统计代写|商业分析作业代写Statistical Modelling for Business代考|Probability sampling
如果你也在 怎样代写商业分析Statistical Modelling for Business这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
商业分析就是利用数据分析和统计的方法,来分析企业之前的商业表现,从而通过分析结果来对未来的商业战略进行预测和指导 。
statistics-lab™ 为您的留学生涯保驾护航 在代写商业分析Statistical Modelling for Business方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写商业分析Statistical Modelling for Business方面经验极为丰富,各种代写商业分析Statistical Modelling for Business相关的作业也就用不着说。
我们提供的商业分析Statistical Modelling for Business及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等楖率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|商业分析作业代写Statistical Modelling for Business代考|Probability sampling
Random (or approximately random) sampling-as well as the more advanced kinds of sampling discussed in optional Section 1.7–are types of probability sampling. In general, probability sampling is sampling where we know the chance (or probability) that each element in the population will be included in the sample. If we employ probability sampling, the sample obtained can be used to make valid statistical inferences about the sampled population. However, if we do not employ probability sampling, we cannot make valid statistical inferences.
One type of sampling that is not probability sampling is convenience sampling, where we select elements because they are easy or convenient to sample. For example, if we select people to interview because they look “nice” or “pleasant,” we are using convenience sampling. Another example of convenience sampling is the use of voluntary response samples, which are frequently employed by television and radio stations and newspaper columnists. In such samples, participants self-select-that is, whoever wishes to participate does so (usually expressing some opinion). These samples overrepresent people with strong (usually negative) opinions. For example, the advice columnist Ann Landers once asked her readers, “If you had it to do over again, would you have children?” Of the nearly 10,000 parents who voluntarily responded, 70 percent said that they would not. A probability sample taken a few months later found that 91 percent of parents would have children again.
Another type of sampling that is not probability sampling is judgment sampling, where a person who is extremely knowledgeable about the population under consideration selects population elements that he or she feels are most representative of the population. Because the quality of the sample depends upon the judgment of the person selecting the sample, it is dangerous to use the sample to make statistical inferences about the population.
To conclude this section, we consider a classic example where two types of sampling errors doomed a sample’s ability to make valid statistical inferences. This example occurred prior to the presidential election of 1936 , when the Literary Digest predicted that Alf Landon would defeat Franklin D. Roosevelt by a margin of 57 percent to 43 percent. Instead, Roosevelt won the election in a landslide. Literary Digest’s first error was to send out sample ballots (actually, 10 million ballots) to people who were mainly selected from the Digest’s subscription list and from telephone directories. In 1936 the country had not yet recovered from the Great Depression, and many unemployed and low-income people did not have phones or subscribe to the Digest. The Digest’s sampling procedure excluded these people, who overwhelmingly voted for Roosevelt. Second, only $2.3$ million ballots were returned, resulting in the sample being a voluntary response survey. At the same time, George Gallup, founder of the Gallup Poll, was beginning to establish his survey business. He used a probability sample to correctly predict Roosevelt’s victory. In optional Section $1.8$ we discuss various issues related to designing surveys and more about the errors that can occur in survey samples.
统计代写|商业分析作业代写Statistical Modelling for Business代考|Ethical guidelines for statistical practice
The American Statistical Association, the leading U.S. professional statistical association, has developed the report “Ethical Guidelines for Statistical Practice.” 11 This report provides information that helps statistical practitioners to consistently use ethical statistical practices
and that helps users of statistical information avoid being misled by unethical statistical practices. Unethical statistical practices can take a variety of forms, including:
- Improper sampling Purposely selecting a biased sample_for example, using a nonrandom sampling procedure that overrepresents population elements supporting a desired conclusion or that underrepresents population elements not supporting the desired conclusion-is unethical. In addition, discarding already sampled population elements that do not support the desired conclusion is unethical. More will be said about proper and improper sampling later in this chapter.
- Misleading charts, graphs, and descriptive measures In Section 2.7, we will present an example of how misleading charts and graphs can distort the perception of changes in salaries over time. Using misleading charts or graphs to make the salary changes seem much larger or much smaller than they really are is unethical. In Section 3.1, we will present an example illustrating that many populations of individual or household incomes contain a small percentage of very high incomes. These very high incomes make the population mean income substantially larger than the population median income. In this situation we will see that the population median income is a better measure of the typical income in the population. Using the population mean income to give an inflated perception of the typical income in the population is unethical.
- Inappropriate statistical analysis or inappropriate interpretation of statistical results The American Statistical Association report emphasizes that selecting many different samples and running many different tests can eventually (by random chance alone) produce a result that makes a desired conclusion seem to be true, when the conclusion really isn’t true. Therefore, continuing to sample and run tests until a desired conclusion is obtained and not reporting previously obtained results that do not support the desired conclusion is unethical. Furthermore, we should always report our sampling procedure and sample size and give an estimate of the reliability of our statistical results. Estimating this reliability will be discussed in Chapter 7 and beyond.
