如果你也在 怎样代写数据库SQL这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
结构化查询语言(SQL)是一种标准化的编程语言,用于管理关系型数据库并对其中的数据进行各种操作。
statistics-lab™ 为您的留学生涯保驾护航 在代写数据库SQL方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写数据库SQL代写方面经验极为丰富,各种代写数据库SQL相关的作业也就用不着说。
我们提供的数据库SQL及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
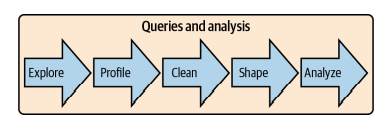
计算机代写|数据库作业代写SQL代考|SQL Versus R or Python
While SQL is a popular language for data analysis, it isn’t the only choice. $R$ and Python are among the most popular of the other languages used for data analysis. $R$ is a statistical and graphing language, while Python is a general-purpose programming language that has strengths in working with data. Both are open source, can be installed on a laptop, and have active communities developing packages, or extensions, that tackle various data manipulation and analysis tasks. Choosing between $R$ and Python is beyond the scope of this book, but there are many discussions online about the relative advantages of each. Here I will consider them together as codinglanguage alternatives to $\mathrm{SQL}$.
One major difference between SQL and other coding languages is where the code runs and, therefore, how much computing power is available. $\mathrm{SQL}$ always runs on a database server, taking advantage of all its computing resources. For doing analysis, $R$ and Python are usually run locally on your machine, so computing resources are capped by whatever is available locally. There are, of course, lots of exceptions: databases can run on laptops, and R and Python can be run on servers with more resources. When you are performing anything other than the simplest analysis on large data sets, pushing work onto a database server with more resources is a good option. Since databases are usually set up to continually receive new data, SQL is also a good choice when a report or dashboard needs to update periodically.
A second difference is in how data is stored and organized. Relational databes always organize data into rows and columns within tables, so SQL assumes this structure for every query. $\mathrm{R}$ and Python have a wider variety of ways to store data, including variables, lists, and dictionaries, among other options. These provide more flexibility, but at the cost of a steeper learning curve. To facilitate data analysis, $R$ has data frames, which are similar to database tables and organize data into rows and columns. The pandas package makes DataFrames available in Python. Even when other options are available, the table structure remains valuable for analysis.
Looping is another major difference between SQL and most other computer programming languages. A loop is an instruction or a set of instructions that repeats until a specified condition is met. SQL aggregations implicitly loop over the set of data, without any additional code. We will see later how the lack of ability to loop over fields can result in lengthy SQL statements when pivoting or unpivoting data. While deeper discussion is beyond the scope of this book, some vendors have created extensions to SQL, such as PL/SQL in Oracle and T-SQL in Microsoft SQL Server, that allow functionality such as looping.
计算机代写|数据库作业代写SQL代考|SQL as Part of the Data Analysis Workflow
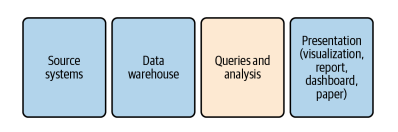
Now that I’ve explained what SQL is, discussed some of its benefits, and compared it to other languages, we’ll turn to a discussion of where SQL fits in the data analysis process. Analysis work always starts with a question, which may be about how many new customers have been acquired, how sales are trending, or why some users stick around for a long time while others try a service and never return. Once the question is framed, we consider where the data originated, where the data is stored, the analysis plan, and how the results will be presented to the audience. Figure 1-2 shows the steps in the process. Queries and analysis are the focus of this book, though I will discuss the other steps briefly in order to put the queries and analysis stage into a broader context.
First, data is generated by source systems, a term that includes any human or machine process that generates data of interest. Data can be generated by people by hand, such as when someone fills out a form or takes notes during a doctor’s visit. Data can also be machine generated, such as when an application database records a purchase, an event-streaming system records a website click, or a marketing management tool records an email open. Source systems can generate many different types and formats of data, and Chapter 2 will discuss them, and how the type of source may impact the analysis, in more detail.
The second step is moving the data and storing it in a database for analysis. I will use the terms data warehouse, which is a database that consolidates data from across an organization into a central repository, and data store, which refers to any type of data storage system that can be queried. Other terms you might come across are data mart, which is typically a subset of a data warehouse, or a more narrowly focused data warehouse; and data lake, a term that can mean either that data resides in a file storage system or that it is stored in a database but without the degree of data transformation that is common in data warehouses. Data warehouses range from small and simple to huge and expensive. A database running on a laptop will be sufficient for you to follow along with the examples in this book. What matters is having the data you need to perform an analysis together in one place.
