如果你也在 怎样代写数据结构data structure这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
数据结构是一种用于存储和组织数据的存储。它是一种在计算机上安排数据的方式,以便可以有效地访问和更新。根据你的要求和项目,为你的项目选择正确的数据结构很重要。
statistics-lab™ 为您的留学生涯保驾护航 在代写数据结构data structure方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写数据结构data structure方面经验极为丰富,各种代写数据结构data structure相关的作业也就用不着说。
我们提供的数据结构data structure及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等楖率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|数据结构作业代写data structure代考|What is a Stack
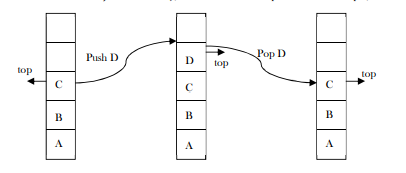
A stack is a simple data structure used for storing data (simailar to Lanked Lists). In a stack, the order in which the data arrives is important. A pile of plates in a cafeteria is a good example of a stack. The plates are added to the stack as they are cleaned and they are placed on the top. When a plate, is required it is taken from the top of the stack. The first plate placed on the stack is the last one to be used.
Definition: A stack is an ordered list in which insertion and deletion are done at one end, called top. The last clement inserted is the first one to be delcted. Hence, it is called the Last in First out (I.IFO) or Furst in Last out (FILO) list.
Special names are given to the two changes that can be made to a stack. When an clenuent is inserted in a stack, the concept is called push, and when an element is removed from the stack, the concept is called pop. Tryang to pop out an cmpty stack is called under flow and trying to push an elenueat in a full stack is called overflow. Geacrally, we treat then as exceptions. As an example, consider the snapshots of the stack.
统计代写|数据结构作业代写data structure代考|How Stacks are Used
Consider a working day in the office. Let us assume a developer is working on a long-term project. The manager then gives the developer a uew task which is maore important. The developer pusts the long term project aside and begins work on the asew tasla. The phone rings, and this is the highest pronory as it must be answered immediately. The developer pushes the present task into the peadiag tray and answers the phone.
When the call is complete the task that was abandoned to answer the phone is retrieved from the pendirg tray and work progresses. To take another call, it nay have to be handled in the sanve manner, but eventually the new task will be funished, and the developer can draw the loangtern project from the pending tray and continue with thaat.
统计代写|数据结构作业代写data structure代考|Dynamic Array Implementation
First, ket’s consider how we inplemented a simple array-based stack. We took one index variable top which points to the iadex of the most. recenthy inserted clement in the stack. To insert (or push) an element, we increment top index and then place the new element at that index.
Simalarly, to delete (or pop) an element we take the element at top index and then decrenent the top index. We represent an empty quete with top value equal to $-1$. The issue that still needs to be resolved is what we do when all the slots in the fixed size array stack are oceupicdi? First tryy What if we increment the size of the aray by 1 every time the stack is fulle?
- Pusha 0 ibcrease size of $\mathrm{S} |$ by 1
- Pop0: decrease size of Sll by 1
Issues with this approach?
This way of incrementing the array size is too expensive. Let us see the reason for this. For example, at $n=1$, to push an element create a new array of size 2 and copy all the old array elements to the new array, and at the end add the new element. At $n=2$, to push an element create a new array of size 3 and copy all the old array elements to the new array, and at the end add the new elenent.
Similarly, at $n=n-1$, if we want to push an element create a new array of size $n$ and copy all the old array elements to the new array and at the end add the new element. After $n$ push operations the total tine $T(n)$ (number of copy operations) is proportional to $1+2+\ldots+$ $n \approx \mathrm{O}\left(n^{2}\right)$.
Alternative Approach: Repeated Doubling
Let us improve the conplexity by using the array doubling technique. If the array is full, create a new array of twice the size, and copy the itens. With this approash, pushing $n$ items take time proporional to $n$ (not $n^{2}$ ).
For simplieity, let us aosune that initinlly we started waith $n=1$ and moved up to $n=32$. That means, we do the doubling at $1,2,4,8,16$. The other way of analyzing the same approach is: at $n=1$, if we want to add (push) an element, double the current size of the array and copy all the elements of the old array to the new array.
