如果你也在 怎样代写Generalized linear model这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
广义线性模型(GLiM,或GLM)是John Nelder和Robert Wedderburn在1972年提出的一种高级统计建模技术。它是一个包括许多其他模型的总称,它允许响应变量y具有正态分布以外的误差分布。
statistics-lab™ 为您的留学生涯保驾护航 在代写Generalized linear model方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写Generalized linear model代写方面经验极为丰富,各种代写Generalized linear model相关的作业也就用不着说。
我们提供的Generalized linear model及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|Generalized linear model代考广义线性模型代写|Why Statistics Matters
Although many students would not choose to take a statistics course, nearly every social science department requires its students to take a statistics course (e.g., Norcross et al., 2016; Stoloff et al., 2010). Why? Apparently, the professors in these departments think that statistics is essential to their students’ education, despite what their students may think.
The main reason that many students must take statistics is that research in the social sciences is dominated by methodologies that are statistics-based; this family of methods is called quantitative research. Researchers who use quantitative research convert their data into numbers for the purpose of analysis, and the numbers are then analyzed by statistical methods. Numerical
data are so important that one social scientist even argued that “progress in science is impossible without numbers and measurement as words and rhetoric are not enough” (Bouchard, 2014, p. 569).
Quantitative methods – and therefore statistics – dominate most of the behavioral sciences: psychology, sociology, education, criminal justice, economics, political science, and more. Most researchers working in these fields use statistics to test new theories, evaluate the effectiveness of therapies, and learn about the concepts they study. Even workers who do not conduct research must understand statistics in order to understand how (and whether) to apply scientific knowledge in their daily work. Without statistics a practitioner risks wasting time and money by using ineffective products, therapies, or procedures. In some cases this could lead to violations of ethics codes, accusations of malpractice, lawsuits, and harm to clients or customers. Even students who do not become scientists may need statistics to verify whether an anecdotal observation (e.g., that their company sells more products after a local sports team wins a game than after a losing one) is true. Thus, a mastery of statistics is important to many people, not just researchers and social scientists.
There are four main ways that practitioners use statistics in their work in the social sciences:
- Separating good research from bad
- Evaluating the conclusions of researchers
- Communicating findings to others
- Interpreting research to create practical, real-world results.
There is some overlap among these four points, so some job tasks will fall into more than one category. Nevertheless, this is still a useful list of ways that professionals use statistics.
Separating good research from bad is important for any practitioner. The quality of the research published in scientific journals varies greatly. Some articles become classics and spark new avenues of research; others report shoddy research. Thus, the fact that a study was published in a scientific journal is not, by itself, evidence of good-quality scientific work. A knowledge of statistics is one of the most important tools that a person can have in distinguishing good research from bad. Having the ability to independently judge research prevents practitioners from being susceptible to fads in their field or from wasting resources on practices that provide few benefits.
The benefits of separating good research from bad research are important for the general public, too (not just practitioners). Most people rely on reports from the news media and the Internet to learn about scientific findings. However, most journalists are not trained scientists and do not have the skills needed to distinguish between a high-quality study and a low-quality one (Yettick, 2015). Readers with statistical training will be able to make these judgments themselves, instead of relying on the judgment of a journalist or social media contacts.
Statistical savviness can also help people in evaluating researchers’ conclusions. Ideally, the conclusions in a scientific article are supported by the data that the researchers collected. However, this is not always the case. Sometimes researchers misinterpret their data because they either used the wrong statistical procedures or did not understand their results. Having statistical competence can prevent research consumers from being at the mercy of the authors and serve as an independent check on researchers.
