如果你也在 怎样代写商业分析Statistical Modelling for Business这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
商业分析就是利用数据分析和统计的方法,来分析企业之前的商业表现,从而通过分析结果来对未来的商业战略进行预测和指导 。
statistics-lab™ 为您的留学生涯保驾护航 在代写商业分析Statistical Modelling for Business方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写商业分析Statistical Modelling for Business方面经验极为丰富,各种代写商业分析Statistical Modelling for Business相关的作业也就用不着说。
我们提供的商业分析Statistical Modelling for Business及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等楖率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|商业分析作业代写Statistical Modelling for Business代考|Data sets, elements, and variables
We have said that data are facts and figures from which conclusions can be drawn. Together, the data that are collected for a particular study are referred to as a data set. For example, Table $1.1$ is a data set that gives information about the new homes sold in a Florida luxury home development over a recent three-month period. Potential home buyers could choose either the “Diamond” or the “Ruby” home model design and could have the home built on either a lake lot or a treed lot (with no water access).
In order to understand the data in Table 1.1, note that any data set provides information about some group of individual elements, which may be people, objects, events, or other entities. The information that a data set provides about its elements usually describes one or more characteristics of these elements.
For the data set in Table 1.1, each sold home is an element, and four variables are used to describe the homes. These variables are (1) the home model design, (2) the type of lot on which the home was built, (3) the list (asking) price, and (4) the (actual) selling price. Moreover, each home model design came with “everything included”-specifically, a complete, luxury interior package and a choice (at no price difference) of one of three different architectural exteriors. The builder made the list price of each home solely dependent on the model design. However, the builder gave various price reductions for homes built on treed lots.
The data in Table $1.1$ are real (with some minor changes to protect privacy) and were provided by a business executive – a friend of the authors – who recently received a promotion and needed to move to central Florida. While searching for a new home, the executive and his family visited the luxury home community and decided they wanted to purchase a Diamond model on a treed lot. The list price of this home was $\$ 494,000$, but the developer offered to sell it for an “incentive” price of $\$ 469,000$. Intuitively, the incentive price’s $\$ 25,000$ savings off list price seemed like a good deal. However, the executive resisted making an immediate decision. Instead, he decided to collect data on the selling prices of new homes recently sold in the community and use the data to assess whether the developer might accept a lower offer. In order to collect “relevant data,” the executive talked to local real estate professionals and learned that new homes sold in the community during the previous three months were $\mathrm{~ a ~ g o u l ~ i m l i z a u r ~ o f ~ c o r r e n ~ h o m e ~ v a l u e ~ L o x i n g ~ r e a l ~ m a l a t e ~ s a l e x ~ r e c t u r i}$ learned that tive of the community’s new homes had sold in the previous three months. The data given in Table $1.1$ are the data that the executive collected about these five homes.
When the business executive examined Table 1.1, he noted that homes on lake lots had sold at their list price, but homes on treed lots had not. Because the executive and his family wished to purchase a Diamond model on a treed lot, the executive also noted that two Diamond models on treed lots had sold in the previous three months. One of these Diamond models had sold for the incentive price of $\$ 469,000$, but the other had sold for a lower price of $\$ 440,000$. Hoping to pay the lower price for his family’s new home, the executive offered $\$ 440,000$ for the Diamond model on the treed lot. Initially, the home builder turned down this offer, but two days later the builder called back and accepted the offer. The executive had used data to buy the new home for $\$ 54,000$ less than the list price and $\$ 29,000$ less than the incentive price!
统计代写|商业分析作业代写Statistical Modelling for Business代考|Quantitative and qualitative variables
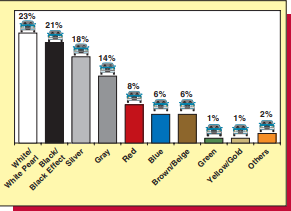
For any variable describing an element in a data set, we carry out a measurement to assign a value of the variable to the element. For example, in the real estate example, real estate sales records gave the actual selling price of each home to the nearest dollar. As another example, a credit card company might measure the time it takes for a cardholder’s bill to be paid to the nearest day. Or, as a third example, an automaker might measure the gasoline mileage obtained by a car in city driving to the nearest one-tenth of a mile per gallon by conducting a mileage test on a driving course prescribed by the Environmental Protection Agency (EPA). If the possible values of a variable are numbers that represent quantities (that is, “how much” or “how many”), then the variable is said to be quantitative. For example, (1) the actual selling price of a home, (2) the payment time of a bill, (3) the gasoline mileage of a car, and (4) the 2014 payroll of a Major League Baseball team are all quantitative variables. Considering the last example, Table $1.2$ in the page margin gives the 2014 payroll (in millions of dollars) for each of the 30 Major League Baseball (MLB) teams. Moreover, Figure $1.1$ portrays the team payrolls as a dot plot. In this plot, each team payroll is shown as a dot located on the real number line-for example, the leftmost dot represents the payroll for the Houston Astros. In general, the values of a quantitative variable are numbers on the real line. In contrast, if we simply record into which of several categories an element falls, then the variable is said to be qualitative or categorical. Examples of categorical variables include (1) a person’s gender, (2) whether a person who purchases a product is satisfied with the product, (3) the type of lot on which a home is built, and (4) the color of a car. . Figure $1.2$ illustrates the categories we might use for the qualitative variable “car color.” This figure is a bar chart showing the 10 most popular (worldwide) car colors for 2012 and the percentages of cars having these colors.
