统计代写|SPSS代写代考|Operational definitions
如果你也在 怎样代写SPSS这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
SPSS主要用于数据管理、高级分析、多变量分析、商业智能。
statistics-lab™ 为您的留学生涯保驾护航 在代写SPSS方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写SPSS方面经验极为丰富,各种代写SPSS相关的作业也就用不着说。
我们提供的SPSS及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等楖率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础

统计代写|SPSS代写代考|Operational definitions
In designing a study, researchers will determine what variables they are interested in measuring. For example, they might want to measure self-efficacy, student motivation, academic achievement, psychological well-being, racial bias, heterosexism, or any number of other ideas. An important first step in designing good research is to carefully define what those variables mean for the purpose of a given study. When researchers say, for example, they want to measure motivation, they might mean any of several dozen things by that. There are at least four major theories of human motivation, each of which might have a dozen or more constructs within them. A researcher would need to carefully define which theory of motivation they are mobilizing and which variables/constructs within that theory they intend to measure. If a researcher wants to measure racial bias, they will need to define exactly what they mean by racial bias and how they will differentiate various aspects of what might be called bias (implicit bias, discrimination, racialized beliefs, etc.). If a researcher wants to study academic achievement, they might select grade point averages (which are very problematic measures due to variance from school to school and teacher to teacher, along with grade inflation), standardized test scores like SAT or ACT (which are problematic in that they show evidence of racial bias and bias based on income), or a psychological instrument like the Wide-Range Achievement Test (WRAT, which also shows some evidence of cultural bias). However, the research defines the variable and measures it will affect the nature of the results and what they mean. The way that researchers define the variable or construct of interest is referred to as the operational definition. It’s an operational definition because it may not be perfect or permanent, but it is the definition from which the researcher is operating for a given project.
Part of operationally defining a variable involves deciding how it will be measured. Many variables could be measured in multiple ways. In fact, for any given variable, there might be dozens of different measures in common use in the research literature. Each will differ in how the variable is defined, what kinds of questions are asked, and how the ideas are conceptualized. Researchers have a tendency to at times write about variables and measures as if they were interchangeable. They might include statements like,”Self-efficacy was higher in the experimental group” when what they actually mean is that a particular measure for self-efficacy in a particular moment was higher for the experimental group. As we advocate later in this chapter, most researchers will be well served to select existing measures for their variables. But the selection of a way to measure a variable is a part of, and should align with, the operational definition.
统计代写|SPSS代写代考|Random assignment
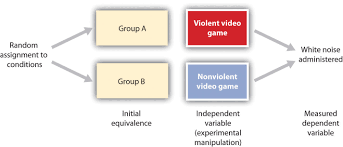
Another key term in research design is random assignment. In random assignment, everyone in the study sample has an equal probability of ending up in the various experimental groups. For example, in a design where one group gets an experimental treatment and the other group gets a placebo treatment, each participant would have a $50 / 50$ chance of ending up in the experimental vs. control group. This is accomplished by randomly assigning participants to groups. In many modern studies, the random assignment is done by software programs, some of which are built into online survey platforms. Random assignment might also be done by drawing or by placing participants in groups by the order the sign up for the study (e.g.s putting even-numbered sign ups in group 1 and odd in group 2).
Random assignment matters for the kinds of inferences a researcher can draw from a given set of results. By randomly assigning participants to groups, theoretically their background characteristics and other factors are also randomized to groups. So, the only systematic difference between groups will be the treatment or conditions supplied by group membership. As a result, the inferences can be stronger. We would feel more confident that differences between groups are due to group membership (or experimental treatment) when the groups were randomly assigned, because there are theoretically no other systematic differences between the groups. When researchers use intact groups (groups that are not or cannot be randomly assigned), the inferences will be somewhat weaker. For example, if we compare academic achievement at School $\mathrm{A}$, which uses computerized mathematics instruction, vs. School B, which uses traditional mathematics instruction, there might be lots of other differences between the two schools other than whether they use computerized instruction. Perhaps School A also has a higher budget, or students with greater access to resources, or more experienced teachers. It would be harder, given these intact groups, to attribute the difference to instruction type than if students were randomly assigned to instruction type.
Random assignment, though, is not sufficient to establish a causal claim (that a certain variable caused the outcome). Causal claims require robust evidence. For a causal claim to be supported, there must be: (1) A theoretical rationale for why the potential causal variable would cause the outcome; (2) The causal variable must precede the outcome in time (which usually means a longitudinal design); (3) There must be a reliable change in the outcome based on the potential causal variable; (4) All other potential causal variables must be eliminated or controlled (Pedhazur, 1997). Random assignment helps with criterion #4, but the others would also need to be met for a causal claim.
One distinction to be clear about, as it can be confusing for some students, is that random assignment and random sampling (described earlier in this chapter) are two separate processes that are not dependent on one another. Random sampling means everyone in the population has an equal chance of being in the sample. Random assignment means everyone in the sample has an equal chance of being in each group. They both involve randomness but for separate parts of the process.