统计代写|Generalized linear model代考广义线性模型代写|Two Branches of Statistics
As the science of quantitative data analysis, statistics is a broad field, and it would be impossible for any textbook to cover every branch of statistics while still being of manageable length. In this book we will discuss two branches of statistics: descriptive statistics and inferential statistics. Descriptive statistics is concerned with merely describing the data that a researcher has on hand. Table $1.1$ shows an excerpt from a real collection of data from a study (Waite, Cardon, \& Warne, 2015) about the sibling relationships in families where a child has an autism spectrum disorder. (We will discuss this study and its data in much more detail in Chapters 3 and 10.) Each row in the dataset represents a person and each column in the dataset represents a variable. Therefore, Table $1.1$ has 13 people and 6 variables in it. Each piece of information is a datum (plural: data), and because every person in the table has a value for every variable, there are 84 data in the table (13 people multiplied by 6 variables $=78$ data). A compilation of data is called a dataset.
Even though the dataset in Table $1.1$ is small, it is still difficult to interpret. It takes a moment to ascertain, for example, that there are more females than males in the dataset, or that most people are satisfied with their relationship with their sibling with autism. Table $1.1$ shows just an excerpt of the data. In the study as a whole, there were 45 variables for 13 subjects, which totals to 585 data. No person – no matter how persistent and motivated they are – could understand the entire dataset without some simplification. This is actually a rather small dataset. Most studies in the social sciences have much larger sample sizes. The purpose of descriptive statistics is to describe the
dataset so that it is easier to understand. For example, we could use descriptive statistics to say that in the range of scores on the variable that measures people’s satisfaction with their sibling relationship, the average score is $4.1$, while the average score on the variable measuring whether the sibling with autism understands the respondent’s interests is $2.9$. Chapters 2 – 5 are concerned with descriptive statistics.
On the other hand, if a researcher only has sample data on hand, descriptive statistics tell the researcher little about the population. A separate branch of statistics, termed inferential statistics, was created to help researchers use their sample data to draw conclusions (i.e., inferences) about the population. Inferential statistics is a more complicated field than descriptive statistics, but it is also far more useful. Few social scientists are interested just in the members of their sample. Instead, most are interested in their entire population, and so many social scientists use inferential statistics to learn more about their population – even though they don’t have data from every population member. In fact, they usually only have data from a tiny portion of population members. Inferential statistics spans Chapters $6-15$ of this book.
An example of a use of inferential statistics can be found in a study by Kornrich (2016). This researcher used survey data to examine the amount of money that parents spend on their children. He divided his sample into five groups, ranked from the highest income to the lowest income. He then found the average amount of money that the parents in each group spent on their children and used inferential statistics to estimate the amount of money each group in the population would spend on their children. Unsurprisingly, richer parents spent more money on their children, but Kornrich $(2016)$ also found that the gap in spending on children between the richest $20 \%$ and poorest $20 \%$ of families had widened between 1972 and 2010 . Because Kornrich used inferential statistics, he could draw conclusions about the general population of parents – not just the parents in his sample.
统计代写|Generalized linear model代考广义线性模型代写|Models
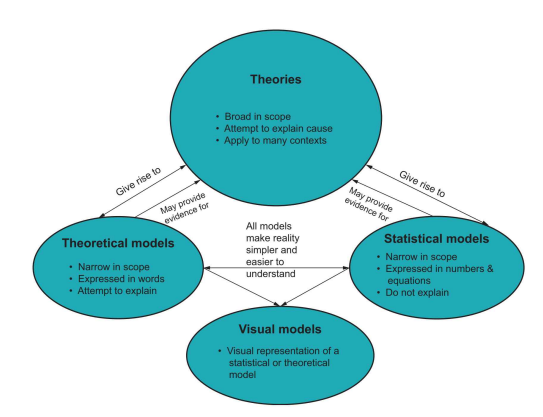
This book is not organized like most other textbooks. As the title states, it is built around a general linear model (GLM) approach. The GLM is a family of statistical procedures that help researchers ascertain the relationships between variables. Chapter 7 explains the GLM in depth. Until then, it is important to understand the concept of a model.