统计代写|商业分析作业代写Statistical Modelling for Business代考|Cross-sectional and time series data
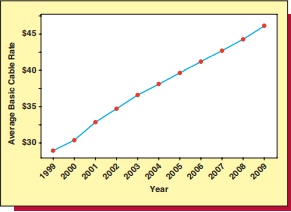
Some statistical techniques are used to analyze cross-sectional data, while others are used to analyze time series data. Cross-sectional data are data collected at the same or approximately the same point in time. For example, suppose that a bank wishes to analyze last month’s cell phone bills for its employees. Then, because the cell phone costs given by these bills are for different employees in the same month, the cell phone costs are cross-sectional data. Time series data are data collected over different time periods. For example, Table $1.3$ presents the average basic cable television rate in the United States for each of the years 1999 to 2009 . Figure $1.3$ is a time series plot-also called a runs plot-of these data. Here we plot each cable rate on the vertical scale versus its corresponding time index (year) on the horizontal scale. For instance, the first cable rate $(\$ 28.92$ ) is plotted versus 1999 , the second cable rate $(\$ 30.37)$ is plotted versus 2000 , and so forth. Examining the time series plot, we see that the cable rates increased substantially from 1999 to 2009 . Finally. because the five homes in Tablc $1.1$ wcre sold over a thrcc-month period that representcd a rclatively stable real estate market, we can consider the data in Table $1.1$ to essentially be cross-sectional data.Primary data are data collected by an individual or business directly through planned experimentation or observation. Secondary data are data taken from an existing source.
金融中的随机方法代写
统计代写|商业分析作业代写Statistical Modelling for Business代考|Data sets, elements, and variables
我们已经说过,数据是可以从中得出结论的事实和数据。为特定研究收集的数据一起被称为数据集。例如,表1.1是一个数据集,提供有关最近三个月内佛罗里达州豪宅开发中出售的新房的信息。潜在的购房者可以选择“钻石”或“红宝石”住宅模型设计,并且可以将房屋建在湖边或树木繁茂的地段(没有水路)。
为了理解表 1.1 中的数据,请注意,任何数据集都提供有关某些单独元素组的信息,这些元素可能是人、对象、事件或其他实体。数据集提供的有关其元素的信息通常描述了这些元素的一个或多个特征。
对于表 1.1 中的数据集,每个售出的房屋都是一个元素,四个变量用于描述房屋。这些变量是(1)房屋模型设计,(2)建造房屋的地块类型,(3)标价(要价)和(4)(实际)售价。此外,每个家庭模型设计都带有“包括的一切”——具体来说,一个完整的、豪华的内部包装和三种不同建筑外观之一的选择(没有价格差异)。建筑商使每个房屋的标价完全取决于模型设计。然而,建筑商对建在树丛上的房屋进行了各种降价。
表中数据1.1是真实的(为了保护隐私而做了一些小的改动),并且是由一位商业主管(作者的朋友)提供的,他最近获得了晋升,需要搬到佛罗里达州中部。在寻找新家时,这位高管和他的家人参观了豪宅社区,并决定在一片树木繁茂的土地上购买钻石模型。这个房子的标价是$494,000,但开发商提出以“激励”价格出售$469,000. 直观地说,激励价格$25,000节省标价似乎很划算。然而,这位高管拒绝立即做出决定。相反,他决定收集社区最近出售的新房售价数据,并使用这些数据来评估开发商是否会接受更低的报价。为了收集“相关数据”,这位高管与当地房地产专业人士进行了交谈,了解到过去三个月在该社区出售的新房 一种 G这在l 一世米l一世和一种在r 这F C这rr和n H这米和 在一种l在和 大号这X一世nG r和一种l 米一种l一种吨和 s一种l和X r和C吨在r一世据了解,该社区的新房在过去三个月内已售出。表中给出的数据1.1是行政人员收集的有关这五个房屋的数据。
当业务主管检查表 1.1 时,他注意到湖区的房屋以标价出售,但树木繁茂的房屋却没有。由于该高管及其家人希望在树木繁茂的地段购买钻石模型,该高管还指出,在过去三个月内,已售出两颗树木茂密的钻石模型。其中一款 Diamond 模型以优惠价格售出$469,000,但另一个以较低的价格出售$440,000. 这位高管希望为他家的新房支付较低的价格,他提出$440,000对于树木繁茂的钻石模型。最初,房屋建筑商拒绝了这个提议,但两天后,建筑商回电并接受了这个提议。这位高管曾使用数据购买新房$54,000低于标价和$29,000低于激励价!
