统计代写|化学计量学作业代写chemometrics代考|Self-Organizing Maps
如果你也在 怎样代写化学计量学chemometrics这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
化学计量学是一门化学学科,它使用数学、统计学和其他采用形式逻辑的方法来设计或选择最佳的测量程序和实验,并通过分析化学数据来提供最大的相关化学信息。
将化学计量学方法与经典方法相比较,也许可以最好地理解它的特点。经典方法旨在理解效应–哪些因素是主要的,哪些因素是可以忽略的–而化学计量学方法则放弃了理解效应的必要性,并指出了其他目标,如预测、模式识别、分类等。
statistics-lab™ 为您的留学生涯保驾护航 在代写化学计量学chemometrics方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写化学计量学chemometrics代写方面经验极为丰富,各种代写化学计量学chemometrics相关的作业也就用不着说。
我们提供的化学计量学chemometrics及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|化学计量学作业代写chemometrics代考|Training SOMs
A SOM is trained by repeatedly presenting the individual samples to the map. At each iteration, the current sample is compared to the codebook vectors. The most similar codebook vector (the “winning unit”) is then shifted slightly in the direction of the mapped object. This is achieved by replacing it with a weighted average of the old values of the codebook vector, $c v_{i}$, and the values of the new object obj:
$$
c v_{i+1}=(1-\alpha) c v_{i}+\alpha o b j
$$
The weight, also called the learning rate $\alpha$, is a small value, typically in the order of $0.05$, and decreases during training so that the final adjustments are very small.
As we shall see in Sect. $6.2 .1$, the algorithm is very similar in spirit to the one used in $k$-means clustering, where cluster centers and memberships are alternatingly estimated in an iterative fashion. The crucial difference is that not only the winning unit is updated, but also the other units in the “neighborhood” of the winning unit. Initially, the neighborhood is fairly large, but during training it decreases so that finally only the winning unit is updated. The effect is that neighboring units in general are more similar than units far away. Or, to put it differently, moving through the map by jumping from one unit to its neighbor would see gradual and more or less smooth transitions in the values of the codebook vectors. This is clearly visible in the mapping of the autoscaled wine data to a 5-by-4 SOM, using the kohonen package:
The result is shown in Fig. 5.2. Units in this example are arranged in a hexagonal fashion and are numbered row-wise from left to right, starting from the bottom left. The first unit at the bottom left for instance, is characterized by relatively large values of alcohol, flavonoids and proanth; the second unit, to the right of the first, has lower values for these variables, but still is quite similar to unit number one.
The codebook vectors are usually initialized by a random set of objects from the data, but also random values in the range of the data can be employed. Sometimes a grid is used, based on the plane formed by the first two PCs. In practice, the initialization method will hardly ever matter, however, starting from other random initial values will lead to different maps. The conclusions drawn from the different maps, however, tend to be very similar.
统计代写|化学计量学作业代写chemometrics代考|Visualization
Several different visualization methods are provided in the kohonen package: one can look at the codebook vectors, the mapping of the samples, and one can also use SOMs for prediction. Here, only a few examples are shown. For more information, consult the manual pages of the plot. kohonen function, or the software description (Wehrens and Buydens 2007; Wehrens and Kruisselbrink 2018).
For multivariate data, the locations of the codebook vectors can not be visualized as was done for the two-dimensional data in Fig. 5.1. In the kohonen package, the default is to show segment plots, such as in Fig. $5.2$ if the number of variables is smaller than 15, and a line plot otherwise. One can also zoom in and concentrate on the values of just one of the variables:
$>\operatorname{for}(1 \ln c(1,8,11,13))$
- plotiwines.som. “property”.
for $(1 \ln c(1,8,11,13))$
$+\quad$ plot $($ wines.som, “property”
$+\quad$ property = getcodes(wines.som, 1) $[, 1] .$
$+\quad$ main = colnames $($ wines $)[1])$
property = getcodes (wines.som, 1) $[, 1]$.
main = colnames (Wines $[1]}$Clearly, in these plots, shown in Fig. 5.3, there are regions in the map where specific variables have high values, and other regions where they are low. Areas of high values and low values are much more easily recognized than in Fig.5.2. Note the use of the accessor function getcodes here.
Perhaps the most important visualization is to show which objects map in which units. In the kohonen package, this is achieved by supplying the the type = “mapping ” argument to the plotting function. It allows for using different plotting characters and colors (see Fig. 5.4):
plot (wines.som, type = “mapping” ,
$c o 1=a s .$ integer (vintages), pch $=$ as. integer (vintages) )
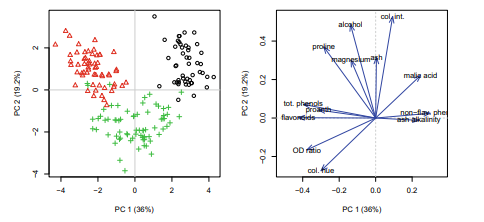
Again, one can see that the wines are well separated. Some class overlap remains, especially for the Grignolinos (pluses in the figure). These plots can be used to make predictions for new data points: when the majority of the objects in a unit are, e.g., of the Barbera class, one can hypothesize that this is also the most probably class for future wines that end up in that unit. Such predictions can play a role in determining authenticity, an economically very important application.
