如果你也在 怎样代写机器学习machine learning这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
机器学习(ML)是人工智能(AI)的一种类型,它允许软件应用程序在预测结果时变得更加准确,而无需明确编程。机器学习算法使用历史数据作为输入来预测新的输出值。
statistics-lab™ 为您的留学生涯保驾护航 在代写机器学习machine learning方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写机器学习machine learning代写方面经验极为丰富,各种代写机器学习machine learning相关的作业也就用不着说。
我们提供的机器学习machine learning及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
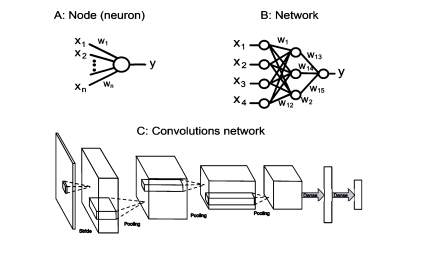
cs代写|机器学习代写machine learning代考|Recent advances
Many advances have been made in recent years based on machine learning, in particular with deep learning methods for image processing, natural language processing, and more general data analytics. Many companies are now enthusiastic about data analytics, using data in a wider sense to gain insights into customer profiles or other data mining tasks. Machine learning is an important part of a data analytics engine. Data analytics often require additional care such as data security to ensure privacy, the ability to acquire and maintain large data collections, and also to make results available in a form useful for humans. We will not delve into many of these aspects but concentrate instead on the data modeling aspects.
One of the most visible impacts of deep learning has been made in computer vision through convolutional neural networks. The basic applications in this area are mostly based on recognition networks and methods for semantic segmentation. However, such methods have now also advanced object localization, object tracking, and scene understanding, to name but a few. Some examples from my own projects are shown in Fig. 1.7. The left-hand image shows semantic segmentation to identify and localize crop and weed for a robotic farming application. The right-hand image shows an application of fish tracking for aquaculture applications.Another area that has seen a huge improvement is the area of natural language processing (NLP). It has long been an important tasks to build programs that understand natural languages for applications such as translation, sentiment analysis, or to enable
some form of formal analysis of technical reports. Various methods for sequence modeling have contributed greatly to this area, in particular recurrent neural networks, discussed later in this book.
A developing area in machine learning are generative models. Generative models are models that can make examples of instances of a class. For example, a generative models can learn about cars from examples and then generate images of new cars by itself. Such networks could then be used in some creative way. Examples of systems that can learn generative models are variational autoencoders (VAEs) and generative adversarial networks (GANs). These methods demonstrate an important advance: the ability to capture the probabilistic structure of objects which in turn can be exploited in various ways.
Machine learning methods have shown that it can produce solutions to problems that have previously been intractable. For example, computer programs to play the Chinese board game “Go” have been mostly available only at an advance novice level until a few years ago. However, in 2016 , a machine learning program called “Alpha-Go” that combined cleverly supervised and reinforcement learning was able to beat a player, Mr. Lee Sedol, who is considered one of the best players of the last decade and had previously won sixteen world titles. Go was considered to be a real challenge for AI systems as it was considered to rely a lot on “gut feelings” rather than quantifiable strategies. It was therefore a huge success when computers, which had only reached levels of an advanced beginner a few years prior, could win against such an accomplished player.
cs代写|机器学习代写machine learning代考|No free lunch, but worth the bite
Neural networks and other models, such as support vector machines and decision trees, are fairly general models in contrast to Bayesian models that are usually much better at specifying a causal structure of interpretable entities. More specific models should outperform more general model as long as they faithfully represent the underlying structure of the world model. This fact is captured by David Wolpert’s “No free lunch” theorem, which states that there is not a single algorithms that covers all applications better than some other algorithms. The best model is, of course, the real world model, as discussed earlier, which we generally do not know. Applying machine learning algorithms is therefore somewhat of an art and requires experience and knowledge of the constraints of the algorithms. Discussions of what is an appropriate model are
sometimes cumbersome and can distract us from making good use of them. We take a more practical approach, letting a user define what an appropriate contribution is for a machine learning model. For example, the best accuracy of a prediction might not always be the goal, and other considerations such as the speed of processing, the number of required training data, or the ability to interpret data can be important factors. We will therefore include brief discussions of some classic machine learning algorithms even if they do not represent the latest research in this area.
An interesting remark that often cops up in discussions of some machine learning algorithms and, in particular, neural networks is that these methods are commonly described, and somewhat criticized, as being black box methods. By “back box” we usually mean that the internal structure is not known. However, the machine learning models usually live in a computer where we can inspect all the components; these methods are hence known as white box methods. A better way to describe the difficulties with the ability human have in interpreting machine learning models is due to the fact that trained deep learning models are commonly complex models that implement complex decision rules. While some application might have as a goal the learning of human interpretable decision rules, other might rather be interested in achieving better prediction performance, which often requires more fine-grained rules.
