如果你也在 怎样代写Generalized linear model这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
广义线性模型(GLiM,或GLM)是John Nelder和Robert Wedderburn在1972年提出的一种高级统计建模技术。它是一个包括许多其他模型的总称,它允许响应变量y具有正态分布以外的误差分布。
statistics-lab™ 为您的留学生涯保驾护航 在代写Generalized linear model方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写Generalized linear model代写方面经验极为丰富,各种代写Generalized linear model相关的作业也就用不着说。
我们提供的Generalized linear model及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础

统计代写|Generalized linear model代考广义线性模型代写|Summary
Before conducting any statistical analyses, researchers must decide how to measure their variables. There is no obvious method of measuring many of the variables that interest social scientists. Therefore, researchers must give each variable an operationalization that permits them to collect numerical data.
The most common system for conceptualizing quantitative data was developed by Stevens (1946), who defined four levels of data, which are (in ascending order of complexity) nominal, ordinal, interval, and ratio-level data. Nominal data consist of mutually exclusive and exhaustive categories, which are then given an arbitrary number. Ordinal data have all of the qualities of nominal data, but the numbers in ordinal data also indicate rank order. Interval data are characterized by all the traits of nominal and ordinal data, but the spacing between numbers is equal across the entire length of the scale. Finally, ratio data are characterized by the presence of an absolute zero. This does not mean that a zero has been obtained in the data; it merely means that zero would indicate the total lack of whatever is being measured. Higher levels of data contain more information, although it is always possible to convert from one level of data to a lower level. It is not possible to convert data to a higher level than it was collected at.
It is important for us to recognize the level of data because, as Table $2.1$ indicates, there are certain mathematical procedures that require certain levels of data. For example, calculating an average requires interval or ratio data; but classifying sample members is possible for all four levels of data. Social scientists who ignore the level of their data risk producing meaningless results (like the mean gender in a sample) or distorted statistics. Using the wrong statistical methods for a level of data is considered an elementary error and a sign of flawed research.
Some researchers also classify their data as being continuous or discrete. Continuous data are data that have many possible values that span the entire length of a scale with no large gaps in possible scores. Discrete data can only have a limited number of possible values.
统计代写|Generalized linear model代考广义线性模型代写|Reflection Questions: Application
- Classify the following variables into the correct level of data (nominal, ordinal, interval, or ratio):
a. Number of Facebook friends
b. Height, measured in centimeters
c. Reaction time
d. Kelvin temperature scale
e. Race/ethnicity
f. Native language
g. Military rank
h. Celsius temperature scale
i. College major
j. Movie content ratings (e.g., $\mathrm{G}, \mathrm{PG}, \mathrm{PG}-13, \mathrm{R}, \mathrm{NC}-17$ )
k. Personality type - Hours spent watching TV per week
$\mathrm{m}$. Percentage of games an athlete plays without receiving a penalty
n. Marital status (i.e., single, married, divorced, widowed)
o. Fahrenheit temperature scale. - Label each of the examples in question $6(a-o)$ as continuous or discrete data.
- Kevin has collected data about the weight of people in his study. He couldn’t obtain their exact weight, and so he merely asked people to indicate whether they were “skinny” (labeled group 1) “average” (group 2), or “heavy” (group 3).
a. What level of data has Kevin collected?
b. Could Kevin convert his data to nominal level? Why or why not? If he can, how would he make this conversion?
c. Could Kevin convert his data to ratio level? Why or why not? If he can, how would he make this conversion? - At most universities the faculty are – in ascending seniority – adjunct (i.e., part-time) faculty, lecturers, assistant professors, associate professors, and full professors.
a. What level of data would this information be?
b. If a researcher instead collected the number of years that a faculty member has been teaching at the college level, what level of data would that be instead?
c. Of the answers to the two previous questions ( $9 \mathrm{a}$ and $9 \mathrm{~b})$, which level of data is more detailed? - What is the minimal level of data students must collect if they want to
a. classify subjects?
b. add scores together?
统计代写|Generalized linear model代考广义线性模型代写|SPSS
SPSS permits users to specify the level of data in the variable view. (See the Software Guide for Chapter 1 for information about variable view.) Figure $2.1$ shows five variables that have been entered into SPSS. Entering the name merely requires clicking a cell in the column labeled “Name” and typing in the variable name. In the column labeled “Type,” the default option is “Numeric,” which is used for data that are numbers. (Other options include “String” for text; dates; and time measurements.) The next two columns, “Width” and “Decimals” refer to the length of a variable (in terms of the number of digits). “Width” must be at least 1 digit, and “Decimals” must be a smaller number than the number entered into “Width.” In this example, the “Grade” variable has 5 digits, of which 3 are decimals and 1 (automatically) is the decimal point in the number. The “Label” column is a more detailed name that you can give a label. This is helpful if the variable name itself is too short or if the limits of SPSS’s “Name” column (e.g., no variables beginning with numbers, no spaces) are too constraining.
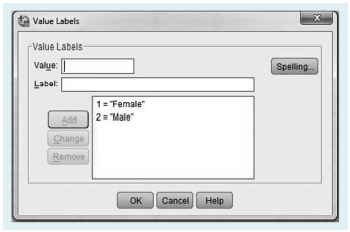
The “Values” column is very convenient for nominal and ordinal data. By clicking the cell, the user can tell SPSS what numbers correspond to the different category labels. An example of this appears in Figure 2.2. This window allows users to specify which numbers refer to the various groups within a variable. In Figure 2.2, Group 1 is for female subjects, and Group 2 is for male subjects. Clicking on “Missing” is similar, but it permits users to specify which numbers correspond to missing data. This tells SPSS to not include those numbers when performing statistical analyses so that the results are not distorted. The next two columns (labeled “Columns” and “Align”) are cosmetic; changing values in these columns will make the numbers in the data view appear differently, but will not change the data or how the computer uses them.