Since SOMs are often used to detect grouping in the data, it makes sense to look at the codebook vectors more closely, and investigate if there are obvious class boundaries in the map-areas where the differences between neighboring units are relatively large. Using a color code based on the average distance to neighbors one can get a quick and simple idea of where the class boundaries can be found. This
统计代写|化学计量学作业代写chemometrics代考|Application
The main attraction of SOMs lies in the applicability to large data sets; even if the data are too large to be loaded in memory in one go, one can train the map sequentially on (random) subsets of the data. It is also possible to update the map when new data points become available. In this way, SOMs provide a intuitive and simple visualization of large data sets in a way that is complementary to PCA. An especially interesting feature is that these maps can show grouping of the data without explicitly performing a clustering. In large maps, sudden transitions between units, as visualized by, e.g., a U-matrix plot, enable one to view the major structure at a glance. In smaller maps, this often does not show clear differences between groups-see Fig. $5.5$ for an example. One way to find groups is to perform a clustering of the individual codebook vectors. The advantage of clustering the codebook vectors rather than the original data is that the number of units is usually orders of magnitude smaller than the number of objects.
The kohonen package used in this chapter, originally based on the class package (Venables and Ripley 2002), has several noteworthy features not discussed yet (Wehrens and Kruisselbrink 2018). It can use distance functions other than the usual Euclidean distance, which might be extremely useful for some data sets, often avoiding the need for prior data transformations. One example is the WCC function mentioned earlier: this can be used to group sets of X-ray powder diffractograms where the position rather than the position of peaks contains the primary information (Wehrens and Willighagen 2006; Wehrens and Kruisselbrink 2018). For numerical variables, the sum-of-squares distance is the default (slightly faster than the Euclidean distance); for factors, the Tanimoto distance. In the kohonen package it is possible to supply several different data layers, where the rows in each layer correspond to different bits of information on the same objects. Separate distance functions can be defined for each single layer, which are then combined into one overall distance measure using weights that can be defined by the user. Apart from the usual “online” training algorithm described in this chapter, a “batch” algorithm is implemented as well, where codebook vectors are not updated until all records have been presented to the map. One advantage of the batch algorithm is that it dispenses with one of the parameters of the SOM: the learning rate $\alpha$ is no longer needed. The main disadvantage is that it is sometimes less stable and more likely to end up in a local optimum. The batch algorithm also allows for parallel execution by distributing the comparisons of objects to all codebook vectors over several cores (Lawrence et al. 1999) which may lead to considerable savings with larger data sets (Wehrens and Kruisselbrink 2018).
化学计量学代写
统计代写|化学计量学作业代写chemometrics代考|Training SOMs
通过将单个样本重复呈现到地图上来训练 SOM。在每次迭代中,将当前样本与码本向量进行比较。最相似的码本向量(“获胜单元”)然后在映射对象的方向上略微移动。这是通过用码本向量的旧值的加权平均值替换它来实现的,C在一世,以及新对象 obj 的值:
C在一世+1=(1−一种)C在一世+一种这bj
权重,也称为学习率一种, 是一个很小的值,通常为0.05, 并在训练期间减小,因此最终调整非常小。
正如我们将在 Sect 中看到的那样。6.2.1, 该算法在精神上与ķ- 表示聚类,其中聚类中心和成员资格以迭代方式交替估计。关键的区别在于,不仅获胜单元被更新,而且获胜单元“邻居”中的其他单元也被更新。最初,邻域相当大,但在训练期间它会减小,因此最终只有获胜单元被更新。其效果是,通常相邻的单元比远处的单元更相似。或者,换一种说法,通过从一个单元跳到其相邻单元在地图中移动会看到码本向量值的渐进和或多或少平滑的过渡。这在使用 kohonen 包将自动缩放的葡萄酒数据映射到 5×4 SOM 中清晰可见:
结果如图 5.2 所示。此示例中的单元以六边形方式排列,并从左到右按行编号,从左下角开始。例如左下角的第一个单元,其特点是酒精、类黄酮和原蒽的含量相对较高;第二个单元,在第一个单元的右侧,这些变量的值较低,但仍然与第一个单元非常相似。
码本向量通常由数据中的一组随机对象初始化,但也可以使用数据范围内的随机值。有时会使用网格,基于前两台 PC 形成的平面。实际上,初始化方法几乎无关紧要,但是,从其他随机初始值开始会导致不同的映射。然而,从不同地图得出的结论往往非常相似。
统计代写|化学计量学作业代写chemometrics代考|Visualization
kohonen 包中提供了几种不同的可视化方法:一种可以查看码本向量、样本的映射,还可以使用 SOM 进行预测。这里只展示了几个例子。有关更多信息,请参阅该图的手册页。kohonen 函数或软件描述(Wehrens 和 Buydens 2007;Wehrens 和 Kruisselbrink 2018)。
对于多变量数据,码本向量的位置不能像图 5.1 中的二维数据那样可视化。在 kohonen 包中,默认显示分段图,如图所示。5.2如果变量数小于 15,否则为线图。也可以放大并专注于其中一个变量的值:
>为了(1lnC(1,8,11,13))
- plotiwines.som。“财产”。
为了(1lnC(1,8,11,13))
+阴谋(wines.som,“财产”
+属性 = getcodes(wines.som, 1)[,1].
