如果你也在 怎样代写离散数学discrete mathematics这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
离散数学是研究可以被认为是 “离散”(类似于离散变量,与自然数集有偏射)而不是 “连续”(类似于连续函数)的数学结构。离散数学研究的对象包括整数、图形和逻辑中的语句。相比之下,离散数学不包括 “连续数学 “中的课题,如实数、微积分或欧几里得几何。离散对象通常可以用整数来列举;更正式地说,离散数学被定性为处理可数集的数学分支(有限集或与自然数具有相同心数的集)。然而,”离散数学 “这一术语并没有确切的定义。
statistics-lab™ 为您的留学生涯保驾护航 在代写离散数学discrete mathematics方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写离散数学discrete mathematics代写方面经验极为丰富,各种代写离散数学discrete mathematics相关的作业也就用不着说。
我们提供的离散数学discrete mathematics及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
数学代写|离散数学作业代写discrete mathematics代考|Applications of Trees
Applications of trees are numerous. Here we just introduce three diverse problems that can be studied and solved using trees, namely the magic square of order 3 , a best-of-seven game series, and the Huffman coding.
A magic square is an $n \times n$ array of distinct positive integers so that the sum of the numbers is the same in each row, column, and main diagonal. Note that if the array includes just the positive integers $1,2,3, \ldots, n^2$, the magic square is said to be normal. The integer $n$ (where $n$ is the number of integers along one side) is the order of the normal magic square and the constant sum, called the magic sum, is as follows:
$$
S=\frac{n\left(n^2+1\right)}{2}
$$
Any magic square can be rotated and reflected to produce eight different squares. In magic square theory, all of these are generally deemed equivalent, and the eight such squares are said to make up a single equivalent class. Equivalent squares are not considered as distinct. Note that the number of distinct magic squares (excluding those obtained by rotation and reflection) of order $n=1,2,3,4$, and 5 are 1, 0,1, 880, and $275,305,224$, respectively, while noting that the number of magic squares of order $n \geq 6$ is not exactly known, though it can be approximated.
In order to reduce the storage requirements in digital systems as well as the transmission time requirements in digital networks, data must be encoded so fewer bits are used to represent a data symbol. For efficient coding (i.e., effective data compression), data symbols that occur more frequently should be encoded using shorter bit sequences, and longer bit sequences should be used to encode rarely occurring data symbols. Therefore data symbols are encoded using varying numbers of bits. When the statistics regarding data symbols are available, the Huffman code is the optimum algorithm. The Huffman code is a prefix-free (instantaneous) code, where no codeword is a prefix of another codeword, as such a Huffman code can be represented using a rooted binary tree. It is important to note that the Huffman code is widely used in compression of image files.
The Huffman coding algorithm begins with a forest of trees, each consisting of a single vertex, where each vertex shows a data symbol and its probability of occurrence. It is essential to put the vertices in the order of increasing probabilities, that is, the first vertex indicates the least likely symbol, and the last vertex reflects the most likely symbol. At each step, we combine two trees with the least total probability into a single tree by introducing a new root and placing the tree with larger weight as one of its subtrees and the tree with smaller weight as the other subtree. Moreover, the sum of the two probabilities associated with the two subtrees is assigned as the total probability of the tree. If necessary, reorder the probabilities of trees, including the newly formed one, so they are still in increasing order. There are many ways to come up with a Huffman code for a given set of data symbols and their probabilities of occurrences. However, they will all have the same average number of bits per symbol for a given set of data symbols.
数学代写|离散数学作业代写discrete mathematics代考|Types of Finite-State Machines
A finite-state machine is a mathematical model of computation based on a hypothetical machine made of different states that can be used to simulate sequential logic in order to represent and control execution flow. Only one single state of a finite-state machine can be active at a given time. Finite-state machines accomplishing specific tasks are in essence computer programming, and there is no specific method for carrying them out, as there are many machines that can accomplish the same task.
