如果你也在 怎样代写网络分析Network Analysis这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
网络分析研究实体之间的关系,如个人、组织或文件。在多个层面上操作,它描述并推断单个实体、实体的子集和整个网络的关系属性。
statistics-lab™ 为您的留学生涯保驾护航 在代写网络分析Network Analysis方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写网络分析Network Analysis代写方面经验极为丰富,各种代写网络分析Network Analysis相关的作业也就用不着说。
我们提供的网络分析Network Analysis及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|网络分析代写Network Analysis代考|Genetic interaction network databases
The number of reported genetic interactions are relatively less in comparison to other biological networks. This may due to the involvement of various indirect factors that determine true physical interactions, and hence not possible to elucidate true relationship based on a single source of information. Majority of the interactions are predicted in silico and reported in the databases. Microarray and RNA sequence reads are the most popularly used data sources for predicting such interactions. However, they are sensitive towards the quality, reliability, and availability of the data. Also, the interactions largely depend on the merit of the inference method used. Below, we discuss a few databases dealing with gene-gene relationship networks.
Transcriptional regulatory relationships unraveled by sentence based text mining [10], is a database which consists of human and mouse transcriptional regulatory networks. It comprises of 8,444 and 6,552 TF-target regulatory relationships of 800 human TFs and 828 mouse TFs, respectively.Transcriptional regulatory element database [29], consists of a number of promoters and genes of human, mouse, and rat. This database focuses on GRN’s for each TF-target gene pairs involved in cancer. This database also consists of other features: it contains the genome-wide promoter annotation, gene transcriptional regulation. It also provides an interface, which is user-friendly for extraction of data for all the three species.
Biological general repository [26] for interaction datasets consists of interaction of 70 different organisms, such as the horse, tomato, and castor bean. This repository searches 71,178 for $1,753,686$ protein and genetic interactions, 28,093 chemical associations, and 874,796 posttranslational modifications from major model organism species.
统计代写|网络分析代写Network Analysis代考|Protein-protein network databases
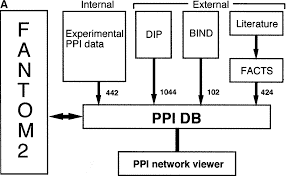
The management of protein-protein interaction (PPI) data presents similar issues as those faced in other domains, i.e., PPI data need to be stored, exchanged, queried, and analyzed. PPI data are the constitutive building blocks for protein interaction networks (PINs). This section discusses main phases and issues of PPI data management [6].
Regarding PPI data storage, main efforts were devoted to the definition of standards for data exchange, such as HUPO PSI-MI, but currently, PPI data are stored as large sets of binary interactions, without taking into account XML-based languages and related XML databases. The storage of PPI data could exploit some already developed storage systems for other graph-based data, such as the triple stores used for storing RDF data or the emerging modeled as graphs, and data manipulation is expressed by graphoriented operations. A graph database proposal for genomics is reported, ${ }^9$ and a project for biochemical pathways is reported in [7].
Moreover, a naming mechanism to identify interactions in a unique way has not been yet been developed, and (binary) interactions are named by naming the interacting proteins.
Also, PPI data querying could benefit from semi-structured or graph databases as summarized below; existing PPI data offer only very simple retrieval mechanisms allowing the retrieval of proteins interacting with a target protein. Current PPI databases surveyed in this paper do not offer sophisticated query mechanisms based on graph manipulation, but, on the other hand, they con-stitute the only available structured repository for interaction data and allow an easy sharing and annotation of such data. Moreover, all the existing databases go beyond the storing of the interaction, but integrates it with functional annotations, sequence information and references to corresponding genes. Finally, they generally provide some visualization tools that presents a subset of interactions in a comprehensive graph.
网络分析代考
统计代写|网络分析代写网络分析代考|遗传相互作用网络数据库
与其他生物网络相比,报告的基因相互作用数量相对较少。这可能是由于涉及到各种间接因素,这些因素决定了真实的物理相互作用,因此不可能根据单一的信息来源来阐明真实的关系。大部分的相互作用都是在硅片中预测并在数据库中报告的。微阵列和RNA序列读取是预测这种相互作用最常用的数据源。然而,他们对数据的质量、可靠性和可用性很敏感。此外,相互作用在很大程度上取决于所使用的推理方法的优点。下面,我们将讨论一些处理基因-基因关系网络的数据库
基于句子的文本挖掘揭示的转录调控关系[10],是一个由人类和小鼠转录调控网络组成的数据库。它分别包括8,444和6,552个tgf -target调控关系,分别涉及800个人类tgf和828个小鼠tgf。转录调控元件数据库[29],由许多启动子和人类、小鼠和大鼠的基因组成。这个数据库关注的是参与癌症的每个tf -靶基因对的GRN。该数据库还包括其他特征:它包含全基因组启动子注释、基因转录调控。它还提供了一个用户友好的界面,用于提取所有三个物种的数据
交互数据集的生物通用存储库[26]包含70种不同生物的交互,如马、番茄和蓖麻豆。该知识库从主要的模式生物物种中搜索了71,178个$1,753,686$蛋白质和遗传相互作用,28,093个化学关联,以及874,796个翻译后修饰
统计代写|网络分析代写网络分析代考|蛋白质-蛋白质网络数据库
.
蛋白质-蛋白质相互作用(PPI)数据的管理与其他领域面临的问题相似,即PPI数据需要存储、交换、查询和分析。PPI数据是蛋白质相互作用网络(pin)的组成模块。本节讨论PPI数据管理的主要阶段和问题[6]
关于PPI数据存储,主要致力于定义数据交换标准,如HUPO PSI-MI,但目前,PPI数据存储为大型二进制交互集,没有考虑到基于XML的语言和相关的XML数据库。PPI数据的存储可以利用一些已经开发的存储系统,用于存储其他基于图的数据,例如用于存储RDF数据或新建模为图的三元存储,数据操作通过面向图的操作表示。报告了基因组学的图形数据库建议,${ }^9$和生物化学途径的项目在[7]中报告。此外,以一种独特的方式识别相互作用的命名机制还没有被开发出来,(二进制)相互作用是通过命名相互作用的蛋白质来命名的
此外,PPI数据查询可以从半结构化或图表数据库中受益,如下所述;现有的PPI数据只提供非常简单的检索机制,允许检索与目标蛋白相互作用的蛋白质。本文调查的当前PPI数据库没有提供基于图操作的复杂查询机制,但另一方面,它们构成了交互数据的唯一可用的结构化存储库,并允许轻松地共享和注释此类数据。此外,现有的所有数据库都超越了相互作用的存储,而是集成了功能注释、序列信息和相应基因的引用。最后,它们通常提供一些可视化工具,在一个全面的图中表示交互的子集

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。