如果你也在 怎样代写统计与机器学习Statistical and Machine Learning这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
统计学的目的是在样本的基础上对人群进行推断。机器学习被用来通过在数据中寻找模式来进行可重复的预测。
statistics-lab™ 为您的留学生涯保驾护航 在代写统计与机器学习Statistical and Machine Learning方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写统计与机器学习Statistical and Machine Learning方面经验极为丰富,各种代写机器学习Statistical and Machine Learning相关的作业也就用不着说。
我们提供的统计与机器学习Statistical and Machine Learning及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等楖率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|统计与机器学习作业代写Statistical and Machine Learning代考|Mathematics and Statistics
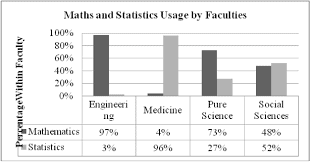
Data scientists need to have strong mathematics and statistics skills to understand the data available, prepare the data needed to train a model, deploy multiple approaches in training and validating the analytical model, assess the model’s results, and finally explain and interpret the model’s outcomes. For example, data scientists need to understand the problem, explain the variability of the target, and conduct controlled tests to evaluate the effect of the values of parameters on the variation of the target values.
Data scientists need mathematics and statistical skills to summarize data to describe past events (known as descriptive statistics). These skills are needed to take the results of a sample and generalize them to a larger population (known as inferential statistics). Data scientists also need these skills to fit models where the response variable is known, and based on that, train a model to classify, predict, or estimate future outcomes (known as supervised modeling). These predictive modeling skills are some of the most widely used skills in data science.
Mathematics and statistics are needed when the business conditions don’t require a specific event, and there is no past behavior to drive the training of a supervised model. The learning process is based on discovering previously unknown patterns in the data set (known as unsupervised modeling). There is no target variable and the main goal is to raise some insights to help companies understand customers and business scenarios.
Data scientists need mathematics and statistics in the field of optimization. This refers to models aiming to find an optimal solution for a problem when constraints and resources exist. An objective function describes the possible solution, which involves the use of limited resources according to some constraints. Mathematics and statistics are also needed in the field of forecasting that is comprised of models to estimate future values in time series data. Based on past values over time, sales, or consumption, it is possible to estimate the future values according to the past behavior. Finally, mathematics and statistics are needed in the field of econometrics that applies statistical models to economic data, usually panel data or longitudinal data, to highlight empirical outcomes to economic relationships. These models are used to evaluate and develop econometric methods.
Mathematics and statistics are needed in the field of text mining. This is a very important field of analytics, particularly nowadays, because most of the data available is unstructured. Imagine all the social media applications, media content, books, articles, and news. There is a huge amount of information in unstructured, formatted data. Analyzing this type of data allows data scientists to infer correlations about topics, identify possible clusters of contents, search specific terms, and much more. Recognizing the sentiments of customers through text data on social media is a very hot topic called sentiment analysis.
统计代写|统计与机器学习作业代写Statistical and Machine Learning代考|Computer Science
The volume of available data today is unprecedented. And most important, the more information about a problem or scenario that is used, the more likely a good model is produced. Due to this data volume, data scientists do not develop models by hand. They need to have computer science skills to develop code, extract, prepare, transform, merge and store data, assess model results, and deploy models in production. All these steps are performed in digital environments. For example, with a tremendous increase in popularity, cloud-based computing is often used to capture data, create models, and deploy them into production environments.
At some point, data scientists need to know how to create and deploy models into the cloud and use containers or other technologies to allow them to port models to places where they are needed. Think about image recognition models using traffic cameras. It is not possible to capture the data and stream it from the camera to a central repository, train a model, and send it back to the camera to score an image. There are thousands of images being captured every second, and this data transfer would make the solution infeasible. The solution is to train the model based on a sample of data and export the model to the device itself, the camera. As the camera captures the images, the model scores and recognizes the image in real time. All these technologies are important to solve the problem. It is much more than just the analytical models, but it involves a series of processes to capture and process data, train models, generalize solutions, and deploy the results where they need to be. Image recognition models show the usefulness of containers, which packages up software code and all its dependencies so that the application runs quickly and reliably from one computing environment to another.
With today’s challenges, data scientists need to have strong computer science skills to deploy the model in different environments, by using distinct frameworks, languages, and storage. Sometimes it is necessary to create programs to capture data or even to expose outcomes. Programming and scripting languages are very important to accomplish these steps. There are several packages that enable data scientists to train supervised and unsupervised models, create forecasting and optimization models, or perform text analytics. New machine learning solutions to develop very complex models are created and released frequently, and to be up to date with new technologies, data scientists need to understand and use these all these new solutions.