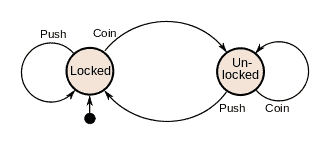
In the context of finite-state machines, a string is a finite sequence of elements; an alphabet is a finite, nonempty set that contains elements used to form strings; the length of a string is the number of elements that make up the string; and a language is a subset of the set of all strings over an alphabet. As a simple example to illustrate some basic terms, Fig. 20.1 shows a finite-state machine with two final states, namely, “error” and “correct.” This machine can parse the string “yes,” whose length is 3 while noting that the alphabet consists of 26 letters in the English language.
A finite-state machine has a set of finite states, including a starting state, an input alphabet, and a transition function by which a next state is assigned to every pair of a state and an input. Due to its finite states, a finite-state machine has a limited memory. A finite-state machine is an abstract machine that can be in exactly one of a finite number of states at any given time, where a state changes to another in response to some input. Fig. 20.2 shows the finite-state machines discussed in this chapter.
A finite-state machine with no output, also known as a finite-state automaton (FSA), models the changes of states within a system until it achieves one of a collection of desired states. The finite-state automata (the plural of automaton) do not produce output, but they have a set of final states. They recognize input strings that take the starting state to a final state. These machines can be used, for instance, to model ATMs, traffic lights, parity check bits, subway turnstiles, and DVD players. They are also known as language recognizers and thus play a central role in the design and construction of compilers for programming languages. Finite-state automata are categorized into deterministic FSA and nondeterministic FSA.
In a finite-state machine with output, also referred to as a finite-state transducer (FST), each transition has an associated output that either provides some information about the state of the machine or outputs a stream of information as the machine is intended to produce. In a finite-state machine, there are therefore no final states. These machines can be used, for instance, to model vending machines, delay devices, binary adders, pattern finders, network protocols, language and speech recognizers, and spelling and grammar checking. FSTs are categorized into Moore machines and Mealy machines.
