如果你也在 怎样代写机器学习Machine Learning 这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。机器学习Machine Learning是一个致力于理解和建立 “学习 “方法的研究领域,也就是说,利用数据来提高某些任务的性能的方法。机器学习算法基于样本数据(称为训练数据)建立模型,以便在没有明确编程的情况下做出预测或决定。机器学习算法被广泛用于各种应用,如医学、电子邮件过滤、语音识别和计算机视觉,在这些应用中,开发传统算法来执行所需任务是困难的或不可行的。
机器学习Machine Learning程序可以在没有明确编程的情况下执行任务。它涉及到计算机从提供的数据中学习,从而执行某些任务。对于分配给计算机的简单任务,有可能通过编程算法告诉机器如何执行解决手头问题所需的所有步骤;就计算机而言,不需要学习。对于更高级的任务,由人类手动创建所需的算法可能是一个挑战。在实践中,帮助机器开发自己的算法,而不是让人类程序员指定每一个需要的步骤,可能会变得更加有效 。
statistics-lab™ 为您的留学生涯保驾护航 在代写机器学习 machine learning方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写机器学习 machine learning代写方面经验极为丰富,各种代写机器学习 machine learning相关的作业也就用不着说。
计算机代写|机器学习代写machine learning代考|Basic planning for a project
The planning of any ML project typically starts at a high level. A business unit, executive, or even a member of the DS team comes up with an idea of using the DS team’s expertise to solve a challenging problem. While typically little more than a concept at this early stage, this is a critical juncture in a project’s life cycle.
In the scenario we’ve been discussing, the high-level idea is personalization. To an experienced DS, this could mean any number of things. To an SME of the business unit, it could mean many of the same concepts that the DS team could think of, but it may not. From this early point of an idea to before even basic research begins, the first thing everyone involved in this project should be doing is having a meeting. The subject of this meeting should focus on one fundamental element: Why are we building this?
It may sound like a hostile or confrontational question to ask. It may take some people aback when hearing it. However, it’s one of the most effective and important questions, as it opens a discussion into the true motivations for why people want the project to be built. Is it to increase sales? Is it to make our external customers happier? Or is it to keep people browsing on the site for longer durations?
Each of these nuanced answers can help inform the goal of this meeting: defining the expectations of the output of any ML work. The answer also satisfies the measurement metric criteria for the model’s performance, as well as attribution scoring of the performance in production (the very score that will be used to measure $\mathrm{A} / \mathrm{B}$ testing much later).
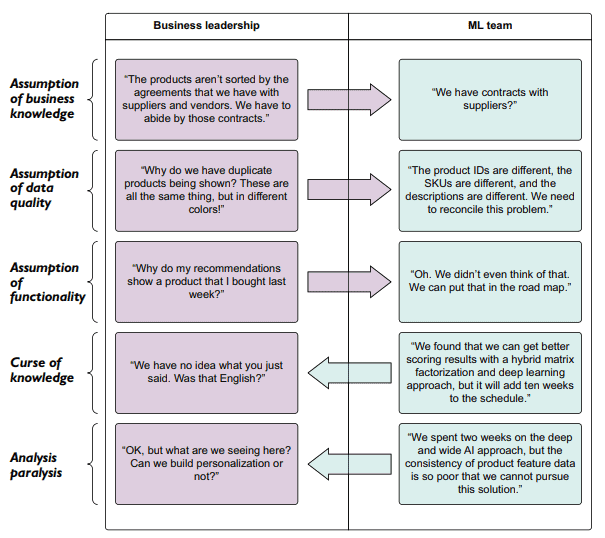
In our example scenario, the team fails to ask this important why question. Figure 3.6 shows the divergence in expectations from the business side and the ML side because neither group is speaking about the essential aspect of the project and is instead occupied in mental silos of their own creating. The ML team is focusing entirely on how to solve the problem, while the business team has expectations of what would be delivered, wrongfully assuming that the ML team will “just understand it.”