计算机代写|数据库作业代写SQL代考|Database Types and How to Work with Them
If you’re working with SQL, you’ll be working with databases. There is a range of database types-open source to proprietary, row-store to column-store. There are onpremises databases and cloud databases, as well as hybrid databases, where an organization runs the database software on a cloud vendor’s infrastructure. There are also a number of data stores that aren’t databases at all but can be queried with SQL.
Databases are not all created equal; each database type has its strengths and weaknesses when it comes to analysis work. Unlike tools used in other parts of the analysis workflow, you may not have much say in which database technology is used in your organization. Knowing the ins and outs of the database you have will help you work more efficiently and take advantage of any special SQL functions it offers. Familiarity with other types of databases will help you if you find yourself working on a project to build or migrate to a new data warehouse. You may want to install a database on your laptop for personal, small-scale projects, or get an instance of a cloud warehouse for similar reasons.
Databases and data stores have been a dynamic area of technology development since they were introduced. A few trends since the turn of the 21 st century have driven the technology in ways that are really exciting for data practitioners today. First, data volumes have increased incredibly with the internet, mobile devices, and the Internet of Things (IoT). In 2020 IDC predicted that the amount of data stored globally will grow to 175 zettabytes by 2025 . This scale of data is hard to even think about, and not all of it will be stored in databases for analysis. It’s not uncommon for companies to have data in the scale of terabytes and petabytes these days, a scale that would have been impossible to process with the technology of the 1990 s and earlier. Second, decreases in data storage and computing costs, along with the advent of the cloud,
have made it cheaper and easier for organizations to collect and store these massive amounts of data. Computer memory has gotten cheaper, meaning that large amounts of data can be loaded into memory, calculations performed, and results returned, all without reading and writing to disk, greatly increasing the speed. Third, distributed compuling has alluwed the breaking up of wurkluads acruss many machines. This allows a large and tunable amount of computing to be pointed to complex data tasks.
Databases and data stores have combined these technological trends in a number of different ways in order to optimize for particular types of tasks. There are two broad categories of databases that are relevant for analysis work: row-store and columnstore. In the next section I’ll introduce them, discuss what makes them similar to and different from each other, and talk about what all of this means as far as doing analysis with data stored in them. Finally, I’ll introduce some additional types of data infrastructure beyond databases that you may encounter.