统计代写|SPSS代写代考|Experimental vs. correlational research
The key difference between experimental and correlational (or observational) research is random assignment. Experimental research involves random assignment, whereas correlational research does not. We have described some of the advantages of experimental research in the kinds of inferences that can be made. Why, then, do researchers do correlational work? The simple answer is that lots of variables researchers might be interested in either cannot or should not be randomly assigned. Some variables should not be ethically or legally randomly assigned. If researchers already know or have strong evidence to believe that a treatment would harm participants, they cannot randomly assign them to that treatment. So, if a researcher wants to examine the effects of smoking tobacco while pregnant on infant brain development, they cannot randomly assign some pregnant women to smoke tobacco, because it causes known harms. Instead, they would likely study infants of women who smoked while pregnant before the study even began. Other variables simply cannot be randomly assigned. If a researcher wants to study gender differences in science, technology, engineering, and mathematics (STEM) degree attainment, the researcher cannot randomly assign participants to gender identities. Although gender identities may be fluid, they cannot be manipulated by the researcher. So, the researcher will study based on existing gender identity groups. That is the only practical approach. But people in different gender identities also have a whole range of other divergent experiences. People are socialized differently based on perceived or self-identified gender identities, they receive different kinds of feedback from parents, peers, and educators, and might be subjected to different kinds of STEM-related experiences. So, it would be difficult to attribute differences in STEM degree attainment to gender, but researchers might try to understand mechanisms that drive differences that occur along gendered lines.
Because many variables cannot or should not be randomly assigned, much of the work in educational and behavioral research is correlational or observational. Causal inferences are still possible, though somewhat harder than with experimental methods. Some of the most important and influential work has been correlational. Our point here is that experimental vs. correlational research is not a hierarchy-neither approach is “better,” but they offer different strengths and opportunities and have different limitations.
SPSS代写
统计代写|SPSS代写代考|Operational definitions
在设计研究时,研究人员将确定他们有兴趣测量的变量。例如,他们可能想要衡量自我效能、学生动机、学业成就、心理健康、种族偏见、异性恋或其他任何想法。设计好的研究的一个重要的第一步是仔细定义这些变量对给定研究的意义。例如,当研究人员说他们想要衡量动机时,他们可能意味着几十件事中的任何一个。至少有四种主要的人类动机理论,每一种都可能有十几个或更多的结构。研究人员需要仔细定义他们正在动员的动机理论以及他们打算测量的理论中的哪些变量/结构。如果研究人员想要衡量种族偏见,他们将需要准确定义种族偏见的含义以及他们如何区分可能被称为偏见的各个方面(隐性偏见、歧视、种族化信仰等)。如果研究人员想研究学业成绩,他们可能会选择平均成绩(这是非常有问题的衡量标准,因为学校与学校和教师之间的差异,以及分数膨胀)、SAT 或 ACT 等标准化考试成绩(这是有问题的因为他们显示了种族偏见和基于收入的偏见的证据),或者像广泛成就测试(WRAT,它也显示了一些文化偏见的证据)这样的心理工具。但是,该研究定义了变量并测量它将影响结果的性质及其含义。研究人员定义感兴趣的变量或构造的方式称为操作定义。这是一个可操作的定义,因为它可能不是完美的或永久的,但它是研究人员为给定项目进行操作的定义。
