如果你也在 怎样代写机器学习 machine learning这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
机器学习是一个致力于理解和建立 “学习 “方法的研究领域,也就是说,利用数据来提高某些任务的性能的方法。机器学习算法基于样本数据(称为训练数据)建立模型,以便在没有明确编程的情况下做出预测或决定。机器学习算法被广泛用于各种应用,如医学、电子邮件过滤、语音识别和计算机视觉,在这些应用中,开发传统算法来执行所需任务是困难的或不可行的。
statistics-lab™ 为您的留学生涯保驾护航 在代写机器学习 machine learning方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写机器学习 machine learning代写方面经验极为丰富,各种代写机器学习 machine learning相关的作业也就用不着说。
我们提供的机器学习 machine learning及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
计算机代写|机器学习代写machine learning代考|Related Work
In 2019, Ayşe et al. [1] have obtainable a vivo study for confirming the recognition of proximal caries by means of NILTI. Moreover, the diagnostic performance of the device was compared over other caries recognition techniques, together with visual assessment. Accordingly, here a total of nine seventy-four proximal surfaces of stable posterior teeth from thirty-four patients were taken into account. The data were examined with statistical analysis and the AUC, specificity, and sensitivity were computed.
In 2019, Darshan et al. [2] have computed the relationship among susceptibility of dental caries progression risk and ENAM gene polymorphisms. The implemented analysis was performed on one sixty-eight children from South India and kids affected by dental caries were also taken into account. ‘Preliminary Insilco analysis’ has revealed that variations in ‘rs7671281 (Ile648Thr) amino acid’ leads to the functional and structural changes in the ENAM.
In 2018, Lee et al. [26] have adopted a method for evaluating the efficiency of DCNN approaches for diagnosis and detection of dental caries on ‘periapical radiographs’. Accordingly, this analysis focused on the potential effectiveness of the DCNN framework for the diagnosis and detection of dental caries. From the analysis, the DCNN framework has offered significant performance in recognizing dental caries in ‘periapical radiographs’.
In 2019, Yue et al. [27] have carried out an analysis on detecting dental caries on three eighty-six kids residing in Mexico town. Here, ‘graphitefurnace atomic-absorption spectroscopy’ was used for quantifying the $\mathrm{Pb}$ levels of blood. Accordingly, the existence of dental caries was computed by means of DMFT scores. Furthermore, the residual approach was exploited in this work for determining the total energy produced in the children based on the consumption of sweets and beverages.
In 2019, Cácia et al. [28] have analyzed how the risk factors of patients influenced operative diagnostic decisions in a dental oriented system in the Netherlands. In this work, the data were gathered from eleven dental practices and the patients attended the practice regularly throughout the observation time. Consequently, a descriptive study was carried out after performing the MLR process.
计算机代写|机器学习代写machine learning代考|Proposed Model for Cavities Detection
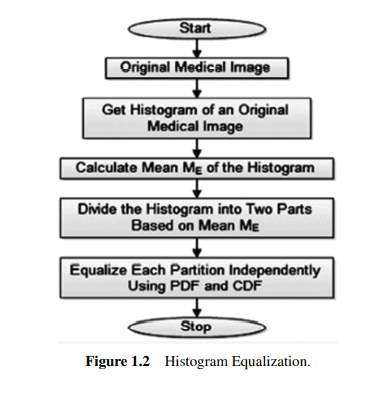
Figure $1.1$ reveals the schematic depiction of the embraced dental cavities detection model. The instigated outline comprises three foremost steps:
- Enhancement and Pre-processing;
- Feature Extraction;
- Classification;
- Optimization.
At the outset, the input image Im is imperiled to noise removing, brightening, and enriching through pre-processing, which comprises four important image upgrading features such as CLLAHE, contrast upgrading, grey thresholding, and active contour. From the pre-processed image $I_{\text {pre }}$, the features are mined by the aid of the MSL method like MLDA \& MPCA model. These mined features are then imperiled to cataloging using NN classifier that bids the categorized outcome (Cavities or No Cavities) [13-16].
计算机代写|机器学习代写machine learning代考|Pre-processing
The image Im is improved by carrying out the below processes.
Conventional Adaptive Histogram Equalisation is apt to over intensify the contrast in near-constant provinces of the image, meanwhile the histogram in such areas is exceedingly strenuous. As a consequence, Adaptive Histogram Equalization may root noise to be enlarged in near-constant areas. Contrast Limited AHE (CLAHE) is modified of adaptable and adjustable histogram equalization in which the dissimilarity intensification is inadequate, so as to diminish this delinquent of noise intensification.