统计代写|商业分析作业代写Statistical Modelling for Business代考|Quantitative and qualitative variables
对于描述数据集中元素的任何变量,我们进行测量以将变量的值分配给元素。例如,在房地产示例中,房地产销售记录将每个房屋的实际售价精确到美元。作为另一个例子,信用卡公司可能会测量持卡人账单支付到最近一天所需的时间。或者,作为第三个例子,汽车制造商可能会通过在环境保护署 (EPA) 规定的驾驶路线上进行里程测试来测量汽车在城市中行驶所获得的汽油里程,精确到每加仑十分之一英里。 . 如果变量的可能值是表示数量的数字(即“多少”或“多少”),则称该变量是定量的。例如,(1)房屋的实际售价,(2)账单的支付时间,(3)汽车的汽油里程,(4)美国职棒大联盟2014年的工资单都是定量变量。考虑最后一个例子,表1.2页边距中给出了 30 支美国职棒大联盟 (MLB) 球队中每支球队的 2014 年工资单(以百万美元计)。此外,图1.1将团队工资单描绘为点图。在该图中,每支球队的工资单显示为位于实数线上的一个点——例如,最左边的点代表休斯顿太空人队的工资单。通常,定量变量的值是实线上的数字。相反,如果我们简单地记录一个元素属于几个类别中的哪一个,那么这个变量就被称为是定性的或分类的。分类变量的示例包括(1)一个人的性别,(2)购买产品的人是否对产品感到满意,(3)建造房屋的地块类型,以及(4)房屋的颜色车。. 数字1.2说明了我们可能用于定性变量“汽车颜色”的类别。该图是一个条形图,显示了 2012 年最流行的 10 种(全球)汽车颜色以及拥有这些颜色的汽车的百分比。
统计代写|商业分析作业代写Statistical Modelling for Business代考|Cross-sectional and time series data
一些统计技术用于分析横截面数据,而另一些则用于分析时间序列数据。横截面数据是在相同或大致相同的时间点收集的数据。例如,假设一家银行希望为其员工分析上个月的手机账单。那么,由于这些账单给出的手机费用是针对同一个月不同员工的,所以手机费用是横截面数据。时间序列数据是在不同时间段收集的数据。例如,表1.3显示 1999 年至 2009 年每年美国的平均基本有线电视费率。数字1.3是这些数据的时间序列图 – 也称为运行图。在这里,我们在垂直尺度上绘制每个电缆速率与在水平尺度上对应的时间指数(年)。例如,第一电缆费率($28.92) 相对于 1999 年绘制,第二个电缆速率($30.37)相对于 2000 绘制,依此类推。检查时间序列图,我们看到电缆费率从 1999 年到 2009 年大幅增加。最后。因为 Tablc 中的五家1.1wcre 在 thrcc 个月内售出,代表相对稳定的房地产市场,我们可以考虑表中的数据1.1本质上是横截面数据。主要数据是个人或企业直接通过有计划的实验或观察收集的数据。辅助数据是从现有来源获取的数据。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。统计代写|python代写代考
随机过程代考
在概率论概念中,随机过程是随机变量的集合。 若一随机系统的样本点是随机函数,则称此函数为样本函数,这一随机系统全部样本函数的集合是一个随机过程。 实际应用中,样本函数的一般定义在时间域或者空间域。 随机过程的实例如股票和汇率的波动、语音信号、视频信号、体温的变化,随机运动如布朗运动、随机徘徊等等。
贝叶斯方法代考
贝叶斯统计概念及数据分析表示使用概率陈述回答有关未知参数的研究问题以及统计范式。后验分布包括关于参数的先验分布,和基于观测数据提供关于参数的信息似然模型。根据选择的先验分布和似然模型,后验分布可以解析或近似,例如,马尔科夫链蒙特卡罗 (MCMC) 方法之一。贝叶斯统计概念及数据分析使用后验分布来形成模型参数的各种摘要,包括点估计,如后验平均值、中位数、百分位数和称为可信区间的区间估计。此外,所有关于模型参数的统计检验都可以表示为基于估计后验分布的概率报表。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
statistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
机器学习代写
随着AI的大潮到来,Machine Learning逐渐成为一个新的学习热点。同时与传统CS相比,Machine Learning在其他领域也有着广泛的应用,因此这门学科成为不仅折磨CS专业同学的“小恶魔”,也是折磨生物、化学、统计等其他学科留学生的“大魔王”。学习Machine learning的一大绊脚石在于使用语言众多,跨学科范围广,所以学习起来尤其困难。但是不管你在学习Machine Learning时遇到任何难题,StudyGate专业导师团队都能为你轻松解决。
多元统计分析代考
基础数据: $N$ 个样本, $P$ 个变量数的单样本,组成的横列的数据表
变量定性: 分类和顺序;变量定量:数值
数学公式的角度分为: 因变量与自变量
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。