When you hear the word “model,” what do you think of? Some people imagine a fashion model. Others think of a miniature airplane model. Still others think of a prototype or a blueprint. These are all things that are called “models” in the English language. In science, models are “simplifications of a complex reality” (Rodgers, 2010, p. 1). Reality is messy and complicated. It is hard to understand. In fact, reality is so complex-especially in the social sciences – that in order for people to comprehend it, researchers create models.
An example from criminology can illustrate the complexity of reality and the need for models. One of the most pressing questions in criminology is understanding who will commit crimes and why. In reality, it is impossible to comprehend every influence that leads to a person’s decision to commit a crime (or not). This would mean understanding the person’s entire personal history, culture, thoughts, neighborhood, genetic makeup, and more. Andrews and Bonta (2010) have developed the risk-need-responsivity (RNR) model of criminal conduct. Although not its only purpose, the RNR model can help users establish the risk that someone will commit a crime. Andrews and Bonta do not do this by attempting to understand every aspect of a person. Rather, they have chosen a limited number of variables to measure and use those to predict criminal activity. Some of these variables include a history of drug abuse, previous criminal behavior, whether the person is employed, the behavior of their friends, and the presence of certain psychological diagnoses (all of which affect the probability that someone will commit a crime). By limiting the number of variables they measure and use, Andrews and Bonta have created a model of criminal behavior that has been successful in identifying risk of criminal behavior and reducing offenders’ risk of future reoffending after treatment (Andrews, Bonta, \& Wormith, 2011). This model because it does not contain every possible influence on a person’s criminal behavior – is simplified compared to reality.
This example illustrates an important consequence of creating a model. Because models are simplified, every model is – in some way – wrong. Andrews and Bonta (2010) recognize that
their model does not make perfect predictions of criminal behavior every time. Moreover, there are likely some influences not included in the RNR model that may affect the risk of criminal behavior, such as a cultural influence to prevent family shame or the dying request of a beloved relative. Therefore, one can think of a trade-off between model simplicity and model accuracy: simpler models are easier to understand than reality, but this simplification comes at a cost because simplicity makes the model wrong. In a sense, this is true of the types of models most people usually think about. A miniature airplane model is “wrong” because it often does not include many of the parts that a real airplane has. In fact, many model airplanes don’t have any engines – a characteristic that definitely is not true of real airplanes!
Because every model is wrong, it is not realistic to expect models to be perfectly accurate. Instead, models are judged on the basis of how useful they are. A miniature model airplane may be useless in understanding how a full-sized airplane works, but it may be very helpful in understanding the aerodynamic properties of the plane’s body. However, a different model – a blueprint of the engine – may be helpful in understanding how the airplane obtains enough thrust and lift to leave the ground. As this example shows, the usefulness of the model may depend on the goals of the researcher. The engineer interested in aerodynamics may have little use for the engine blueprint, even though a different engineer would argue that the engine blueprint is a vital aspect of understanding the airplane’s function.
This example also shows one last important characteristic of models: often multiple models can fit reality equally well. In other words, it is possible for different models to fit the same reality, such as the miniature airplane model and the plane engine blueprint (Meehl, 1990). As a result, even if a model explains a phenomenon under investigation very well, it may not be the only model that could fit reality well. In fact, there is no guarantee that the model is even the best possible model. Indeed, many researchers in the social sciences are interested in improving their models because that would lead to an improved understanding of the things they investigate. This improvement can happen by combining two models together, finding improved operationalizations of variables, or eliminating unnecessary parts from a model.
