如果你也在 怎样代写数据库SQL这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
结构化查询语言(SQL)是一种标准化的编程语言,用于管理关系型数据库并对其中的数据进行各种操作。
statistics-lab™ 为您的留学生涯保驾护航 在代写数据库SQL方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写数据库SQL代写方面经验极为丰富,各种代写数据库SQL相关的作业也就用不着说。
我们提供的数据库SQL及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
计算机代写|数据库作业代写SQL代考|Types of Data
Estimates of how long data scientists spend preparing their data vary, but it’s safe to say that this step takes up a significant part of the time spent working with data. In 2014 , the New York Times reported that data scientists spend from $50 \%$ to $80 \%$ of their time cleaning and wrangling their data. A 2016 survey by CrowdFlower found that data scientists spend $60 \%$ of their time cleaning and organizing data in order to prepare it for analysis or modeling work. Preparing data is such a common task that terms have sprung up to describe it, such as data munging, data wrangling, and data prep. (“Mung” is an acronym for Mash Until No Good, which I have certainly done on occasion.) Is all this data preparation work just mindless toil, or is it an important part of the process?
Data preparation is easier when a data set has a data dictionary, a document or repository that has clear descriptions of the fields, possible values, how the data was collected, and how it relates to other data. Unfortunately, this is frequently not the case. Documentation often isn’t prioritized, even by people who see its value, or it becomes out-of-date as new fields and tables are added or the way data is populated changes. Data profiling creates many of the elements of a data dictionary, so if your organization already has a data dictionary, this is a good time to use it and contribute to it. If no data dictionary exists currently, consider starting one! This is one of the most valuable gifts you can give to your team and to your future self. An up-to-date data dictionary allows you to speed up the data-profiling process by building on profiling that’s already been done rather than replicating it. It will also improve the quality of your analysis results, since you can verify that you have used fields correctly and applied appropriate filters.
Even when a data dictionary exists, you will still likely need to do data prep work as part of the analysis. In this chapter, I’ll start with a review of data types you are likely to encounter. This is followed by a review of $\mathrm{SQL}$ query structure. Next, I will talk about profiling the data as a way to get to know its contents and check for data quality. Then I’ll talk about some data-shaping techniques that will return the columns and rows needed for further analysis. Finally, I’ll walk through some useful tools for cleaning data to deal with any quality issues.
计算机代写|数据库作业代写SQL代考|Database Data Types
Fields in database tables all have defined data types. Most databases have good documentation on the types they support, and this is a good resource for any needed detail beyond what is presented here. You don’t necessarily need to be an expert on the nuances of data types to be good at analysis, but later in the book we’ll encounter situations in which considering the data type is important, so this section will cover the basics. The main types of data are strings, numeric, logical, and datetime, as summarized in Table 2-1. These are based on Postgres but are similar across most major database types.
String data types are the most versatile. These can hold letters, numbers, and special characters, including unprintable characters like tabs and newlines. String fields can be defined to hold a fixed or variable number of characters. A CHAR field could be defined to allow only two characters to hold US state abbreviations, for example, whereas a field storing the full names of states would need to be a VARCHAR to allow a variable number of characters. Fields can be defined as TEXT, CLOB (Character Large Object), or BLOB (Binary Large Object, which can include additional data types such as images), depending on the database to hold very long strings, though since they often take up a lot of space, these data types tend to be used sparingly. When data is loaded, if strings arrive that are too big for the defined data type, they may be truncated or rejected entirely. SQL has a number of string functions that we will make use of for various analysis purposes.
Numeric data types are all the ones that store numbers, both positive and negative. Mathematical functions and operators can be applied to numeric fields. Numeric data types include the INT types as well as FLOAT, DOUBLE, and DECIMAL types that allow decimal places. Integer data types are often implemented because they use less memory than their decimal counterparts. In some databases, such as Postgres, dividing integers results in an integer, rather than a value with decimal places as you might expect. We’ll discuss converting numeric data types to obtain correct results later in this chapter.
The logical data type is called BOOLEAN. It has values of TRUE and FALSE and is an efficient way to store information where these options are appropriate. Operations that compare two fields return a BOOLEAN value as a result. This data type is often used to create flags, fields that summarize the presence or absence of a property in the data. For example, a table storing email data might have a BOOLEAN has_opened field.