To change the level of data for a variable, you should use the column labeled “Measure.” Clicking a cell in this column generates a small drop-down menu with three options, “Nominal” (for nominal data), “Ordinal” (for ordinal data), and “Scale” (for interval and ratio data). Assigning a variable to the proper level of data requires selecting the appropriate option from the menu.
广义线性模型代写
统计代写|Generalized linear model代考广义线性模型代写|Summary
在进行任何统计分析之前,研究人员必须决定如何测量他们的变量。没有明显的方法可以测量社会科学家感兴趣的许多变量。因此,研究人员必须对每个变量进行操作化,以允许他们收集数值数据。
最常见的量化数据概念化系统是由 Stevens (1946) 开发的,他定义了四个级别的数据,它们是(按复杂性升序排列)名义、有序、区间和比率级别的数据。名义数据由互斥和详尽的类别组成,然后给定一个任意数字。序数数据具有名义数据的所有特性,但序数数据中的数字也表示等级顺序。区间数据的特点是名义数据和有序数据的所有特征,但数字之间的间距在整个尺度长度上是相等的。最后,比率数据的特征是存在绝对零。这并不意味着在数据中已经获得了零;它仅仅意味着零表示完全缺乏正在测量的任何东西。较高级别的数据包含更多信息,尽管始终可以从一个级别的数据转换为较低级别的数据。无法将数据转换到比收集时更高的级别。
识别数据的级别对我们来说很重要,因为,如表2.1表明,某些数学程序需要某些级别的数据。例如,计算平均值需要区间或比率数据;但是对所有四个级别的数据都可以对样本成员进行分类。忽视数据水平的社会科学家可能会产生毫无意义的结果(如样本中的平均性别)或扭曲的统计数据。对某个级别的数据使用错误的统计方法被认为是基本错误和研究有缺陷的标志。
一些研究人员还将他们的数据分类为连续的或离散的。连续数据是具有许多可能值的数据,这些值跨越量表的整个长度,可能的分数没有大的差距。离散数据只能有有限数量的可能值。
统计代写|Generalized linear model代考广义线性模型代写|Reflection Questions: Application
- 将以下变量分类为正确的数据级别(名义、有序、区间或比率)
:Facebook 好友数量
B. 高度,以厘米为单位
C. 反应时间
D. 开尔文温标
e. 种族/民族
f. 母语
g. 军衔
h. 摄氏温度标度
i。大学专业
j。电影内容分级(例如,G,磷G,磷G−13,R,ñC−17)
k. 性格类型 - 每周看电视的时间
米. 运动员未受罚的比赛的百分比
n。婚姻状况(即单身、已婚、离婚、丧偶
)华氏温标。 - 标记每个有问题的示例6(一种−这)作为连续或离散数据。
- 凯文在他的研究中收集了有关人们体重的数据。他无法获得他们的确切体重,所以他只要求人们指出他们是“瘦”(标记为第 1 组)“平均”(第 2 组)还是“重”(第 3 组)。
一种。凯文收集了什么级别的数据?
湾。凯文能否将他的数据转换为名义水平?为什么或者为什么不?如果可以,他将如何进行这种转换?
C。凯文能否将他的数据转换为比率水平?为什么或者为什么不?如果可以,他将如何进行这种转换? - 在大多数大学中,教师是——按资历递增的——兼职(即兼职)教师、讲师、助理教授、副教授和正教授。
一种。这些信息将是什么级别的数据?
湾。如果研究人员收集的是一名教员在大学任教的年数,那将是什么级别的数据?
C。前两个问题的答案(9一种和9 b),哪个级别的数据更详细? - 如果学生愿意,他们必须收集的最低数据水平是多少
?分类科目?
湾。把分数加起来?
统计代写|Generalized linear model代考广义线性模型代写|SPSS
SPSS 允许用户在变量视图中指定数据级别。(有关变量视图的信息,请参阅第 1 章的软件指南。) 图2.1显示已输入 SPSS 的五个变量。输入名称只需要单击标有“名称”的列中的单元格并输入变量名称。在标有“类型”的列中,默认选项是“数字”,用于数字数据。(其他选项包括文本的“字符串”;日期;和时间测量。)接下来的两列,“宽度”和“小数”是指变量的长度(以位数表示)。“宽度”必须至少为 1 位,“小数”必须小于“宽度”中输入的数字。在本例中,“Grade”变量有 5 位数字,其中 3 位是小数,1(自动)是数字中的小数点。“标签”列是一个更详细的名称,您可以给它一个标签。
“值”列对于名义和有序数据非常方便。通过单击单元格,用户可以告诉 SPSS 哪些数字对应于不同的类别标签。图 2.2 中显示了一个示例。此窗口允许用户指定哪些数字引用变量中的各个组。在图 2.2 中,第 1 组针对女性受试者,第 2 组针对男性受试者。单击“丢失”是类似的,但它允许用户指定哪些数字对应于丢失的数据。这告诉 SPSS 在执行统计分析时不要包含这些数字,以免结果失真。接下来的两列(标记为“列”和“对齐”)是装饰性的;更改这些列中的值将使数据视图中的数字显示不同,但不会更改数据或计算机使用它们的方式。
要更改变量的数据级别,您应该使用标有“测量”的列。单击此列中的一个单元格会生成一个包含三个选项的小型下拉菜单,“Nominal”(用于名义数据)、“Ordinal”(用于有序数据)和“Scale”(用于间隔和比率数据)。将变量分配给适当的数据级别需要从菜单中选择适当的选项。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。