SQL代考
计算机代写|数据库作业代写SQL代考|SQL Versus R or Python
虽然 SQL 是一种流行的数据分析语言,但它并不是唯一的选择。R和 Python 是最流行的用于数据分析的其他语言之一。R是一种统计和图形语言,而 Python 是一种通用编程语言,在处理数据方面具有优势。两者都是开源的,可以安装在笔记本电脑上,并且有活跃的社区开发包或扩展,以解决各种数据操作和分析任务。之间进行选择R和 Python 超出了本书的范围,但是网上有很多关于各自相对优势的讨论。在这里,我将它们一起视为编码语言的替代品小号问大号.
SQL 和其他编码语言之间的一个主要区别是代码运行的位置,因此,有多少计算能力可用。小号问大号始终在数据库服务器上运行,利用其所有计算资源。为了进行分析,R和 Python 通常在您的机器上本地运行,因此计算资源受本地可用资源的限制。当然,也有很多例外:数据库可以在笔记本电脑上运行,R 和 Python 可以在资源更多的服务器上运行。当您对大型数据集执行最简单的分析以外的任何操作时,将工作推送到具有更多资源的数据库服务器上是一个不错的选择。由于数据库通常设置为不断接收新数据,因此当报表或仪表板需要定期更新时,SQL 也是一个不错的选择。
第二个区别在于数据的存储和组织方式。关系数据库总是将数据组织成表中的行和列,因此 SQL 对每个查询都采用这种结构。RPython 有更多种类的数据存储方式,包括变量、列表和字典等。这些提供了更大的灵活性,但代价是更陡峭的学习曲线。为了方便数据分析,R具有数据框,类似于数据库表,将数据组织成行和列。pandas 包使 DataFrames 在 Python 中可用。即使有其他选项可用,表结构仍然对分析很有价值。
循环是 SQL 和大多数其他计算机编程语言之间的另一个主要区别。循环是重复的指令或一组指令,直到满足指定条件。SQL 聚合隐式循环数据集,无需任何额外代码。稍后我们将看到在对数据进行透视或反透视时,缺乏循环遍历字段的能力如何导致冗长的 SQL 语句。虽然更深入的讨论超出了本书的范围,但一些供应商已经创建了 SQL 的扩展,例如 Oracle 中的 PL/SQL 和 Microsoft SQL Server 中的 T-SQL,它们允许诸如循环之类的功能。
计算机代写|数据库作业代写SQL代考|SQL as Part of the Data Analysis Workflow
既然我已经解释了 SQL 是什么,讨论了它的一些好处,并将它与其他语言进行了比较,我们将转向讨论 SQL 在数据分析过程中的位置。分析工作总是从一个问题开始,这可能是关于获得了多少新客户,销售趋势如何,或者为什么有些用户会坚持很长时间,而另一些用户却尝试了一项服务却再也没有回来。一旦提出问题,我们就会考虑数据的来源、数据的存储位置、分析计划以及如何将结果呈现给观众。图 1-2 显示了该过程中的步骤。查询和分析是本书的重点,但我将简要讨论其他步骤,以便将查询和分析阶段置于更广泛的背景中。
首先,数据由源系统生成,该术语包括任何生成感兴趣数据的人或机器过程。数据可以由人们手动生成,例如当有人填写表格或在医生就诊期间做笔记时。数据也可以是机器生成的,例如当应用程序数据库记录购买、事件流系统记录网站点击或营销管理工具记录电子邮件打开时。源系统可以生成许多不同类型和格式的数据,第 2 章将更详细地讨论它们,以及源类型如何影响分析。
第二步是移动数据并将其存储在数据库中进行分析。我将使用术语数据仓库,它是一个将来自整个组织的数据整合到中央存储库中的数据库,以及数据存储,它指的是可以查询的任何类型的数据存储系统。您可能会遇到的其他术语是数据集市,它通常是数据仓库的一个子集,或更狭义的数据仓库;和数据湖,这个术语可以表示数据要么驻留在文件存储系统中,要么存储在数据库中,但没有数据仓库中常见的数据转换程度。数据仓库的范围从小而简单到巨大而昂贵。在笔记本电脑上运行的数据库足以让您按照本书中的示例进行操作。
计算机代写|数据库作业代写SQL代考|Database Types and How to Work with Them
如果您使用 SQL,那么您将使用数据库。有一系列数据库类型——从开源到专有,从行存储到列存储。有本地数据库和云数据库,以及混合数据库,组织在云供应商的基础架构上运行数据库软件。还有一些数据存储根本不是数据库,但可以使用 SQL 进行查询。
数据库并非都是平等的;在分析工作中,每种数据库类型都有其优势和劣势。与分析工作流程的其他部分中使用的工具不同,您可能没有太多发言权,您的组织中使用了哪种数据库技术。了解您拥有的数据库的来龙去脉将帮助您更有效地工作,并利用它提供的任何特殊 SQL 函数。如果您发现自己正在从事构建或迁移到新数据仓库的项目,那么熟悉其他类型的数据库将对您有所帮助。您可能希望在笔记本电脑上为个人小型项目安装数据库,或出于类似原因获取云仓库实例。
数据库和数据存储自推出以来一直是技术发展的动态领域。自 21 世纪之交以来,一些趋势以对当今数据从业者来说真正令人兴奋的方式推动了这项技术。首先,随着互联网、移动设备和物联网 (IoT) 的发展,数据量急剧增加。2020 年 IDC 预测,到 2025 年,全球存储的数据量将增长到 175 zettabytes。这种规模的数据甚至难以想象,而且并非所有数据都将存储在数据库中进行分析。如今,公司拥有 TB 级和 PB 级的数据并不少见,这是 1990 年代及更早的技术无法处理的规模。其次,随着云的出现,数据存储和计算成本降低,
使组织收集和存储这些海量数据变得更便宜、更容易。计算机内存变得越来越便宜,这意味着可以将大量数据加载到内存中,执行计算并返回结果,而无需读取和写入磁盘,大大提高了速度。第三,分布式计算已经允许分散许多机器上的 wurkluads。这允许将大量可调整的计算指向复杂的数据任务。
数据库和数据存储以多种不同的方式结合了这些技术趋势,以便针对特定类型的任务进行优化。与分析工作相关的数据库有两大类:行存储和列存储。在下一节中,我将介绍它们,讨论是什么使它们彼此相似和不同,并讨论所有这些对于使用存储在其中的数据进行分析的意义。最后,我将介绍一些您可能会遇到的数据库之外的其他类型的数据基础设施。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。