The datetime types include DATE, TIMESTAMP, and TIME. Date and time data should be stored in a field of one of these database types whenever possible, since SQL has a number of useful functions that operate on them. Timestamps and dates are very common in databases and are critical to many types of analysis, particularly time series analysis (covered in Chapter 3 ) and cohort analysis (covered in Chapter 4). Chapter 3 will discuss date and time formatting, transformations, and calculations.
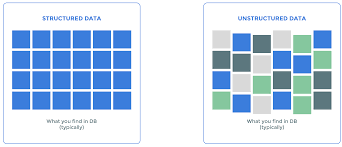
计算机代写|数据库作业代写SQL代考|Structured Versus Unstructured
Data is often described as structured or unstructured, or sometimes as semistructured. Most databases were designed to handle structured data, where each attribute is stored in a column, and instances of each entity are represented as rows. A data model is first created, and then data is inserted according to that data model. For example, an address table might have fields for street address, city, state, and postal code. Each row would hold a particular customer’s address. Each field has a data type and allows only data of that type to be entered. When structured data is inserted into a table, each field is verified to ensure it conforms to the correct data type. Structured data is easy to query with SQL.
Unstructured data is the opposite of structured data. There is no predetermined structure, data model, or data types. Unstructured data is often the “everything else” that isn’t database data. Documents, emails, and web pages are unstructured. Photos, images, videos, and audio files are also examples of unstructured data. They don’t fit into the traditional data types, and thus they are more difficult for relational databases to store efficiently and for SQL to query. Unstructured data is often stored outside of relational databases as a result. This allows data to be loaded quickly, but lack of data validation can result in low data quality. As we saw in Chapter 1 , the technology continues to evolve, and new tools are being developed to allow SQL querying of many types of unstructured data.
Semistructured data falls in between these two categories. Much “unstructured” data has some structure that we can make use of. For example, emails have from and to email addresses, subject lines, body text, and sent timestamps that can be stored separately in a data model with those fields. Metadata, or data about data, can be extracted from other file types and stored for analysis. For example, music audio files might be tagged with artist, song name, genre, and duration. Generally, the structured parts of semistructured data can be queried with $\mathrm{SQL}$, and $\mathrm{SQL}$ can often be used to parse or otherwise extract structured data for further querying. We’ll see some applications of this in the discussion of text analysis in Chapter $5 .$