广义线性模型代写
统计代写|Generalized linear model代考广义线性模型代写|Why Statistics Matters
尽管许多学生不会选择参加统计课程,但几乎每个社会科学系都要求其学生参加统计课程(例如,Norcross 等人,2016 年;Stoloff 等人,2010 年)。为什么?显然,这些系的教授认为统计数据对学生的教育至关重要,尽管他们的学生可能会怎么想。
许多学生必须学习统计学的主要原因是社会科学研究以基于统计学的方法为主。这一系列方法称为定量研究。使用定量研究的研究人员将他们的数据转换为数字以进行分析,然后通过统计方法对数字进行分析。数字
数据是如此重要,以至于一位社会科学家甚至争辩说“没有数字和衡量标准,科学的进步是不可能的,因为文字和修辞是不够的”(Bouchard,2014 年,第 569 页)。
定量方法——因此也包括统计学——主导着大多数行为科学:心理学、社会学、教育、刑事司法、经济学、政治学等等。大多数在这些领域工作的研究人员使用统计数据来检验新理论、评估疗法的有效性并了解他们研究的概念。即使是不进行研究的工人也必须了解统计数据,才能了解如何(以及是否)在日常工作中应用科学知识。如果没有统计数据,从业者可能会因使用无效的产品、疗法或程序而浪费时间和金钱。在某些情况下,这可能会导致违反道德规范、指控渎职、诉讼以及对客户或顾客造成伤害。即使没有成为科学家的学生也可能需要统计数据来验证轶事观察(例如,他们的公司在当地运动队赢得比赛后销售的产品多于输掉比赛后的产品)是否属实。因此,掌握统计学对很多人都很重要,而不仅仅是研究人员和社会科学家。
从业者在社会科学工作中使用统计数据的主要方式有四种:
- 区分好的研究和坏的研究
- 评估研究人员的结论
- 与他人交流调查结果
- 解释研究以创造实用的、真实的结果。
这四点之间有一些重叠,因此一些工作任务将属于不止一个类别。尽管如此,这仍然是专业人士使用统计数据的有用列表。
对于任何从业者来说,将好的研究与坏的研究区分开来很重要。发表在科学期刊上的研究质量参差不齐。一些文章成为经典并引发新的研究途径;其他人报告了劣质研究。因此,一项研究发表在科学期刊上的事实本身并不能证明高质量的科学工作。统计知识是一个人可以用来区分好研究和坏研究的最重要工具之一。拥有独立判断研究的能力可以防止从业者容易受到其领域的时尚影响或将资源浪费在几乎没有好处的实践上。
将好的研究与坏的研究区分开来的好处对公众也很重要(不仅仅是从业者)。大多数人依靠新闻媒体和互联网的报道来了解科学发现。然而,大多数记者都不是受过训练的科学家,也不具备区分高质量研究和低质量研究所需的技能(Yettick,2015 年)。接受过统计培训的读者将能够自己做出这些判断,而不是依赖记者或社交媒体联系人的判断。
统计知识还可以帮助人们评估研究人员的结论。理想情况下,科学文章中的结论得到研究人员收集的数据的支持。然而,这并非总是如此。有时研究人员会误解他们的数据,因为他们要么使用了错误的统计程序,要么不理解他们的结果。拥有统计能力可以防止研究消费者受到作者的摆布,并作为对研究人员的独立检查。
统计代写|Generalized linear model代考广义线性模型代写|Two Branches of Statistics
作为一门定量数据分析的科学,统计学是一个广阔的领域,任何教科书都不可能涵盖统计学的所有分支,同时又能控制其篇幅。在本书中,我们将讨论统计的两个分支:描述统计和推论统计。描述性统计仅涉及描述研究人员手头的数据。桌子1.1显示了一项研究(Waite, Cardon, \& Warne, 2015)的真实数据集的摘录,该研究关于儿童患有自闭症谱系障碍的家庭中的兄弟姐妹关系。(我们将在第 3 章和第 10 章更详细地讨论这项研究及其数据。)数据集中的每一行代表一个人,数据集中的每一列代表一个变量。因此,表1.1里面有 13 个人和 6 个变量。每条信息都是一个数据(复数:data),因为表中每个人对每个变量都有一个值,所以表中有84个数据(13个人乘以6个变量)=78数据)。数据的汇编称为数据集。