在操作上定义变量的一部分涉及决定如何测量它。许多变量可以通过多种方式测量。事实上,对于任何给定的变量,研究文献中可能有几十种常用的不同测量方法。每个变量的定义方式、提出的问题类型以及想法的概念化方式都会有所不同。研究人员有时倾向于将变量和度量写成好像它们是可以互换的。它们可能包括诸如“实验组的自我效能感更高”之类的陈述,而实际上它们的意思是在特定时刻的自我效能感的特定衡量标准对于实验组来说更高。正如我们在本章后面所提倡的那样,大多数研究人员都可以很好地为他们的变量选择现有的度量。
统计代写|SPSS代写代考|Random assignment
研究设计中的另一个关键术语是随机分配。在随机分配中,研究样本中的每个人都有相同的概率最终进入各个实验组。例如,在一组接受实验性治疗而另一组接受安慰剂治疗的设计中,每个参与者将有一个50/50最终进入实验组与对照组的机会。这是通过将参与者随机分配到组来实现的。在许多现代研究中,随机分配是由软件程序完成的,其中一些程序内置在在线调查平台中。随机分配也可以通过抽签或将参与者按报名参加研究的顺序分组来完成(例如,将偶数报名放在第 1 组,奇数在第 2 组)。
随机分配对于研究人员可以从一组给定的结果中得出的推理类型很重要。通过将参与者随机分组,理论上他们的背景特征和其他因素也被随机分组。因此,群体之间唯一的系统差异将是群体成员提供的待遇或条件。结果,推理可以更强。当组被随机分配时,我们会更有信心组之间的差异是由于组成员身份(或实验治疗),因为理论上组之间没有其他系统差异。当研究人员使用完整组(没有或不能随机分配的组)时,推论会有些弱。例如,如果我们比较学校的学业成绩一种使用计算机化数学教学的学校 B 与使用传统数学教学的学校 B,除了是否使用计算机化教学之外,两所学校之间可能还有许多其他差异。也许 A 学校也有更高的预算,或者有更多获得资源的学生,或者更有经验的老师。鉴于这些完整的小组,将差异归因于教学类型比将学生随机分配到教学类型更难。
但是,随机分配不足以建立因果关系(某个变量导致了结果)。因果关系需要强有力的证据。要支持因果主张,必须有: (1) 潜在因果变量为何会导致结果的理论依据;(2)因果变量必须在时间上先于结果(这通常意味着纵向设计);(3) 基于潜在因果变量的结果必须有可靠的变化;(4) 必须消除或控制所有其他潜在的因果变量 (Pedhazur, 1997)。随机分配有助于标准 4,但对于因果声明,还需要满足其他标准。
一个需要明确的区别,因为它可能会让一些学生感到困惑,那就是随机分配和随机抽样(本章前面描述的)是两个独立的过程,彼此不依赖。随机抽样意味着人口中的每个人都有平等的机会进入样本。随机分配意味着样本中的每个人都有平等的机会进入每个组。它们都涉及随机性,但针对过程的不同部分。
统计代写|SPSS代写代考|Experimental vs. correlational research
实验和相关(或观察)研究之间的主要区别是随机分配。实验研究涉及随机分配,而相关研究则不然。我们已经描述了实验研究在可以做出的各种推断方面的一些优势。那么,为什么研究人员要做相关工作呢?简单的答案是,研究人员可能感兴趣的许多变量不能或不应该随机分配。一些变量不应该在道德或法律上随机分配。如果研究人员已经知道或有强有力的证据相信某种治疗会伤害参与者,他们就不能将他们随机分配给该治疗。因此,如果研究人员想检查怀孕期间吸烟对婴儿大脑发育的影响,他们不能随机分配一些孕妇吸烟,因为它会造成已知的危害。相反,他们可能会在研究开始之前研究怀孕期间吸烟的女性的婴儿。其他变量根本无法随机分配。如果研究人员想研究科学、技术、工程和数学 (STEM) 学位获得的性别差异,研究人员不能随机分配参与者的性别身份。尽管性别认同可能是流动的,但研究人员无法操纵它们。因此,研究人员将根据现有的性别认同群体进行研究。这是唯一实用的方法。但不同性别身份的人也有一系列其他不同的经历。人们基于感知或自我认同的性别身份进行不同的社会化,他们从父母、同龄人和教育工作者那里收到不同类型的反馈,并且可能会受到不同类型的 STEM 相关经验。因此,很难将 STEM 学位获得的差异归因于性别,但研究人员可能会尝试了解导致性别差异发生的机制。
由于许多变量不能或不应该随机分配,教育和行为研究中的大部分工作都是相关的或观察的。因果推理仍然是可能的,尽管比实验方法更难。一些最重要和最有影响力的工作是相关的。我们的观点是,实验与相关研究不是一种等级制度——这两种方法都不是“更好”的,但它们提供了不同的优势和机会,并有不同的局限性。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。统计代写|python代写代考
随机过程代考
在概率论概念中,随机过程是随机变量的集合。 若一随机系统的样本点是随机函数,则称此函数为样本函数,这一随机系统全部样本函数的集合是一个随机过程。 实际应用中,样本函数的一般定义在时间域或者空间域。 随机过程的实例如股票和汇率的波动、语音信号、视频信号、体温的变化,随机运动如布朗运动、随机徘徊等等。
贝叶斯方法代考
贝叶斯统计概念及数据分析表示使用概率陈述回答有关未知参数的研究问题以及统计范式。后验分布包括关于参数的先验分布,和基于观测数据提供关于参数的信息似然模型。根据选择的先验分布和似然模型,后验分布可以解析或近似,例如,马尔科夫链蒙特卡罗 (MCMC) 方法之一。贝叶斯统计概念及数据分析使用后验分布来形成模型参数的各种摘要,包括点估计,如后验平均值、中位数、百分位数和称为可信区间的区间估计。此外,所有关于模型参数的统计检验都可以表示为基于估计后验分布的概率报表。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
statistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
机器学习代写
随着AI的大潮到来,Machine Learning逐渐成为一个新的学习热点。同时与传统CS相比,Machine Learning在其他领域也有着广泛的应用,因此这门学科成为不仅折磨CS专业同学的“小恶魔”,也是折磨生物、化学、统计等其他学科留学生的“大魔王”。学习Machine learning的一大绊脚石在于使用语言众多,跨学科范围广,所以学习起来尤其困难。但是不管你在学习Machine Learning时遇到任何难题,StudyGate专业导师团队都能为你轻松解决。
多元统计分析代考
基础数据: $N$ 个样本, $P$ 个变量数的单样本,组成的横列的数据表
变量定性: 分类和顺序;变量定量:数值
数学公式的角度分为: 因变量与自变量
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。