如果你也在 怎样代写tensorflow这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
TensorFlow是一个用于机器学习和人工智能的免费和开源的软件库。它可以用于一系列的任务,但特别关注深度神经网络的训练和推理。
statistics-lab™ 为您的留学生涯保驾护航 在代写tensorflow方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写tensorflow代写方面经验极为丰富,各种代写tensorflow相关的作业也就用不着说。
我们提供的tensorflow及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础

机器学习代写|tensorflow代写|Unsupervised learning
Unsupervised learning is about modeling data that comes without corresponding labels or responses. The fact that we can make any conclusions at all on raw data feels like magic. With enough data, it may be possible to find patterns and structure. Two of the most powerful tools that machine-learning practitioners use to learn from data alone are clustering and dimensionality reduction.
Clustering is the process of splitting the data into individual buckets of similar items. In a sense, clustering is like classifying data without knowing any corresponding labels. When organizing your books on three shelves, for example, you likely place similar genres together, or maybe you group them by the authors’ last names. You might have a Stephen King section, another for textbooks, and a third for anything else. You don’t care that all the books are separated by the same feature, only that each book has something unique that allows you to organize it into one of several roughly equal, easily identifiable groups. One of the most popular clustering algorithms is $k$-means, which is a specific instance of a more powerful technique called the E-M algorithm.
Dimensionality reduction is about manipulating the data to view it from a much simpler perspective-the ML equivalent of the phrase “Keep it simple, stupid.” By getting rid of redundant features, for example, we can explain the same data in a lowerdimensional space and see which features matter. This simplification also helps in data visualization or preprocessing for performance efficiency. One of the earliest algorithms is principle component analysis (PCA), and a newer one is autoencoders, which are covered in chapter 7 .
机器学习代写|tensorflow代写|Reinforcement learning
Supervised and unsupervised learning seem to suggest that the existence of a teacher is all or nothing. But in one well-studied branch of machine learning, the environment acts as a teacher, providing hints as opposed to definite answers. The learning system receives feedback on its actions, with no concrete promise that it’s progressing in the right direction, which might be to solve a maze or accomplish an explicit goal.
Unlike supervised learning, in which training data is conveniently labeled by a “teacher,” reinforcement learning trains on information gathered by observing how the environment reacts to actions. Reinforcement learning is a type of machine learning that interacts with the environment to learn which combination of actions yields the most favorable results. Because we’re already anthropomorphizing algorithms by using the words environment and action, scholars typically refer to the system as an autonomous agent. Therefore, this type of machine learning naturally manifests itself in the domain of robotics.
To reason about agents in the environment, we introduce two new concepts: states and actions. The status of the world frozen at a particular time is called a state. An agent may perform one of many actions to change the current state. To drive an agent to perform actions, each state yields a corresponding reward. An agent eventually discovers the expected total reward of each state, called the value of a state.
Like any other machine-learning system, performance improves with more data. In this case, the data is a history of experiences. In reinforcement learning, we don’t know the final cost or reward of a series of actions until that series is executed. These situations render traditional supervised learning ineffective, because we don’t know exactly which action in the history of action sequences is to blame for ending up in a low-value state. The only information an agent knows for certain is the cost of a series of actions that it has already taken, which is incomplete. The agent’s goal is to find a sequence of actions that maximizes rewards. If you’re more interested in this subject, you may want to check out another topical book in the Manning Publications family: Grokking Deep Reinforcement Learning, by Miguel Morales (Manning, 2020; https://www .manning.com/books/grokking-deep-reinforcement-learning).
机器学习代写|tensorflow代写|Meta-learning
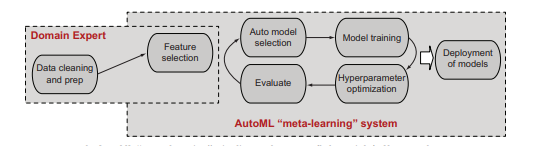
Relatively recently, a new area of machine learning called meta-learning has emerged. The idea is simple. Data scientists and ML experts spend a tremendous amount of time executing the steps of ML, as shown in figure 1.7. What if those steps-defining and representing the problem, choosing a model, testing the model, and evaluating the model-could themselves be automated? Instead of being limited to exploring only one or a small group of models, why not have the program itself try all the models?
Many businesses separate the roles of the domain expert (refer to the doctor in figure 1.7), the data scientist (the person modeling the data and potentially extracting or choosing features that are important, such as the image RGB pixels), and the ML engineer (responsible for tuning, testing, and deploying the model), as shown in figure $1.10 \mathrm{a}$. As you’ll remember from earlier in the chapter, these roles interact in three basic areas: data cleaning and prep, which both the domain expert and data scientist may help with; feature and model selection, mainly a data-scientist job with a little help from the ML engineer; and then train, test, and evaluate, mostly the job of the ML engineer with a little help from the data scientist. We’ve added a new wrinkle: taking our model and deploying it, which is what happens in the real world and is something that brings its own set of challenges. This scenario is one reason why you are reading the second edition of this book; it’s covered in chapter 2, where I discuss deploying and using TensorFlow.
