代写贝叶斯分析Bayesian Analysis这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
贝叶斯分析,一种统计推断方法(以英国数学家托马斯-贝叶斯命名),允许人们将关于人口参数的先验信息与样本所含信息的证据相结合,以指导统计推断过程。
statistics-lab™ 为您的留学生涯保驾护航 在代写贝叶斯分析Bayesian Analysis方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写贝叶斯分析Bayesian Analysis代写方面经验极为丰富,各种代写贝叶斯分析Bayesian Analysis相关的作业也就用不着说。
我们提供的贝叶斯分析Bayesian Analysis及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|贝叶斯分析代写Bayesian Analysis代考|Patterns and Randomness: From School League Tables to Siegfried and Roy
Take a look at Table 2.3. It shows the scores achieved (on an objective quality criteria) by the set of state schools in one council district in the UK. We have made the schools anonymous by using numbers rather than names. School 38 achieved a significantly higher score than the next best school, and its score (175) is over $52 \%$ higher than the lowest ranked school, number 41 (score 115). Tables like these are very important in the UK, since they are supposed to help provide informed “choice” for parents. Based on the impressive results of School 38 parents clamour to ensure that their child gets a place at this school. Not surprisingly, it is massively oversubscribed. Since these are the only available state schools in this district, imagine how you would feel if, instead of your child being awarded a place in School 38, he or she was being sent to school 41 . You would be pretty upset, wouldn’t you?
You should not be. We lied. The numbers do not represent schools at all. They are simply the numbers used in the UK National Lottery ( 1 to 49). And each “score” is the actual number of times that particular numbered ball had been drawn in the first 1,172 draws of the UK National Lottery. So the real question is: Do you believe that 38 is a “better” number than 41 ? Or, making the analogy with the school league table more accurate:
Do you believe the number 38 is more likely to be drawn next time than the number 41 ? (Since thé üsuall interpretatiòn of the schoool léaguee tablé is that if your child attends the school at the top he or she will get better grades than if he or she attends the school at the bottom.)
The fact is that the scores are genuinely random. Although the “expected” number of times any one ball should have been drawn is about 144 you can see that there is a wide variation above and below this number (even though that is still the average score).
What many people fail to realise is that this kind of variation is inevitable. It turns out that in any sequence of 1,172 lottery draws there is about a $50 \%$ chance that at least half the numbers will be chosen either less than 136 times or more than 152 times. That indeed is roughly what happened in the real sample. Moreover, the probability that at least one number will be chosen more than 171 times is about $45 \%$. You may find it easier to think of rolling a die 60 times. You would almost certainly not get each of the six numbers coming up 10 times. You might get 16 threes and only 6 fours. That does that not make the number three “better” than the number four. The more times you roll the die, the closer in relative terms will be the frequencies of each number (specifically, if you roll the die $n$ times the frequency of each number will get closer to $n$ divided by 6 as $n$ gets bigger); but in absolute terms the frequencies will not be exactly the same. There will inevitably be some numbers with a higher count than others. And one number will be at the “top” of the table while another will be “bottom.”
统计代写|贝叶斯分析代写Bayesian Analysis代考|Why You Should Be Very Wary of Correlations and Their Significance Values
The close “correlation” between per capita cheese consumption and number of people who died by becoming tangled in their bedsheets in the United States, as shown in Figure 2.12, is one of many spurious correlations published on the website http://tylervigen.com.
Correlations and significance values (also called p-values) are the standard techniques that statisticians use to determine whether there are genuine relationships between different variables. In the approach to probability that we espouse in this book these traditional techniques (along with their first-cousins regression analysis and confidence intervals, which we will look at in Chapter 12 ) are superseded by techniques that we feel are simpler and more intuitive. But the acceptance and entrenchment of these ideas are so widespread across all empirical disciplines that you need to be aware of what they are in order to appreciate the damage they can do to rational decision making and risk analysis.
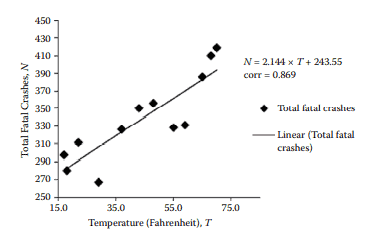
Look at Table 2.6. This gives (a) the average temperature and (b) the number of automobile crashes resulting in fatalities in the United States in 2008 broken down by month (source: U.S. Department of Transport 2008). We can plot this data in a scatterplot graph as shown in Figure 2.13.