即使表中的数据集1.1很小,还是很难解释。例如,需要一点时间来确定数据集中的女性多于男性,或者大多数人对他们与自闭症兄弟姐妹的关系感到满意。桌子1.1仅显示数据的摘录。在整个研究中,13个受试者有45个变量,总共585个数据。没有人——无论他们多么坚持和积极——可以在不进行一些简化的情况下理解整个数据集。这实际上是一个相当小的数据集。社会科学中的大多数研究都有更大的样本量。描述性统计的目的是描述
数据集,以便于理解。例如,我们可以使用描述性统计来表示,在衡量人们对兄弟关系满意度的变量的得分范围内,平均得分为4.1,而衡量自闭症兄弟姐妹是否理解受访者兴趣的变量的平均得分为2.9. 第 2 章至第 5 章涉及描述性统计。
另一方面,如果研究人员手头只有样本数据,则描述性统计无法告诉研究人员有关总体的信息。创建了一个单独的统计分支,称为推论统计,以帮助研究人员使用他们的样本数据得出关于人口的结论(即推论)。推论统计是一个比描述统计更复杂的领域,但它也更有用。很少有社会科学家只对他们样本中的成员感兴趣。相反,大多数人都对他们的整个人口感兴趣,因此许多社会科学家使用推论统计来更多地了解他们的人口——即使他们没有来自每个人口成员的数据。事实上,他们通常只有一小部分人口的数据。推论统计跨越章节6−15这本书的。
在 Kornrich (2016) 的一项研究中可以找到一个使用推论统计的例子。这位研究人员使用调查数据来检查父母花在孩子身上的金额。他将样本分成五组,从最高收入到最低收入排列。然后,他找到了每组父母在孩子身上花费的平均金额,并使用推论统计来估计人口中每个群体将在孩子身上花费的金额。不出所料,富裕的父母在孩子身上花的钱更多,但科恩里奇(2016)还发现最富有的人在孩子上的支出差距20%和最穷的20%的家庭在 1972 年至 2010 年间扩大了。因为 Kornrich 使用了推论统计,他可以得出关于父母的一般人群的结论——而不仅仅是他样本中的父母。
统计代写|Generalized linear model代考广义线性模型代写|Models
这本书的组织方式与大多数其他教科书不同。正如标题所述,它是围绕通用线性模型 (GLM) 方法构建的。GLM 是一系列统计程序,可帮助研究人员确定变量之间的关系。第 7 章深入解释了 GLM。在此之前,了解模型的概念很重要。
当你听到“模特”这个词时,你会想到什么?有些人想象一个时装模特。其他人则想到了微型飞机模型。还有一些人想到了原型或蓝图。这些都是英语中称为“模型”的东西。在科学中,模型是“复杂现实的简化”(Rodgers,2010,第 1 页)。现实是混乱和复杂的。很难理解。事实上,现实是如此复杂——尤其是在社会科学领域——为了让人们理解它,研究人员创建了模型。
犯罪学的一个例子可以说明现实的复杂性和对模型的需求。犯罪学中最紧迫的问题之一是了解谁将犯罪以及为什么犯罪。实际上,不可能理解导致一个人决定犯罪(或不犯罪)的每一种影响。这意味着要了解这个人的整个个人历史、文化、思想、邻里关系、基因构成等等。Andrews 和 Bonta (2010) 开发了犯罪行为的风险-需求-响应 (RNR) 模型。虽然不是唯一目的,但 RNR 模型可以帮助用户确定某人犯罪的风险。安德鲁斯和邦塔并不是通过试图了解一个人的方方面面来做到这一点的。相反,他们选择了有限数量的变量来衡量和使用这些变量来预测犯罪活动。其中一些变量包括吸毒史、以前的犯罪行为、此人是否受雇、朋友的行为以及是否存在某些心理诊断(所有这些都会影响某人犯罪的可能性)。