如果你也在 怎样代写广义线性模型generalized linear model这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
广义线性模型(GLiM,或GLM)是John Nelder和Robert Wedderburn在1972年制定的一种高级统计建模技术。它是一个包含许多其他模型的总称,它允许响应变量y具有除正态分布以外的误差分布。
statistics-lab™ 为您的留学生涯保驾护航 在代写广义线性模型generalized linear model方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写广义线性模型generalized linear model代写方面经验极为丰富,各种代写广义线性模型generalized linear model相关的作业也就用不着说。
我们提供的广义线性模型generalized linear model及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|广义线性模型代写generalized linear model代考|Heart Disease Example
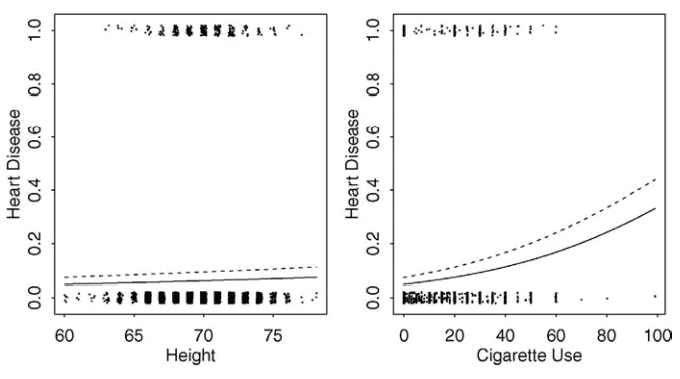
What might affect the chance of getting heart disease? One of the earliest studies addressing this issue started in 1960 and used 3154 healthy men, aged from 39 to 59 , from the San Francisco area. At the start of the study, all were free of heart disease. Eight and a half years later, the study recorded whether these men now suffered from heart disease along with many other variables that might be related to the chance of developing this disease. We load a subset of this data from the Western Collaborative Group Study described in Rosenman et al. (1975): We see that only 257 men developed heart disease as given by the factor variable chd. The men vary in height (in inches) and the number of cigarettes (cigs) smoked per day. We can plot these data using R base graphics:
The first panel in Figure $2.1$ shows a boxplot. This shows the similarity in the distribution of heights of the two groups of men with and without heart disease. But the heart disease is the response variable so we might prefer a plot which treats it as such. We convert the absence/presence of disease into a numerical $0 / 1$ variable and plot this in the second panel of Figure 2.1. Because heights are reported as round numbers of inches and the response can only take two values, it is sensible to add a small amount of noise to each point, called jittering, so that we can distinguish them. Again we can see the similarity in the distributions. We might think about fitting a line to this plot.
More informative plots may be obtained using the ggplot2 package of Wickham (2009). In the first panel of Figure 2.2, we see two histograms showing the distribution of heights for both those with and without heart disease. The dodge option ensures that the two histograms are interleaved. We see that the two similar. We also had to set the bin width of the histogram. It was natural to use one inch as all the height measurements are rounded to the nearest inch. In the second panel of Figure 2.2, we see the corresponding histograms for smoking. In this case, we have shown the frequency rather than the count version of the histogram. We see that smokers are more likely to get heart disease.distributions are
统计代写|广义线性模型代写generalized linear model代考|Logistic Regression
Suppose we have a response variable $Y_i$ for $i=1, \ldots, n$ which takes the values zero or one with $P\left(Y_i=1\right)=p_i$. This response may be related to a set of $q$ predictors $\left(x_{i 1}, \ldots, x_{i q}\right)$. We need a model that describes the relationship of $x_1, \ldots, x_q$ to the probability $p$. Following the linear model approach, we construct a linear predictor:
$$
\eta_i=\beta_0+\beta_1 x_{i 1}+\cdots+\beta_q x_{i q}
$$
Since the linear predictor can accommodate quantitative and qualitative predictors with the use of dummy variables and also allows for transformations and combinations of the original predictors, it is very flexible and yet retains interpretability. The idea that we can express the effect of the predictors on the response solely through the linear predictor is important. The idea can be extended to models for other types of response and is one of the defining features of the wider class of generalized linear models (GLMs) discussed later in Chapter 8.