The above examples are just an introduction to the important topic of unethical statistical practices. The American Statistical Association report contains 67 guidelines organized into eight areas involving general professionalism and ethical responsibilities. These include responsibilities to clients, to research team colleagues, to research subjects, and to other statisticians, as well as responsibilities in publications and testimony and responsibilities of those who employ statistical practitioners.
统计代写|商业分析作业代写Statistical Modelling for Business代考|Business Analytics and Data Mining
Big data, which sometimes needs quick (sometimes almost real-time) analysis for effective business decision making and which may be too massive to be analyzed by traditional statistical methods, has resulted in an extension of traditional statistics called business analytics. In general, business analytics might be defined as the use of traditional and newly developed statistical methods, advances in information systems, and techniques from management science to continuously and iteratively explore and investigate past business performance, with the purpose of gaining insight and improving business planning and operations. There are three broad categories of business analytics: descriptive analytics, predictive analytics, and prescriptive analytics.
Descriptive analytics
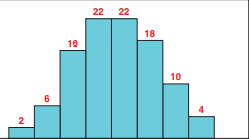
In previous examples we have introduced dot plots, time series plots, bar charts, and histograms and illustrated their use in graphically displaying data. These and other traditional graphicalmethods for displaying data are fully discussed in Chapter 2 . These methods, and more recently developed statistical display techniques designed to take advantage of the dramatic advances in data capture, transmission and storage, make up the toolset of descriptive analytics. Descriptive analytics uses the traditional and or newer graphics to present to executives (and sometimes customers) easy-to-understand visual summaries of up-to-the minute information concerning the operational status of a business. In optional Section $2.8$, we will discuss some of the new graphics, which include gauges, bullet graphs, treemaps, and sparklines. We will also see how they are used with each other and more traditional graphics to form analytic dushbourds, which are part of execuive injormaion sysiems. As an example of une of the new graphics-the bullet graph -we again consider the Disney Parks Case.
金融中的随机方法代写
统计代写|商业分析作业代写Statistical Modelling for Business代考|Probability sampling
随机(或近似随机)抽样——以及可选的第 1.7 节中讨论的更高级的抽样类型——是概率抽样的类型。一般来说,概率抽样是在我们知道总体中每个元素将包含在样本中的机会(或概率)的情况下进行抽样。如果我们采用概率抽样,则获得的样本可用于对抽样总体做出有效的统计推断。但是,如果我们不采用概率抽样,我们就无法做出有效的统计推断。
一种不是概率抽样的抽样是便利抽样,我们选择元素是因为它们容易或方便抽样。例如,如果我们选择面试的人是因为他们看起来“不错”或“令人愉快”,那么我们使用的是便利抽样。便利抽样的另一个例子是自愿响应样本的使用,电视和广播电台以及报纸专栏作家经常使用这些样本。在这样的样本中,参与者是自我选择的——也就是说,谁愿意参与(通常是表达一些意见)。这些样本过多地代表了具有强烈(通常是负面)意见的人。例如,建议专栏作家安兰德斯曾经问她的读者,“如果重来一次,你会生孩子吗?” 在近万名自愿响应的家长中,70% 的人说他们不会。几个月后采集的概率样本发现,91% 的父母会再次生育孩子。