What if instead of having data scientists and ML engineers pick models, train, evaluate, and tune them, we could have the system automatically search over the space of possible models, and try them all? This approach overcomes limiting your overall ML experience to a small number of possible solutions wherein you’ll likely choose the first one that performs reasonably. But what if the system could figure out which models are best and how to tune the models automatically? That’s precisely what you see in figure $1.10 \mathrm{~b}$ : the process of meta-learning, or AutoML.
tensorflow代考
机器学习代写|tensorflow代写|Unsupervised learning
无监督学习是关于对没有相应标签或响应的数据进行建模。我们可以根据原始数据得出任何结论的事实感觉就像魔术一样。有了足够的数据,就有可能找到模式和结构。机器学习从业者用来从数据中学习的两个最强大的工具是聚类和降维。
聚类是将数据拆分为相似项目的单个存储桶的过程。从某种意义上说,聚类就像在不知道任何相应标签的情况下对数据进行分类。例如,在三个书架上组织您的书籍时,您可能会将类似的类型放在一起,或者您可能按作者的姓氏对它们进行分组。您可能有一个斯蒂芬金部分,另一个用于教科书,第三个用于其他任何内容。您并不关心所有书籍都由相同的功能分隔,只是每本书都有独特的东西,可以让您将其组织成几个大致相等且易于识别的组之一。最流行的聚类算法之一是 k-means,它是一种称为 EM 算法的更强大技术的特定实例。
降维是关于操纵数据以从更简单的角度查看数据 – ML 相当于短语“保持简单,愚蠢”。例如,通过去除冗余特征,我们可以在低维空间中解释相同的数据,看看哪些特征很重要。这种简化还有助于数据可视化或预处理以提高性能。最早的算法之一是主成分分析(PCA),一种较新的算法是自动编码器,它们将在第 7 章中介绍。
机器学习代写|tensorflow代写|Reinforcement learning
有监督和无监督学习似乎表明老师的存在是全部或全部。但在机器学习的一个经过充分研究的分支中,环境就像老师一样,提供提示而不是明确的答案。学习系统会收到对其行为的反馈,但没有具体承诺它会朝着正确的方向前进,这可能是解决迷宫或实现明确的目标。
与监督学习不同,其中训练数据由“老师”方便地标记,强化学习通过观察环境对行动的反应来训练收集的信息。强化学习是一种机器学习,它与环境交互以了解哪种动作组合产生最有利的结果。因为我们已经通过使用环境和动作这两个词来拟人化算法,所以学者们通常将系统称为自主代理。因此,这种类型的机器学习自然而然地表现在机器人领域。
为了推理环境中的代理,我们引入了两个新概念:状态和动作。在特定时间冻结的世界的状态称为状态。代理可以执行许多操作之一来更改当前状态。为了驱动代理执行动作,每个状态都会产生相应的奖励。代理最终会发现每个状态的预期总奖励,称为状态的价值。
与任何其他机器学习系统一样,性能会随着数据的增加而提高。在这种情况下,数据是经验的历史。在强化学习中,我们不知道一系列动作的最终成本或回报,直到该系列被执行。这些情况使传统的监督学习变得无效,因为我们不确切知道动作序列历史中的哪个动作应该归咎于最终处于低价值状态。代理人唯一确定的信息是它已经采取的一系列行动的成本,这是不完整的。智能体的目标是找到使奖励最大化的一系列动作。如果您对这个主题更感兴趣,您可能需要查看 Manning Publications 系列中的另一本专题书籍:Grokking Deep Reinforcement Learning,作者为 Miguel Morales(Manning,2020;https://www .
机器学习代写|tensorflow代写|Meta-learning
最近,出现了一个称为元学习的新机器学习领域。这个想法很简单。数据科学家和机器学习专家花费大量时间执行机器学习的步骤,如图 1.7 所示。如果这些步骤(定义和表示问题、选择模型、测试模型和评估模型)本身可以自动化呢?为什么不让程序本身尝试所有模型,而不是仅限于探索一个或一小组模型?
许多企业将领域专家(参见图 1.7 中的医生)、数据科学家(对数据进行建模并可能提取或选择重要特征,例如图像 RGB 像素)和 ML 工程师的角色分开(负责调优、测试和部署模型),如图 $1.10\mathrm{a}$ 所示。正如您将在本章前面所记得的那样,这些角色在三个基本领域相互作用:数据清理和准备,领域专家和数据科学家都可以提供帮助;特征和模型选择,主要是数据科学家的工作,在 ML 工程师的帮助下;然后在数据科学家的帮助下训练、测试和评估,主要是 ML 工程师的工作。我们增加了一个新问题:采用我们的模型并部署它,这就是现实世界中发生的事情,并且会带来一系列挑战。这种情况是您阅读本书第二版的原因之一。它在第 2 章中进行了介绍,在那里我讨论了部署和使用 TensorFlow。1.10a。正如您将在本章前面所记得的那样,这些角色在三个基本领域相互作用:数据清理和准备,领域专家和数据科学家都可以提供帮助;特征和模型选择,主要是数据科学家的工作,在 ML 工程师的帮助下;然后在数据科学家的帮助下训练、测试和评估,主要是 ML 工程师的工作。我们增加了一个新问题:采用我们的模型并进行部署,这就是现实世界中发生的事情,也带来了一系列挑战。这种情况是您阅读本书第二版的原因之一。它在第 2 章中进行了介绍,在那里我讨论了部署和使用 TensorFlow。
如果不是让数据科学家和 ML 工程师挑选、训练、评估和调整模型,而是让系统自动搜索可能模型的空间,然后全部尝试,会怎样?这种方法克服了将您的整体 ML 体验限制为少数可能的解决方案的问题,在这些解决方案中您可能会选择第一个执行合理的解决方案。但是,如果系统能够找出最好的模型以及如何自动调整模型呢?这正是您在图 $1.10 \mathrm{~b}$ 中看到的:元学习或 AutoML 的过程。1.10 b:元学习或 AutoML 的过程。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。