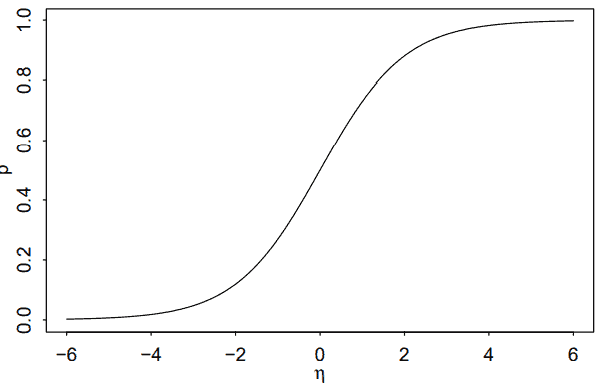
We have seen previously that the linear relation $\eta_i=p_i$ is not workable because we require $0 \leq p_i \leq 1$. Instead we shall use a link function $g$ such that $\eta_i=g\left(p_i\right)$. We need $g$ to be monotone and be such that $0 \leq g^{-1}(\eta) \leq 1$ for any $\eta$. The most popular choice of link function in this situation is the logit. It is defined so that:
$$
\eta=\log (p /(1-p))
$$
or equivalently:
$$
p=\frac{e^\eta}{1+e^\eta}
$$
Combining the use of the logit link with a linear predictor gives us the term logistic regression. Other choices of link function are possible but we will defer discussion of these until later. The logit and its inverse are defined as logit and ilogit in the faraway package. The relationship between $p$ and the linear predictor $\eta$ is shown in Figure 2.4.
广义线性模型代考
统计代写|广义线性模型代写generalized linear model代考|Heart Disease Example
哪些因素会影响患心脏病的几率?解决这个问题的最早研究之一始于 1960 年,使用了来自旧金山地区的 3154 名年龄在 39 至 59 岁之间的健康男性。在研究开始时,所有人都没有心脏病。八年半后,该研究记录了这些人现在是否患有心脏病以及许多其他可能与患这种疾病的机会有关的变量。我们从 Rosenman 等人描述的西方协作组研究中加载该数据的一个子集。(1975):我们看到只有 257 名男性患上了由因子变量 chd 给出的心脏病。这些人的身高(以英寸为单位)和每天吸的香烟数量各不相同。我们可以使用 R 基础图形绘制这些数据:
第一个面板如图2.1显示箱线图。这表明患有和未患有心脏病的两组男性的身高分布相似。但是心脏病是响应变量,所以我们可能更喜欢这样对待它的情节。我们将疾病的不存在/存在转换为数字0/1变量并将其绘制在图 2.1 的第二个面板中。因为高度以英寸的整数形式报告并且响应只能取两个值,所以向每个点添加少量噪声(称为抖动)是明智的,这样我们就可以区分它们。我们再次可以看到分布的相似性。我们可能会考虑为该图拟合一条线。
使用 Wickham (2009) 的 ggplot2 包可以获得更多信息图。在图 2.2 的第一幅图中,我们看到两个直方图显示了患有和未患有心脏病的人的身高分布。闪避选项确保两个直方图交错。我们看到两者相似。我们还必须设置直方图的 bin 宽度。使用一英寸是很自然的,因为所有的身高测量值都四舍五入到最接近的英寸。在图 2.2 的第二个面板中,我们看到了吸烟的相应直方图。在这种情况下,我们显示的是频率而不是直方图的计数版本。我们看到吸烟者更容易患心脏病。分布是
统计代写|广义线性模型代写generalized linear model代考|Logistic Regression
假设我们有一个响应变量 $Y_i$ 为了 $i=1, \ldots, n$ 它取值零或 $-P\left(Y_i=1\right)=p_i$. 此响应可能与一组 $q$ 预测器 $\left(x_{i 1}, \ldots, x_{i q}\right)$. 我们需要一个描述关系的模型 $x_1, \ldots, x_q$ 概率 $p$. 按照线性模型方法,我们构建了一个线性预测 器:
$$
\eta_i=\beta_0+\beta_1 x_{i 1}+\cdots+\beta_q x_{i q}
$$
由于线性预测器可以通过使用虚拟变量来容纳定量和定性预测器,并且还允许原始预测器的转换和组合,因此它 非常灵活并保留了可解释性。我们可以仅通过线性预测变量来表达预测变量对响应的影响这一想法很重要。这个 想法可以扩展到其他类型响应的模型,并且是第 8 章稍后讨论的更广泛类别的广义线性模型 (GLM) 的定义特征 之一。
我们之前已经看到线性关系 $\eta_i=p_i$ 不可行,因为我们需要 $0 \leq p_i \leq 1$. 相反,我们将使用链接功能 $g$ 这样 $\eta_i=g\left(p_i\right)$. 我们需要 $g$ 是单调的,并且是这样的 $0 \leq g^{-1}(\eta) \leq 1$ 对于任何 $\eta$. 在这种情况下最流行的链接函数 选择是 logit。它被定义为:
$$
\eta=\log (p /(1-p))
$$
或等效地:
$$
p=\frac{e^\eta}{1+e^\eta}
$$
将 logit 链接的使用与线性预测变量相结合,我们就得到了术语逻辑回归。链接功能的其他选择是可能的,但我 们将推迟到以后再讨论这些。logit 及其反函数在 faraway 包中定义为 logit 和 ilogit。之间的关系 $p$ 和线性预测 器 $n$ 如图 $2.4$ 所示。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。