统计与机器学习代考
统计代写|统计与机器学习作业代写统计与机器学习代考|数学与统计
数据科学家需要有很强的数学和统计技能来理解可用的数据,准备训练模型所需的数据,在训练和验证分析模型时采用多种方法,评估模型的结果,最后解释和解释模型的结果。例如,数据科学家需要了解问题,解释目标的可变性,并进行受控测试,以评估参数值对目标值变化的影响。数据科学家需要数学和统计技能来总结数据来描述过去的事件(称为描述性统计)。这些技能是获取样本的结果并将其推广到更大的人群所必需的(称为推论统计)。数据科学家还需要这些技能来拟合响应变量已知的模型,并基于此训练模型对未来结果进行分类、预测或估计(称为监督建模)。这些预测建模技能是数据科学中应用最广泛的技能之一
当业务条件不需要特定的事件,并且没有过去的行为来驱动受监督模型的训练时,就需要数学和统计。学习过程基于发现数据集中以前未知的模式(称为无监督建模)。没有目标变量,主要目标是提出一些见解,以帮助公司了解客户和业务场景。数据科学家在优化领域需要数学和统计学。这是指当存在约束和资源时,旨在为问题找到最优解决方案的模型。目标函数描述了可能的解决方案,这涉及到根据某些约束使用有限的资源。预测领域还需要数学和统计学,它是由模型组成的,以估计时间序列数据的未来值。根据过去一段时间、销售或消费的价值,可以根据过去的行为估计未来的价值。最后,计量经济学领域需要数学和统计学,将统计模型应用于经济数据,通常是面板数据或纵向数据,以突出经济关系的经验结果。这些模型被用来评估和发展计量经济学方法。文本挖掘领域需要数学和统计学。这是一个非常重要的分析领域,特别是现在,因为大多数可用的数据都是非结构化的。想象一下所有的社交媒体应用程序、媒体内容、书籍、文章和新闻。在非结构化、格式化的数据中有大量的信息。通过分析这种类型的数据,数据科学家可以推断主题的相关性,识别可能的内容集群,搜索特定的术语,等等。通过社交媒体上的文字数据识别顾客的情绪是一个非常热门的话题,叫做情绪分析
统计代写|统计与机器学习作业代写统计与机器学习代考|计算机科学
今天可用的数据量是前所未有的。最重要的是,所使用的关于问题或场景的信息越多,就越有可能产生一个好的模型。由于数据量很大,数据科学家不会手工开发模型。他们需要具备开发代码、提取、准备、转换、合并和存储数据、评估模型结果以及在生产中部署模型的计算机科学技能。所有这些步骤都在数字环境中执行。例如,随着越来越流行,基于云的计算经常用于捕获数据、创建模型,并将它们部署到生产环境中。在某种程度上,数据科学家需要知道如何创建和部署模型到云中,并使用容器或其他技术来允许他们将模型移植到需要的地方。想想使用交通摄像头的图像识别模型。不可能捕获数据并将其从相机传输到中央存储库,训练模型,并将其发送回相机以对图像进行评分。每秒钟都有成千上万的图像被捕获,这种数据传输将使解决方案变得不可行。解决方案是根据数据样本训练模型,并将模型导出到设备本身,即相机。当相机捕捉到图像时,模型实时对图像进行评分和识别。所有这些技术对解决这个问题都很重要。它不仅仅是分析模型,它还涉及到一系列的过程,以捕获和处理数据,训练模型,概括解决方案,并在需要的地方部署结果。图像识别模型显示了容器的有用性,它将软件代码及其所有依赖项打包,以便应用程序从一个计算环境快速可靠地运行到另一个计算环境
面对今天的挑战,数据科学家需要拥有强大的计算机科学技能,通过使用不同的框架、语言和存储在不同的环境中部署模型。有时需要创建程序来捕获数据甚至公开结果。编程和脚本语言对于完成这些步骤非常重要。有几个软件包使数据科学家能够训练有监督和无监督模型,创建预测和优化模型,或执行文本分析。用于开发非常复杂的模型的新的机器学习解决方案经常被创建和发布,为了跟上新技术的步伐,数据科学家需要理解和使用所有这些新的解决方案

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。统计代写|python代写代考
随机过程代考
在概率论概念中,随机过程是随机变量的集合。 若一随机系统的样本点是随机函数,则称此函数为样本函数,这一随机系统全部样本函数的集合是一个随机过程。 实际应用中,样本函数的一般定义在时间域或者空间域。 随机过程的实例如股票和汇率的波动、语音信号、视频信号、体温的变化,随机运动如布朗运动、随机徘徊等等。
贝叶斯方法代考
贝叶斯统计概念及数据分析表示使用概率陈述回答有关未知参数的研究问题以及统计范式。后验分布包括关于参数的先验分布,和基于观测数据提供关于参数的信息似然模型。根据选择的先验分布和似然模型,后验分布可以解析或近似,例如,马尔科夫链蒙特卡罗 (MCMC) 方法之一。贝叶斯统计概念及数据分析使用后验分布来形成模型参数的各种摘要,包括点估计,如后验平均值、中位数、百分位数和称为可信区间的区间估计。此外,所有关于模型参数的统计检验都可以表示为基于估计后验分布的概率报表。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
statistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
机器学习代写
随着AI的大潮到来,Machine Learning逐渐成为一个新的学习热点。同时与传统CS相比,Machine Learning在其他领域也有着广泛的应用,因此这门学科成为不仅折磨CS专业同学的“小恶魔”,也是折磨生物、化学、统计等其他学科留学生的“大魔王”。学习Machine learning的一大绊脚石在于使用语言众多,跨学科范围广,所以学习起来尤其困难。但是不管你在学习Machine Learning时遇到任何难题,StudyGate专业导师团队都能为你轻松解决。
多元统计分析代考
基础数据: $N$ 个样本, $P$ 个变量数的单样本,组成的横列的数据表
变量定性: 分类和顺序;变量定量:数值
数学公式的角度分为: 因变量与自变量
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。