We will see in Chapter 3 that writing a program to apply machine learning algorithms to data is often not very difficult. New algorithms will often find their way to graphical data mining tools, which makes them available to an even larger application community. However, applying such algorithms correctly in different application domains can be challenging and it is well known that some experience is required. We therefore concentrate in the following on explaining what is behind these algorithms and how different theoretical concepts are explored by them. Some understanding of the algorithms is absolutely necessary to avoid pitfalls in their application.
The basic first step for the application of ML methods is how to represent the data. We mentioned already some different data structures of inputs such as vectors or tensors. However, there are usually many different possible ways to represent a problem numerically. In the past it has been crucial to work out an appropriate highlevel data representation such as summary statistics to keep the dimensionality of the model low. However, the recent progress in deep learning made it possible to treat this representation itself as part of the learning problem. Representational learning has thus become an important part of machine learning.
cs代写|机器学习代写machine learning代考|Programming environment
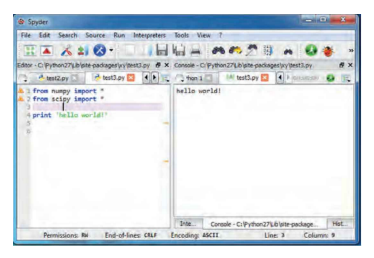
We will be using a programming environment called Jupyter. Specifically, we will be using the Jupyter notebook that allows us to write code with a simple editor and display comments and outputs in the same file. Jupyter is accessed through the browser and contains form fields in which code and comments can be added. These fields can then be executed and the feedback from print commands or figure plots are displayed after each block within the same document. This makes it very useful in documenting brief code and small exercises. An example program is shown in Fig. 2.1. All example programs in this book are available as Jupyter files on the web.
The Jupyter notebook has an interface to launch the Python interpreter and to run individual sections or all the code. The header with comments is produced by executing a text cell. This is useful to produce some documentations. Also, the notebook can be distributed with the output that can facilitate communications about code. The numbers on the left shows a consecutive number of calls to the interpreter. In the shown example, the first program cell was run first to load the libraries, and then the second cell was run twice; this is why a [3] is displayed in front of this cell. When the program is running, an $[*]$ is displayed. The second cell produces the output 4 , which is displayed after the cell.
A more advanced environment for bigger programs with more traditional programming support is Spyder. This tool includes an editor, a command window, and further programming support such as displays of variables and debugging support. This pro-gram mimics more traditional programming environment such as the ones found in Matlab and R. An example view of Spyder is shown in Fig. 2.2. On the left is the editor window that contains a syntax-sensitive display to write the programs, and on the right is the console to launch line commands such as executing and interpreting the code. As Python is an interpreted language, it is possible to work with the programs in an interactive way, such as running a simulation and than plotting results in various ways. The Spyder development environment is recommended for bigger projects.