From a quick view of the chart there is a relationship between temperature and fatalities. There seem to be more fatalities as the temperature increases. Statisticians use a formula-called the correlation coefficient (see Box 2.3) – that measures the extent to which the two sets of numbers are related. You do not need to know what this formula is because any spreadsheet package like Excel will do the calculation for you. It so happens that the correlation coefficient in this case is approximately $0.869$. Ilsing standard tahles this turns nut to he “highly significant” (comfortably passing the criteria for a $p$-value of $0.01$ that is also explained in Box $2.3$ ). Statisticians would normally conclude from this data that the number of road fatalities and the minimum temperature on any given day are significantly related (although note that we have severe concerns about the limitations of $p$-values as explained in Box 2.3).
贝叶斯分析代考
统计代写|贝叶斯分析代写Bayesian Analysis代考|Patterns and Randomness: From School League Tables to Siegfried and Roy
请看表 2.3。它显示了英国一个议会区的一组公立学校(根据客观质量标准)取得的分数。我们通过使用数字而不是名称使学校匿名。学校 38 的分数明显高于第二名的学校,其分数(175)超过52%高于排名最低的学校,第 41 名(分数 115)。像这样的表格在英国非常重要,因为它们应该有助于为父母提供知情的“选择”。基于 School 38 令人印象深刻的成绩,家长们大声疾呼要确保他们的孩子在这所学校获得一席之地。毫不奇怪,它被大量超额认购。由于这些是该地区唯一可用的公立学校,想象一下,如果您的孩子没有被授予 38 学校的一席之地,而是被送到 41 学校,您会有什么感受。你会很沮丧,不是吗?
你不应该。我们撒谎了。这些数字根本不代表学校。它们只是英国国家彩票中使用的数字(1 到 49)。每个“分数”是该特定编号的球在英国国家彩票的前 1,172 次抽签中被抽出的实际次数。所以真正的问题是:你认为 38 比 41 是一个“更好”的数字吗?或者,让与学校排名表的类比更准确:
你认为 38 号比 41 号更容易被抽中吗?(因为 schoool léaguee table 的一般解释是,如果您的孩子在排名靠前的学校上学,他或她会比在排名靠后的学校上学取得更好的成绩。)
事实上,分数是真正随机的。尽管任何一个球应该被抽出的“预期”次数大约是 144 次,但您可以看到在这个数字之上和之下存在很大差异(尽管这仍然是平均得分)。
许多人没有意识到的是,这种变化是不可避免的。事实证明,在 1,172 次抽奖的任何序列中,大约有50%至少有一半的数字将被选择少于 136 次或多于 152 次。这确实是真实样本中发生的大致情况。此外,至少一个数字被选择超过 171 次的概率约为45%. 您可能会发现掷骰子 60 次更容易。你几乎肯定不会让这六个数字中的每一个都出现 10 次。你可能会得到 16 个三分球,而只有 6 个四分球。这不会使第三名比第四名“更好”。你掷骰子的次数越多,相对而言,每个数字的频率就越接近(特别是,如果你掷骰子n每个数字的频率将接近n除以 6 为n变大);但从绝对意义上讲,频率不会完全相同。不可避免地会有一些数字比其他数字更高。一个数字将位于表格的“顶部”,而另一个数字将位于“底部”。
统计代写|贝叶斯分析代写Bayesian Analysis代考|Why You Should Be Very Wary of Correlations and Their Significance Values
如图 2.12 所示,美国人均奶酪消费量与因被床单缠在一起而死亡的人数之间的密切“相关性”是 http://tylervigen.com 网站上发布的众多虚假相关性之一.
相关性和显着性值(也称为 p 值)是统计学家用来确定不同变量之间是否存在真正关系的标准技术。在我们在本书中支持的概率方法中,这些传统技术(以及它们的第一代回归分析和置信区间,我们将在第 12 章中介绍)被我们认为更简单、更直观的技术所取代。但是这些想法的接受和巩固在所有经验学科中是如此普遍,以至于您需要了解它们是什么,以便了解它们对理性决策和风险分析可能造成的损害。
参见表 2.6。这给出了 (a) 平均温度和 (b) 2008 年美国按月划分的导致死亡的车祸数量(来源:美国交通部 2008)。我们可以在散点图中绘制这些数据,如图 2.13 所示。
从图表的快速查看来看,温度和死亡人数之间存在关系。随着气温升高,死亡人数似乎更多。统计学家使用一个称为相关系数的公式(见方框 2.3)——它衡量两组数字的相关程度。你不需要知道这个公式是什么,因为任何像 Excel 这样的电子表格包都会为你做计算。碰巧这种情况下的相关系数大约是0.869. Ilsing standard tahles 这让他“非常重要”(轻松地通过标准p-的价值0.01这也在 Box 中进行了解释2.3)。统计学家通常会从这些数据中得出结论,道路死亡人数和任何一天的最低气温显着相关(尽管请注意,我们对p-值,如方框 2.3 中所述)。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。