计算机代写|机器学习代写machine learning代考|ASSUMPTION OF BUSINESS KNOWLEDGE
Assumption of business knowledge is a challenging issue, particularly for a company that’s new to utilizing ML, or for a business unit at a company that has never worked with its ML team before. In our example, the business leadership’s assumption was that the ML team knew aspects of the business that the leadership considered widely held knowledge. Because no clear and direct set of requirements was set out, this assumption wasn’t identified as a clear requirement. With no SME from the business unit involved in guiding the ML team during data exploration, there simply was no way for them to know this information during the process of building the MVP either.
An assumption of business knowledge is often a dangerous path to tread for most companies. At many companies, the ML practitioners are insulated from the inner workings of a business. With their focus mostly in the realm of providing advanced analytics, predictive modeling, and automation tooling, scant time can be devoted to understanding the nuances of how and why a business is run. While some obvious aspects of the business are known by all (for example, “we sell product $x$ on our website”), it is not reasonable to expect that the modelers should know that a business process exists in which some suppliers of goods would be promoted on the site over others.
A good solution for arriving at these nuanced details is to have an SME from the group that is requesting a solution be built for them (in this case, the product marketing group) explain how they decide the ordering of products on each page of the website and app. Going through this exercise would allow for everyone in the room to understand the specific rules that may be applied to govern the output of a model.
ASSUMPTION OF DATA QUALITY
The onus of duplicate product listings in the demo output is not entirely on either team. While the ML team members certainly could have planned for this to be an issue, they weren’t aware of it precisely in the scope of its impact. Even had they known, they likely would have wisely mentioned that correcting for this issue would not be a part of the demo phase (because of the volume of work required and the request that the prototype not be delayed for too long).
The principal issue here is in not planning for it. By not discussing the expectations, the business leaders’ confidence in the capabilities of the ML team erodes. The objective measure of the prototype’s success will largely be ignored as the business members focus solely on the fact that for a few users’ sample data, the first 300 recommendations show nothing but 4 products in 80 available shades and patterns.
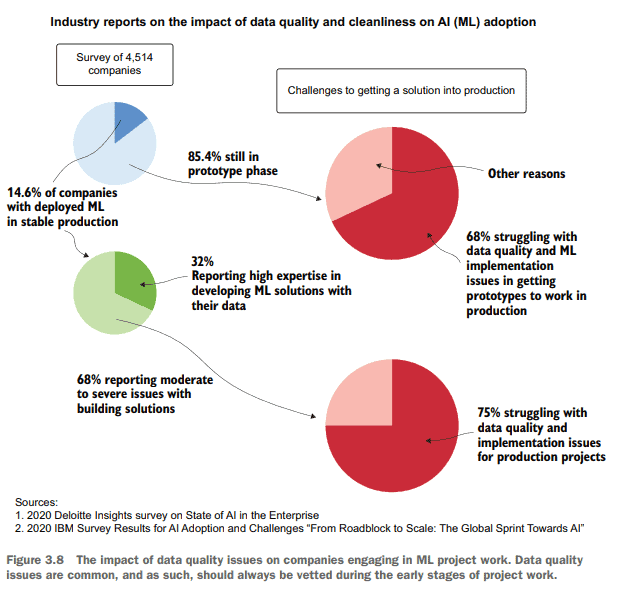
For our use case, the ML team believed that the data they were using was, as told to them by the DE team, quite clean. Reality, for most companies, is a bit more dire than what most would think when it comes to data quality. Figure 3.8 summarizes two industry studies, conducted by IBM and Deloitte, indicating that thousands of companies are struggling with ML implementations, specifically noting problems with data cleanliness. Checking data quality before working on models is pretty important.
机器学习代考
计算机代写|机器学习代写machine learning代考|Basic planning for a project
任何ML项目的计划通常都是从高层开始的。业务部门、执行人员,甚至是DS团队的一名成员提出了使用DS团队的专业知识来解决一个具有挑战性的问题的想法。虽然在早期阶段通常只是一个概念,但这是项目生命周期中的关键时刻。
在我们讨论的场景中,高级概念是个性化。对于一个经验丰富的DS来说,这可能意味着很多事情。对于业务单元的SME来说,它可能意味着DS团队可以想到的许多相同的概念,但也可能不是。从这个想法的早期阶段到基础研究开始之前,参与这个项目的每个人都应该做的第一件事就是开会。这次会议的主题应该集中在一个基本要素上:我们为什么要建设这个?