+主要 = 列名(葡萄酒)[1])
属性 = getcodes (wines.som, 1)[,1].
main = colnames(葡萄酒[1]}[1]}显然,在这些图中,如图 5.3 所示,地图中有特定变量值较高的区域,而其他区域则较低。高值和低值区域比图 5.2 更容易识别。请注意此处使用访问器函数 getcodes。
也许最重要的可视化是显示哪些对象映射到哪些单位。在 kohonen 包中,这是通过向绘图函数提供 type = “mapping” 参数来实现的。它允许使用不同的绘图字符和颜色(见图 5.4):
情节(wines.som,类型=“映射”,
C这1=一种s.整数(年份),pch=作为。整数(年份))
再一次,人们可以看到葡萄酒被很好地分开了。一些类重叠仍然存在,特别是对于 Grignolinos(图中的加号)。这些图可用于对新数据点进行预测:当一个单元中的大多数对象是,例如,巴贝拉类时,人们可以假设这也是未来葡萄酒最有可能出现的类别单元。这样的预测可以在确定真实性方面发挥作用,这是一个经济上非常重要的应用。
由于 SOM 通常用于检测数据中的分组,因此更仔细地查看码本向量并调查相邻单元之间差异相对较大的地图区域中是否存在明显的类边界是有意义的。使用基于与邻居的平均距离的颜色代码,可以快速简单地了解可以找到类边界的位置。这
统计代写|化学计量学作业代写chemometrics代考|Application
SOM 的主要吸引力在于对大数据集的适用性;即使数据太大而无法一次性加载到内存中,也可以在数据的(随机)子集上按顺序训练地图。当新的数据点可用时,也可以更新地图。通过这种方式,SOM 以与 PCA 互补的方式提供了大型数据集的直观和简单的可视化。一个特别有趣的功能是这些地图可以显示数据的分组,而无需明确执行聚类。在大型地图中,单元之间的突然转换,例如通过 U 矩阵图可视化,使人们能够一目了然地查看主要结构。在较小的地图中,这通常不会显示组之间的明显差异——见图。5.5例如。找到组的一种方法是对各个码本向量进行聚类。对码本向量而不是原始数据进行聚类的优点是单元的数量通常比对象的数量小几个数量级。
本章中使用的 kohonen 包最初基于类包(Venables 和 Ripley 2002),有几个值得注意的功能尚未讨论(Wehrens 和 Kruisselbrink 2018)。它可以使用通常的欧几里得距离以外的距离函数,这对于某些数据集可能非常有用,通常避免了对先前数据转换的需要。一个例子是前面提到的 WCC 函数:这可用于对一组 X 射线粉末衍射图进行分组,其中峰的位置而不是峰的位置包含主要信息(Wehrens 和 Willighagen 2006;Wehrens 和 Kruisselbrink 2018)。对于数值变量,平方和距离是默认的(比欧几里得距离稍快);对于因素,谷本距离。在 kohonen 包中,可以提供几个不同的数据层,其中每一层中的行对应于同一对象的不同信息位。可以为每一层定义单独的距离函数,然后使用可由用户定义的权重将其组合成一个整体距离度量。除了本章描述的通常的“在线”训练算法外,还实现了“批量”算法,其中码本向量在所有记录都呈现给地图之前不会更新。批处理算法的一个优点是它省去了 SOM 的参数之一:学习率 然后使用可由用户定义的权重将其组合成一个整体距离度量。除了本章描述的通常的“在线”训练算法外,还实现了“批量”算法,其中码本向量在所有记录都呈现给地图之前不会更新。批处理算法的一个优点是它省去了 SOM 的参数之一:学习率 然后使用可由用户定义的权重将其组合成一个整体距离度量。除了本章描述的通常的“在线”训练算法外,还实现了“批量”算法,其中码本向量在所有记录都呈现给地图之前不会更新。批处理算法的一个优点是它省去了 SOM 的参数之一:学习率一种不再需要。主要缺点是它有时不太稳定,更有可能最终达到局部最优。批处理算法还允许通过将对象与所有码本向量的比较分布在多个内核上进行并行执行(Lawrence et al. 1999),这可能会通过更大的数据集节省大量成本(Wehrens 和 Kruisselbrink 2018)。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。