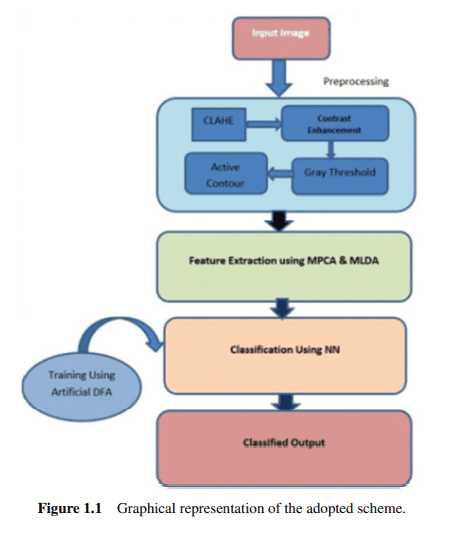
In Contrast Limited AHE (CLAHE), the contrast solidification in the vicinity of a quantified pixel worth is quantified by the gradient of the variation function. This is interactive to the slope of the locality accumulative dissemination function and accordingly to the cost of the histogram at that pixel cost. Contrast Limited AHE confines the intensification by trimming the histogram at a predefined value before calculating the CDF. This confines the slant of the CDF and consequently of the alteration function. The cost at which the histogram is cropped, the ostensible clip perimeter, be governed by normalization of the histogram and thus on the extent of the vicinity region. Collective values limit the resultant intensification. It is advantageous not to discard the part of the histogram that exceeds the clip limit but to redistribute it equally among all histogram bins (refer Figure $1.2$ ) [17-21].
机器学习代考
计算机代写|机器学习代写machine learning代考|Related Work
2019 年,Ayşe 等人。[1] 获得了一项体内研究,以确认通过 NILTI 识别近端龋齿。此外,该设备的诊断性能与其他龋齿识别技术以及视觉评估进行了比较。因此,这里总共考虑了来自 34 名患者的稳定后牙的 9 74 个近端面。用统计分析检查数据并计算AUC、特异性和敏感性。
2019 年,Darshan 等人。[2] 计算了龋齿进展风险的易感性与 ENAM 基因多态性之间的关系。对来自南印度的 168 名儿童进行了实施分析,并且还考虑了受龋齿影响的儿童。“初步 Insilco 分析”显示,“rs7671281 (Ile648Thr) 氨基酸”的变异导致 ENAM 的功能和结构变化。
2018 年,Lee 等人。[26] 采用了一种方法来评估 DCNN 方法在“根尖片”上诊断和检测龋齿的效率。因此,本分析侧重于 DCNN 框架在龋齿诊断和检测方面的潜在有效性。从分析来看,DCNN 框架在识别“根尖片”中的龋齿方面提供了显着的性能。
2019年,岳等人。[27] 对居住在墨西哥城的 3 名 86 名儿童的龋齿进行了分析。在这里,“石墨炉原子吸收光谱”用于量化磷b血液水平。因此,龋齿的存在是通过 DMFT 评分来计算的。此外,在这项工作中利用剩余方法来确定基于糖果和饮料消费的儿童产生的总能量。
2019 年,Cácia 等人。[28] 分析了患者的风险因素如何影响荷兰牙科系统中的手术诊断决策。在这项工作中,数据来自 11 家牙科诊所,患者在整个观察期间定期参加诊所。因此,在执行 MLR 过程后进行了描述性研究。
计算机代写|机器学习代写machine learning代考|Proposed Model for Cavities Detection
数字1.1揭示了包含的蛀牙检测模型的示意图。发起的大纲包括三个最重要的步骤:
- 增强和预处理;
- 特征提取;
- 分类;
- 优化。
首先,输入图像Im通过预处理进行去噪、增亮和富集,包括CLLAHE、对比度升级、灰度阈值和主动轮廓等四个重要的图像升级特征。从预处理图像我预 ,特征是通过MLDA \& MPCA模型等MSL方法挖掘出来的。然后,使用 NN 分类器对分类结果(Cavities or No Cavities)出价 [13-16] 对这些挖掘的特征进行编目。
计算机代写|机器学习代写machine learning代考|Pre-processing
图像 Im 通过执行以下处理得到改善。
传统的自适应直方图均衡化在图像接近恒定的区域容易过度增强对比度,同时这些区域的直方图非常吃力。因此,自适应直方图均衡可能会导致噪声在接近恒定的区域被放大。对比度受限的 AHE (CLAHE) 是对差异增强不足的自适应和可调节直方图均衡进行修改,以减少这种噪声增强的拖欠。
在对比度受限的 AHE (CLAHE) 中,量化像素值附近的对比度固化通过变化函数的梯度进行量化。这与局部累积传播函数的斜率以及相应的直方图在该像素成本下的成本是交互的。对比度受限 AHE 通过在计算 CDF 之前将直方图修剪为预定义值来限制增强。这限制了 CDF 的倾斜,从而限制了更改函数。裁剪直方图的成本,即表面上的剪辑周长,受直方图的归一化以及附近区域的范围控制。集体价值限制了由此产生的强化。1.2 ) [17-21].

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。