SQL代考
计算机代写|数据库作业代写SQL代考|Types of Data
对数据科学家花费多长时间准备数据的估计各不相同,但可以肯定地说,这一步占用了处理数据所花费的大部分时间。2014 年,《纽约时报》报道称,数据科学家从50%至80%他们清理和整理数据的时间。CrowdFlower 2016 年的一项调查发现,数据科学家花费60%他们的时间清理和组织数据,以便为分析或建模工作做好准备。准备数据是一项如此常见的任务,以至于出现了很多术语来描述它,例如数据整理、数据整理和数据准备。(“Mung”是 Mash until No Good 的首字母缩写词,我当然有时会这样做。)所有这些数据准备工作只是盲目的辛勤工作,还是该过程的重要组成部分?
当数据集具有数据字典、文档或存储库时,数据准备会更容易,这些文档或存储库对字段、可能的值、数据的收集方式以及与其他数据的关系都有清晰的描述。不幸的是,通常情况并非如此。文档通常不会被优先考虑,即使是看到其价值的人,或者随着新字段和表的添加或数据填充方式的变化而变得过时。数据剖析创建了数据字典的许多元素,因此如果您的组织已经拥有一个数据字典,那么现在是使用它并为其做出贡献的好时机。如果当前不存在数据字典,请考虑启动一个!这是您可以送给团队和未来的自己的最有价值的礼物之一。最新的数据字典允许您通过构建已经完成的分析而不是复制它来加快数据分析过程。它还将提高分析结果的质量,因为您可以验证您是否正确使用了字段并应用了适当的过滤器。
即使存在数据字典,您仍可能需要将数据准备工作作为分析的一部分。在本章中,我将从回顾您可能会遇到的数据类型开始。紧随其后的是审查小号问大号查询结构。接下来,我将讨论通过分析数据来了解其内容并检查数据质量。然后我将讨论一些数据整形技术,这些技术将返回进一步分析所需的列和行。最后,我将介绍一些用于清理数据以处理任何质量问题的有用工具。
计算机代写|数据库作业代写SQL代考|Database Data Types
数据库表中的字段都有定义的数据类型。大多数数据库都有关于它们支持的类型的良好文档,这是一个很好的资源,可以提供超出此处介绍的任何所需详细信息。您不一定需要成为数据类型细微差别方面的专家才能擅长分析,但在本书后面我们会遇到考虑数据类型很重要的情况,因此本节将介绍基础知识。数据的主要类型是字符串、数字、逻辑和日期时间,如表 2-1 所示。这些基于 Postgres,但在大多数主要数据库类型中都是相似的。
字符串数据类型是最通用的。这些可以包含字母、数字和特殊字符,包括制表符和换行符等不可打印的字符。字符串字段可以定义为包含固定或可变数量的字符。例如,可以将 CHAR 字段定义为仅允许两个字符保存美国州的缩写,而存储州全名的字段需要是 VARCHAR 以允许可变数量的字符。字段可以定义为 TEXT、CLOB(字符大对象)或 BLOB(二进制大对象,其中可以包含其他数据类型,例如图像),这取决于数据库来保存非常长的字符串,尽管它们通常占用很多空间,这些数据类型往往被谨慎使用。加载数据时,如果到达的字符串对于定义的数据类型来说太大,它们可能会被截断或完全拒绝。SQL 有许多字符串函数,我们将使用这些函数进行各种分析。
数字数据类型是所有存储数字的类型,包括正数和负数。数学函数和运算符可以应用于数值字段。数值数据类型包括 INT 类型以及允许小数位的 FLOAT、DOUBLE 和 DECIMAL 类型。通常实现整数数据类型是因为它们使用的内存比十进制数据类型少。在某些数据库中,例如 Postgres,将整数相除会得到一个整数,而不是您可能期望的带有小数位的值。我们将在本章后面讨论转换数字数据类型以获得正确的结果。
逻辑数据类型称为 BOOLEAN。它具有 TRUE 和 FALSE 值,是在适合这些选项的位置存储信息的有效方式。比较两个字段的操作会返回一个 BOOLEAN 值作为结果。此数据类型通常用于创建标志,即汇总数据中是否存在属性的字段。例如,存储电子邮件数据的表可能具有 BOOLEAN has_opened 字段。
日期时间类型包括 DATE、TIMESTAMP 和 TIME。日期和时间数据应尽可能存储在这些数据库类型之一的字段中,因为 SQL 有许多对它们进行操作的有用函数。时间戳和日期在数据库中非常常见,对许多类型的分析至关重要,特别是时间序列分析(第 3 章介绍)和队列分析(第 4 章介绍)。第 3 章将讨论日期和时间格式、转换和计算。
计算机代写|数据库作业代写SQL代考|Structured Versus Unstructured
数据通常被描述为结构化或非结构化,或者有时被描述为半结构化。大多数数据库旨在处理结构化数据,其中每个属性都存储在一列中,并且每个实体的实例都表示为行。首先创建一个数据模型,然后根据该数据模型插入数据。例如,地址表可能包含街道地址、城市、州和邮政编码的字段。每行将包含一个特定客户的地址。每个字段都有一个数据类型,并且只允许输入该类型的数据。将结构化数据插入表中时,会验证每个字段以确保其符合正确的数据类型。结构化数据易于使用 SQL 进行查询。
非结构化数据与结构化数据相反。没有预先确定的结构、数据模型或数据类型。非结构化数据通常是不是数据库数据的“其他一切”。文档、电子邮件和网页是非结构化的。照片、图像、视频和音频文件也是非结构化数据的示例。它们不适合传统的数据类型,因此它们更难以用于关系数据库的高效存储和 SQL 查询。因此,非结构化数据通常存储在关系数据库之外。这样可以快速加载数据,但缺乏数据验证会导致数据质量低下。正如我们在第 1 章中看到的那样,技术不断发展,并且正在开发新工具以允许对多种类型的非结构化数据进行 SQL 查询。
半结构化数据介于这两类之间。许多“非结构化”数据都有一些我们可以利用的结构。例如,电子邮件具有发件人和收件人电子邮件地址、主题行、正文和发送时间戳,这些时间戳可以单独存储在具有这些字段的数据模型中。元数据或有关数据的数据可以从其他文件类型中提取并存储以供分析。例如,音乐音频文件可能带有艺术家、歌曲名称、流派和持续时间的标签。一般来说,半结构化数据的结构化部分可以用小号问大号, 和小号问大号通常可用于解析或以其他方式提取结构化数据以进行进一步查询。我们将在第 1 章的文本分析讨论中看到它的一些应用。5.

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。