这听起来像是一个充满敌意或对抗性的问题。听到这句话可能会让一些人大吃一惊。然而,这是最有效和最重要的问题之一,因为它开启了关于人们为什么想要构建项目的真正动机的讨论。是为了增加销量吗?是为了让我们的外部客户更快乐吗?还是为了让人们在网站上浏览更长时间?
这些细微的答案都可以帮助告知这次会议的目标:定义任何ML工作输出的期望。答案还满足模型性能的度量度量标准,以及生产中性能的归属评分(该分数将用于稍后测量$\mathrm{A} / \mathrm{B}$测试)。
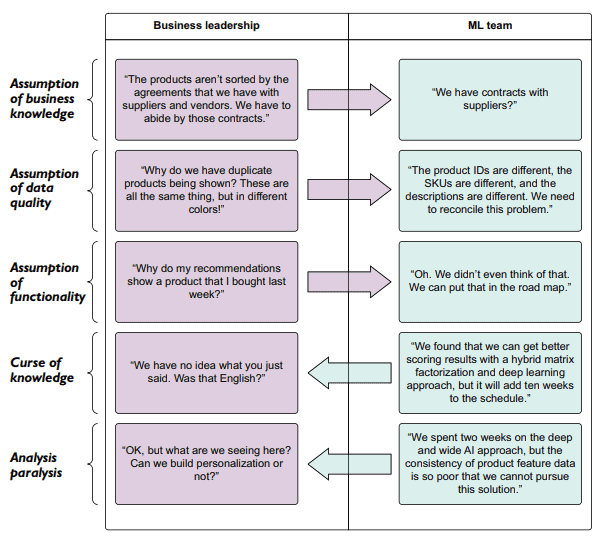
在我们的示例场景中,团队没有问这个重要的“为什么”问题。图3.6显示了业务端和机器学习端期望的差异,因为两组都没有谈论项目的基本方面,而是被自己创造的思维筒仓所占据。机器学习团队完全专注于如何解决问题,而业务团队则对交付的内容抱有期望,错误地假设机器学习团队将“理解它”。
计算机代写|机器学习代写machine learning代考|ASSUMPTION OF BUSINESS KNOWLEDGE
业务知识的假设是一个具有挑战性的问题,特别是对于一个新使用ML的公司,或者对于一个从未与ML团队合作过的公司的业务部门。在我们的示例中,业务领导的假设是ML团队了解领导认为广泛掌握的业务方面。因为没有明确和直接的需求集,所以这个假设没有被确定为一个明确的需求。在数据探索过程中,没有来自业务部门的中小企业参与指导ML团队,他们在构建MVP的过程中也没有办法了解这些信息。
对大多数公司来说,假定自己具备商业知识往往是一条危险的道路。在许多公司,机器学习从业者与企业的内部运作是隔离的。由于他们主要关注的是提供高级分析、预测建模和自动化工具,因此很少有时间用于理解业务运行方式和原因的细微差别。虽然所有人都知道业务的一些明显方面(例如,“我们在我们的网站上销售产品x”),但是期望建模者知道存在这样的业务流程是不合理的,在这个业务流程中,一些商品供应商将在网站上比其他供应商更受欢迎。
获得这些微妙细节的一个好的解决方案是,让一个来自请求为他们构建解决方案的小组(在本例中,是产品营销小组)的中小企业解释他们如何决定网站和应用程序的每个页面上的产品排序。通过这个练习,可以让房间里的每个人都理解可能应用于管理模型输出的特定规则。
数据质量假设
演示输出中重复产品列表的责任并不完全由任何一个团队承担。虽然ML团队成员当然可以计划这是一个问题,但他们并没有确切地意识到它的影响范围。即使他们知道,他们也可能会明智地提到,纠正这个问题不会是演示阶段的一部分(因为需要大量的工作,并且要求原型不能延迟太久)。
这里的主要问题是没有为它做计划。如果不讨论期望,业务领导者对ML团队能力的信心就会受到侵蚀。原型成功与否的客观衡量将在很大程度上被忽略,因为业务成员只关注这样一个事实:对于少数用户的样本数据,前300个用户推荐

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。