另一种不是概率抽样的抽样是判断抽样,一个对所考虑的人口非常了解的人选择他或她认为最能代表人口的人口元素。因为样本的质量取决于选择样本的人的判断,所以使用样本对总体进行统计推断是危险的。
为了结束本节,我们考虑一个经典示例,其中两种类型的抽样误差注定了样本做出有效统计推断的能力。这个例子发生在 1936 年总统大选之前,当时《文学文摘》预测阿尔夫·兰登将以 57% 对 43% 的优势击败富兰克林·D·罗斯福。相反,罗斯福以压倒性优势赢得了选举。文学文摘的第一个错误是向主要从文摘订阅名单和电话簿中选出的人发送样本选票(实际上是 1000 万张选票)。1936 年,该国尚未从大萧条中恢复过来,许多失业者和低收入者没有电话,也没有订阅《文摘》。《文摘》的抽样程序排除了这些以压倒性多数投票给罗斯福的人。第二,2.3100 万张选票被退回,因此样本是一项自愿响应调查。与此同时,盖洛普民意调查的创始人乔治盖洛普开始建立他的调查业务。他使用概率样本来正确预测罗斯福的胜利。在可选部分1.8我们讨论了与设计调查相关的各种问题,以及更多关于调查样本中可能出现的错误。
统计代写|商业分析作业代写Statistical Modelling for Business代考|Ethical guidelines for statistical practice
美国领先的专业统计协会美国统计协会制定了报告“统计实践的道德准则”。11 本报告提供的信息有助于统计从业人员始终如一地使用符合道德的统计实践
这有助于统计信息的用户避免被不道德的统计做法误导。不道德的统计做法可以采取多种形式,包括:
- 抽样不当 故意选择有偏差的样本(例如,使用非随机抽样程序,该程序过度代表支持预期结论的总体元素或未充分代表不支持预期结论的总体元素)是不道德的。此外,丢弃不支持预期结论的已抽样人口元素是不道德的。本章稍后将详细介绍正确和不正确的抽样。
- 误导性图表、图表和描述性度量 在第 2.7 节中,我们将展示一个示例,说明误导性图表和图表如何扭曲对工资随时间变化的看法。使用误导性图表或图表使工资变化看起来比实际大得多或小得多是不道德的。在第 3.1 节中,我们将展示一个示例,说明许多个人或家庭收入人群中只有一小部分收入非常高。这些非常高的收入使人口平均收入大大高于人口平均收入。在这种情况下,我们将看到人口中位数收入是衡量人口典型收入的更好指标。使用人口平均收入来夸大人口中的典型收入是不道德的。
- 不恰当的统计分析或对统计结果的不恰当解释 美国统计协会的报告强调,选择许多不同的样本并运行许多不同的测试最终会(仅凭随机机会)产生一个结果,使期望的结论看起来是真实的,而结论确实不是真的。因此,继续采样和运行测试直到获得所需的结论,并且不报告先前获得的不支持所需结论的结果是不道德的。此外,我们应该始终报告我们的抽样程序和样本量,并估计我们的统计结果的可靠性。估计这种可靠性将在第 7 章及以后讨论。
上述示例只是对不道德统计实践这一重要主题的介绍。美国统计协会的报告包含 67 条指南,分为涉及一般专业精神和道德责任的八个领域。其中包括对客户、研究团队同事、研究对象和其他统计人员的责任,以及对出版物和证词的责任以及雇用统计从业人员的责任。
统计代写|商业分析作业代写Statistical Modelling for Business代考|Business Analytics and Data Mining
大数据有时需要快速(有时几乎是实时)分析以进行有效的业务决策,并且可能太大而无法通过传统统计方法进行分析,这导致了传统统计的扩展,称为业务分析。一般而言,业务分析可以定义为使用传统和新开发的统计方法、信息系统的进步以及管理科学技术,以不断迭代地探索和调查过去的业务绩效,目的是获得洞察力和改进业务规划和操作。业务分析分为三大类:描述性分析、预测性分析和规范性分析。
描述性分析
在前面的示例中,我们介绍了点图、时间序列图、条形图和直方图,并说明了它们在图形显示数据中的用途。第 2 章全面讨论了这些和其他用于显示数据的传统图形方法。这些方法,以及最近开发的旨在利用数据捕获、传输和存储方面的巨大进步的统计显示技术,构成了描述性分析的工具集。描述性分析使用传统和/或更新的图形向高管(有时是客户)呈现易于理解的关于企业运营状态的最新信息的视觉摘要。在可选部分2.8,我们将讨论一些新的图形,包括仪表、子弹图、树状图和迷你图。我们还将看到它们如何相互使用,以及如何使用更传统的图形来形成分析 dushbourds,这是 execuive injormaion 系统的一部分。作为新图形的一个例子——子弹图——我们再次考虑迪斯尼公园案例。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。统计代写|python代写代考
随机过程代考
在概率论概念中,随机过程是随机变量的集合。 若一随机系统的样本点是随机函数,则称此函数为样本函数,这一随机系统全部样本函数的集合是一个随机过程。 实际应用中,样本函数的一般定义在时间域或者空间域。 随机过程的实例如股票和汇率的波动、语音信号、视频信号、体温的变化,随机运动如布朗运动、随机徘徊等等。
贝叶斯方法代考
贝叶斯统计概念及数据分析表示使用概率陈述回答有关未知参数的研究问题以及统计范式。后验分布包括关于参数的先验分布,和基于观测数据提供关于参数的信息似然模型。根据选择的先验分布和似然模型,后验分布可以解析或近似,例如,马尔科夫链蒙特卡罗 (MCMC) 方法之一。贝叶斯统计概念及数据分析使用后验分布来形成模型参数的各种摘要,包括点估计,如后验平均值、中位数、百分位数和称为可信区间的区间估计。此外,所有关于模型参数的统计检验都可以表示为基于估计后验分布的概率报表。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
statistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
机器学习代写
随着AI的大潮到来,Machine Learning逐渐成为一个新的学习热点。同时与传统CS相比,Machine Learning在其他领域也有着广泛的应用,因此这门学科成为不仅折磨CS专业同学的“小恶魔”,也是折磨生物、化学、统计等其他学科留学生的“大魔王”。学习Machine learning的一大绊脚石在于使用语言众多,跨学科范围广,所以学习起来尤其困难。但是不管你在学习Machine Learning时遇到任何难题,StudyGate专业导师团队都能为你轻松解决。
多元统计分析代考
基础数据: $N$ 个样本, $P$ 个变量数的单样本,组成的横列的数据表
变量定性: 分类和顺序;变量定量:数值
数学公式的角度分为: 因变量与自变量
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。