Finite-state machines are represented using either state tables, which are easier to present, or state diagrams (directed graphs with labeled edges), which are easier to understand. In a state diagram for a finite-state machine, the initial state is indicated by means of an arrow that terminates at the initial state but has no initial vertex. Note that every state has a transition for every input. A transition may result in a loop back to the same state. If from some state an input is impossible, then no transition corresponding to that input should be added to the state diagram. A state diagram contains transitions for all possible inputs at each state.
离散数学代写
数学代写|离散数学作业代写discrete mathematics代考|Applications of Trees
树木的应用很多。这里我们只介绍三种可以用树研究和解决的不同问题,即三阶幻方、七局三胜制和霍夫 魯编码。
魔方是一个 $n \times n$ 不同的正整数数组,使得每行、每列和主对角线的数字之和相同。请注意,如果数组仅 包含正整数 $1,2,3, \ldots, n^2$ ,幻方被认为是正常的。整数 $n$ (在哪里 $n$ 是沿一侧的整数个数) 是正常幻方 的阶数,常量和称为幻和,如下所示:
$$
S=\frac{n\left(n^2+1\right)}{2}
$$
任何魔方都可以旋转和反射以产生八个不同的方块。在魔方理论中,所有这些通常被认为是等价的,据说 八个这样的方块组成了一个等价类。等效正方形不被视为不同。注意阶数不同的幻方数 (不包括通过旋转 和反射得到的) $n=1,2,3,4$, 和 5 是 $1,0,1,880$ ,和 $275,305,224$ ,同时注意到阶数的幻方数 $n \geq 6$ 不 完全已知,但可以近似计算。
为了降低数字系统中的存储要求以及数字网络中的传输时间要求,必须对数据进行编码,以便使用更少的 位来表示数据符号。为了有效编码 (即,有效数据压缩),更频贁出现的数据符号应该使用较短的比特序 列编码,而较长的比特序列应该用于编码很少出现的数据符号。因此,数据符号使用不同数量的比特进行 编码。当数据符号的统计数据可用时,霍夫曼码是最佳算法。霍夫曼代码是无前缀 (瞬时) 代码,其中没 有代码字是另一个代码字的前缀,因此霍夫曼代码可以使用有根二叉树来表示。
霍夫曼编码算法从一片树开始,每棵树都由一个顶点组成,其中每个顶点显示一个数据符号及其出现概 率。必须将顶点按概率递增的顺序排列,即第一个顶点表示可能性最小的符号,最后一个顶点表示可能性 最大的符号。在每一步中,我们通过引入一个新根并将权重较大的树作为其子树之一,将权重较小的树作 为另一棵子树,将总概率最小的两棵树组合成一棵树。此外,与两个子树相关联的两个概率之和被指定为 树的总概率。如有必要,重新排序树的概率,包括新形成的树,使它们仍处于递增顺序。有许多方法可以 为一组给定的数据符号及其出现概率提出霍夫睘代码。但是,对于给定的数据符号集,它们每个符号的平 均位数都相同。
数学代写|离散数学作业代写discrete mathematics代考|Types of Finite-State Machines
有限状态机是基于由不同状态组成的假设机器的计算数学模型,可用于模拟时序逻辑以表示和控制执行流程。在给定时间只能激活有限状态机的一个状态。完成特定任务的有限状态机本质上是计算机编程,没有具体的执行方法,因为有很多机器可以完成同样的任务。
在有限状态机的上下文中,字符串是元素的有限序列;字母表是一个有限的非空集合,其中包含用于形成字符串的元素;字符串的长度是组成字符串的元素的数量;语言是字母表中所有字符串集合的子集。作为说明一些基本术语的简单示例,图 20.1 显示了具有两个最终状态的有限状态机,即“错误”和“正确”。该机器可以解析长度为 3 的字符串“yes”,同时注意到该字母表由 26 个英文字母组成。
有限状态机具有一组有限状态,包括起始状态、输入字母表和转换函数,通过该转换函数将下一个状态分配给每对状态和输入。由于其有限状态,有限状态机的内存有限。有限状态机是一种抽象机,它可以在任何给定时间恰好处于有限数量的状态中的一个,其中一个状态更改为另一个状态以响应某些输入。图 20.2 显示了本章讨论的有限状态机。
没有输出的有限状态机,也称为有限状态自动机 (FSA),对系统内的状态变化进行建模,直到它达到所需状态集合中的一个。有限状态自动机(自动机的复数形式)不产生输出,但它们有一组最终状态。它们识别将起始状态变为最终状态的输入字符串。例如,这些机器可用于模拟 ATM、交通信号灯、奇偶校验位、地铁十字转门和 DVD 播放器。它们也被称为语言识别器,因此在编程语言编译器的设计和构建中起着核心作用。有限状态自动机分为确定性 FSA 和非确定性 FSA。
在具有输出的有限状态机(也称为有限状态转换器 (FST))中,每个转换都有一个关联的输出,该输出要么提供有关机器状态的一些信息,要么输出机器预期的信息流生产。因此,在有限状态机中,没有最终状态。例如,这些机器可用于为自动售货机、延迟设备、二进制加法器、模式查找器、网络协议、语言和语音识别器以及拼写和语法检查建模。FST 分为 Moore 机和 Mealy 机。
有限状态机使用更易于呈现的状态表或更易于理解的状态图(带有标记边的有向图)来表示。在有限状态机的状态图中,初始状态由终止于初始状态但没有初始顶点的箭头表示。请注意,每个状态对每个输入都有一个转换。转换可能会导致返回相同状态的循环。如果从某个状态输入是不可能的,则不应将对应于该输入的转换添加到状态图中。状态图包含每个状态下所有可能输入的转换。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。