机器学习代写
cs代写|机器学习代写machine learning代考|Recent advances
近年来,基于机器学习取得了许多进展,特别是在图像处理、自然语言处理和更一般的数据分析方面的深度学习方法。许多公司现在热衷于数据分析,使用更广泛意义上的数据来深入了解客户档案或其他数据挖掘任务。机器学习是数据分析引擎的重要组成部分。数据分析通常需要额外的关注,例如数据安全,以确保隐私、获取和维护大型数据集合的能力,以及以对人类有用的形式提供结果。我们不会深入研究这些方面,而是专注于数据建模方面。
深度学习最明显的影响之一是通过卷积神经网络在计算机视觉中产生的。该领域的基础应用大多基于识别网络和语义分割方法。然而,这些方法现在还具有先进的对象定位、对象跟踪和场景理解,仅举几例。图 1.7 显示了我自己项目中的一些示例。左图显示了语义分割,用于识别和定位农作物和杂草,用于机器人农业应用。右图显示了鱼类追踪在水产养殖中的应用。另一个取得巨大进步的领域是自然语言处理 (NLP) 领域。长期以来,为翻译等应用程序构建理解自然语言的程序一直是一项重要任务,
某种形式的技术报告的正式分析。序列建模的各种方法对这一领域做出了巨大贡献,尤其是递归神经网络,本书后面将对此进行讨论。
机器学习的一个发展领域是生成模型。生成模型是可以制作类实例示例的模型。例如,生成模型可以从示例中学习汽车,然后自行生成新车的图像。然后可以以某种创造性的方式使用这些网络。可以学习生成模型的系统示例是变分自动编码器 (VAE) 和生成对抗网络 (GAN)。这些方法展示了一个重要的进步:捕捉对象的概率结构的能力,而这些概率结构又可以以各种方式加以利用。
机器学习方法表明,它可以为以前难以解决的问题提供解决方案。例如,直到几年前,玩中国棋盘游戏“围棋”的计算机程序大多只在高级新手级别上可用。然而,在 2016 年,一个名为“Alpha-Go”的机器学习程序将巧妙地监督和强化学习相结合,击败了被认为是过去十年中最好的棋手之一的李世石先生,此前他曾赢过十六个世界冠军。围棋被认为是对人工智能系统的真正挑战,因为它被认为很大程度上依赖于“直觉”而不是可量化的策略。因此,当计算机在几年前才达到高级初学者的水平时,能够战胜这样一个有成就的玩家,这是一个巨大的成功。
cs代写|机器学习代写machine learning代考|No free lunch, but worth the bite
神经网络和其他模型,例如支持向量机和决策树,是相当通用的模型,而贝叶斯模型通常更擅长指定可解释实体的因果结构。更具体的模型应该优于更一般的模型,只要它们忠实地代表世界模型的底层结构。David Wolpert 的“没有免费的午餐”定理捕捉到了这一事实,该定理指出没有一种算法能比其他一些算法更好地涵盖所有应用程序。最好的模型当然是我们通常不知道的真实世界模型,如前所述。因此,应用机器学习算法在某种程度上是一门艺术,并且需要有关算法约束的经验和知识。关于什么是合适的模型的讨论是
有时很麻烦,会分散我们充分利用它们的注意力。我们采用更实用的方法,让用户定义对机器学习模型的适当贡献。例如,预测的最佳准确性可能并不总是目标,处理速度、所需训练数据的数量或解释数据的能力等其他考虑因素可能是重要因素。因此,我们将简要讨论一些经典的机器学习算法,即使它们并不代表该领域的最新研究。
在讨论某些机器学习算法,特别是神经网络时,经常会出现一个有趣的评论,即这些方法通常被描述为黑盒方法,并且受到了一些批评。“后箱”通常是指内部结构未知。但是,机器学习模型通常存在于我们可以检查所有组件的计算机中。这些方法因此被称为白盒方法。描述人类在解释机器学习模型的能力方面遇到的困难的更好方法是,经过训练的深度学习模型通常是实现复杂决策规则的复杂模型。虽然某些应用程序的目标可能是学习人类可解释的决策规则,但其他应用程序可能更感兴趣的是实现更好的预测性能,
我们将在第 3 章中看到,编写将机器学习算法应用于数据的程序通常不是很困难。新算法通常会找到用于图形数据挖掘工具的方式,这使得它们可用于更大的应用程序社区。然而,在不同的应用领域中正确应用这些算法可能具有挑战性,众所周知,需要一些经验。因此,我们将在下文集中解释这些算法背后的原因以及它们如何探索不同的理论概念。对算法的一些了解是绝对必要的,以避免在其应用中出现陷阱。
应用 ML 方法的基本第一步是如何表示数据。我们已经提到了一些不同的输入数据结构,例如向量或张量。然而,通常有许多不同的可能方式来用数字表示一个问题。在过去,制定适当的高级数据表示(例如汇总统计)以保持模型的低维是至关重要的。然而,深度学习的最新进展使得将这种表示本身视为学习问题的一部分成为可能。表征学习因此成为机器学习的重要组成部分。
cs代写|机器学习代写machine learning代考|Programming environment
我们将使用一个名为 Jupyter 的编程环境。具体来说,我们将使用 Jupyter notebook,它允许我们使用简单的编辑器编写代码,并在同一个文件中显示注释和输出。Jupyter 可通过浏览器访问,并包含可以添加代码和注释的表单字段。然后可以执行这些字段,并在同一文档中的每个块之后显示来自打印命令或图形图的反馈。这使得它在记录简短代码和小练习时非常有用。示例程序如图 2.1 所示。本书中的所有示例程序都以 Jupyter 文件的形式在 Web 上提供。
Jupyter notebook 有一个接口来启动 Python 解释器并运行各个部分或所有代码。带有注释的标题是通过执行文本单元格生成的。这对于生成一些文档很有用。此外,notebook 可以与可以促进代码交流的输出一起分发。左侧的数字显示了对口译员的连续呼叫次数。在所示示例中,第一个程序单元首先运行以加载库,然后第二个单元运行两次;这就是为什么在此单元格前面显示 [3] 的原因。当程序运行时,一个[∗]被展示。第二个单元格产生输出 4,显示在单元格之后。
Spyder 是为具有更传统编程支持的大型程序提供的更高级环境。该工具包括一个编辑器、一个命令窗口和进一步的编程支持,例如变量显示和调试支持。该程序模仿了更传统的编程环境,例如 Matlab 和 R 中的编程环境。Spyder 的示例视图如图 2.2 所示。左侧是编辑器窗口,其中包含用于编写程序的语法敏感显示,右侧是控制台,用于启动行命令,例如执行和解释代码。由于 Python 是一种解释型语言,因此可以以交互方式处理程序,例如运行模拟并以各种方式绘制结果。大型项目推荐使用 Spyder 开发环境。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。