数据结构代写
统计代写|数据结构作业代写data structure代考|What is a Stack
堆栈是一种用于存储数据的简单数据结构(类似于 Lanked Lists)。在堆栈中,数据到达的顺序很重要。自助餐厅里的一堆盘子就是一个很好的例子。板在清洁时被添加到堆栈中,并放置在顶部。当需要一个盘子时,它是从堆栈的顶部取出的。放置在堆栈上的第一个板是最后一个要使用的板。
定义:堆栈是一个有序列表,其中插入和删除都在一端完成,称为顶部。最后插入的元素是第一个被删除的元素。因此,它被称为后进先出 (I.IFO) 或先入后出 (FILO) 列表。
可以对堆栈进行的两个更改具有特殊名称。当一个 clenuent 被插入堆栈时,这个概念被称为 push,当一个元素从堆栈中被移除时,这个概念被称为 pop。尝试弹出一个 cmpty 堆栈称为在 flow 下,尝试将一个 elenueat 推入一个完整的堆栈称为溢出。Geacrally,我们将其视为例外。例如,考虑堆栈的快照。
统计代写|数据结构作业代写data structure代考|How Stacks are Used
考虑在办公室的一个工作日。让我们假设开发人员正在开发一个长期项目。然后,经理给开发人员一个更重要的 uew 任务。开发商将长期项目搁置一旁,开始设计 asew tasla。电话响了,这是最高的代名词,因为必须立即接听。开发人员将当前任务推入 peadiag 托盘并接听电话。
当呼叫完成时,放弃接听电话的任务将从pendirg托盘中检索并继续工作。要接另一个电话,它必须以 sanve 的方式处理,但最终新任务将完成,开发人员可以从待处理的托盘中提取出借项目并继续执行该任务。
统计代写|数据结构作业代写data structure代考|Dynamic Array Implementation
首先,ket 考虑我们如何实现一个简单的基于数组的堆栈。我们选取了一个指向最多 iadex 的索引变量 top。最近在堆栈中插入了元素。要插入(或推送)一个元素,我们增加顶部索引,然后将新元素放置在该索引处。
同样,要删除(或弹出)一个元素,我们将顶部索引处的元素取出,然后递减顶部索引。我们表示一个空队列,其最高值等于−1. 仍然需要解决的问题是,当固定大小数组堆栈中的所有插槽都是 oceupicdi 时,我们该怎么办?首先尝试一下,如果每次堆栈满时我们将数组的大小增加 1 会怎样?
- Pusha 0 ibcrease 大小小号|1
- Pop0:将 Sll 的大小减小 1
这种方法有问题吗?
这种增加数组大小的方法太昂贵了。让我们看看这其中的原因。例如,在n=1,要推送一个元素,创建一个大小为 2 的新数组,并将所有旧数组元素复制到新数组,最后添加新元素。在n=2,要推送一个元素,创建一个大小为 3 的新数组并将所有旧数组元素复制到新数组,最后添加新元素。
同样,在n=n−1, 如果我们要推送一个元素,则创建一个新的大小数组n并将所有旧数组元素复制到新数组中,最后添加新元素。后n推操作总齿吨(n)(复制操作的次数)与1+2+…+ n≈这(n2).
替代方法:重复加倍
让我们通过使用阵列加倍技术来提高复杂性。如果数组已满,则创建一个两倍大小的新数组,并复制 itens。用这种方法,推n项目花费的时间与n(不是n2)。
为简单起见,让我们知道我们最初开始等待n=1并向上移动到n=32. 这意味着,我们在1,2,4,8,16. 分析相同方法的另一种方法是:n=1,如果我们要添加(推送)一个元素,请将数组的当前大小加倍并将旧数组的所有元素复制到新数组中。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。统计代写|python代写代考
随机过程代考
在概率论概念中,随机过程是随机变量的集合。 若一随机系统的样本点是随机函数,则称此函数为样本函数,这一随机系统全部样本函数的集合是一个随机过程。 实际应用中,样本函数的一般定义在时间域或者空间域。 随机过程的实例如股票和汇率的波动、语音信号、视频信号、体温的变化,随机运动如布朗运动、随机徘徊等等。
贝叶斯方法代考
贝叶斯统计概念及数据分析表示使用概率陈述回答有关未知参数的研究问题以及统计范式。后验分布包括关于参数的先验分布,和基于观测数据提供关于参数的信息似然模型。根据选择的先验分布和似然模型,后验分布可以解析或近似,例如,马尔科夫链蒙特卡罗 (MCMC) 方法之一。贝叶斯统计概念及数据分析使用后验分布来形成模型参数的各种摘要,包括点估计,如后验平均值、中位数、百分位数和称为可信区间的区间估计。此外,所有关于模型参数的统计检验都可以表示为基于估计后验分布的概率报表。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
statistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
机器学习代写
随着AI的大潮到来,Machine Learning逐渐成为一个新的学习热点。同时与传统CS相比,Machine Learning在其他领域也有着广泛的应用,因此这门学科成为不仅折磨CS专业同学的“小恶魔”,也是折磨生物、化学、统计等其他学科留学生的“大魔王”。学习Machine learning的一大绊脚石在于使用语言众多,跨学科范围广,所以学习起来尤其困难。但是不管你在学习Machine Learning时遇到任何难题,StudyGate专业导师团队都能为你轻松解决。
多元统计分析代考
基础数据: $N$ 个样本, $P$ 个变量数的单样本,组成的横列的数据表
变量定性: 分类和顺序;变量定量:数值
数学公式的角度分为: 因变量与自变量
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。