通过限制他们测量和使用的变量数量,Andrews 和 Bonta 创建了一个犯罪行为模型,该模型成功地识别了犯罪行为的风险并降低了罪犯在治疗后未来再次犯罪的风险(Andrews、Bonta、\& Wormith, 2011)。这个模型因为它不包含对一个人的犯罪行为的所有可能的影响——与现实相比是简化的。以及某些心理诊断的存在(所有这些都会影响某人犯罪的可能性)。通过限制他们测量和使用的变量数量,Andrews 和 Bonta 创建了一个犯罪行为模型,该模型成功地识别了犯罪行为的风险并降低了罪犯在治疗后未来再次犯罪的风险(Andrews、Bonta、\& Wormith, 2011)。这个模型因为它不包含对一个人的犯罪行为的所有可能的影响——与现实相比是简化的。以及某些心理诊断的存在(所有这些都会影响某人犯罪的可能性)。通过限制他们测量和使用的变量数量,Andrews 和 Bonta 创建了一个犯罪行为模型,该模型成功地识别了犯罪行为的风险并降低了罪犯在治疗后未来再次犯罪的风险(Andrews、Bonta、\& Wormith, 2011)。这个模型因为它不包含对一个人的犯罪行为的所有可能的影响——与现实相比是简化的。Andrews 和 Bonta 创建了一个犯罪行为模型,该模型成功地识别了犯罪行为的风险并降低了罪犯在治疗后未来再次犯罪的风险(Andrews, Bonta, \& Wormith, 2011)。这个模型因为它不包含对一个人的犯罪行为的所有可能的影响——与现实相比是简化的。Andrews 和 Bonta 创建了一个犯罪行为模型,该模型成功地识别了犯罪行为的风险并降低了罪犯在治疗后未来再次犯罪的风险(Andrews, Bonta, \& Wormith, 2011)。这个模型因为它不包含对一个人的犯罪行为的所有可能的影响——与现实相比是简化的。
这个例子说明了创建模型的一个重要结果。因为模型被简化了,所以每个模型——在某种程度上——都是错误的。Andrews 和 Bonta (2010) 认识到
他们的模型并非每次都能完美预测犯罪行为。此外,RNR 模型中可能有一些影响可能会影响犯罪行为的风险,例如防止家庭耻辱的文化影响或挚爱亲属的临终要求。因此,可以考虑在模型简单性和模型准确性之间进行权衡:更简单的模型比现实更容易理解,但这种简化是有代价的,因为简单会使模型出错。从某种意义上说,大多数人通常想到的模型类型都是如此。微型飞机模型是“错误的”,因为它通常不包括真实飞机所具有的许多部件。事实上,许多模型飞机没有任何引擎——这绝对不是真正的飞机的特点!
因为每个模型都是错误的,所以期望模型完全准确是不现实的。相反,模型是根据它们的有用程度来判断的。微型模型飞机可能无法理解全尺寸飞机的工作原理,但它可能对理解飞机机身的空气动力学特性非常有帮助。然而,一个不同的模型——发动机的蓝图——可能有助于理解飞机如何获得足够的推力和升力以离开地面。如本例所示,模型的有用性可能取决于研究人员的目标。对空气动力学感兴趣的工程师可能对发动机蓝图没有什么用处,尽管另一位工程师会争辩说发动机蓝图是理解飞机功能的重要方面。
这个例子还显示了模型的最后一个重要特征:通常多个模型可以同样好地适应现实。换句话说,不同的模型有可能适合相同的现实,例如微型飞机模型和飞机发动机蓝图(Meehl,1990)。因此,即使一个模型很好地解释了正在研究的现象,它也可能不是唯一能很好地拟合现实的模型。事实上,不能保证该模型甚至是最好的模型。事实上,社会科学领域的许多研究人员都对改进他们的模型感兴趣,因为这将有助于更好地理解他们所研究的事物。这种改进可以通过将两个模型组合在一起、找到改进的变量操作或从模型中消除不必要的部分来实现。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。