机器学习代写|深度学习project代写deep learning代考|DEEP LEARNING TECHNIQUES FOR THE PREDICTION OF EPILEPSY
如果你也在 怎样代写深度学习deep learning这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
深度学习是机器学习的一个子集,它本质上是一个具有三层或更多层的神经网络。这些神经网络试图模拟人脑的行为–尽管远未达到与之匹配的能力–允许它从大量数据中 “学习”。
statistics-lab™ 为您的留学生涯保驾护航 在代写深度学习deep learning方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写深度学习deep learning代写方面经验极为丰富,各种代写深度学习deep learning相关的作业也就用不着说。
我们提供的深度学习deep learning及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
机器学习代写|深度学习project代写deep learning代考|ARTIFICIAL INTELLIGENCE
Deep learning helps simulation techniques with various computing layers to gain several stages of abstraction for data representations. These techniques have vastly enhanced the position in voice detection, visual target recognition, particle identification as well as a variety of other fields including drug discovery as well as genomics. Deep learning uses the backpropagation method to show how a computer can adjust the input variables that are employed to measure the value in every layer from the description in the subsequent layer revealing detailed structure in huge volumes of data [1]. Deep learning is perhaps the highest accuracy, supervised as well as time and cost-effective machine learning method. Deep learning is not a limited learning methodology rather it encompasses a wide range of methods that can be employed in a wide range of complex situations [2].
Let’s start with a definition of intelligence. Intelligence is defined as the ability to learn and solve issues. Its primary goal is to create computers so clever that they can act intelligently in the same way that humans do. If a computer learns new information, it can intelligently solve real-world problems based on previous experiences. As we all know, intelligence is the capacity to learn and solve issues, and intelligence is attained via knowledge, which is attained in part via information, which is attained via prior experiences and experiences obtained through training. Finally, by combining all of the elements, we can conclude that artificial intelligence can obtain knowledge and apply it to execute tasks intelligently based on their previous experiences. Reasoning, learning, problem solving, and perception are all aspects of intelligence. Artificial intelligence systems are required to minimize human workload. Natural Language Processing (NLP), Speech Recognition, Healthcare, Vision Systems, and Automotive are just a few of the applications. An agent and its surroundings make up an Artificial Intelligence system. The environment is perceived by sensors, and the environment is reacted to by effectors. An intelligent agent sets objectives and is extremely interested in achieving them. Artificial Intelligence has developed some tools to help handle tough and complicated issues, including neural networks, languages, search and optimization, and uncertain reasoning, among others.
机器学习代写|深度学习project代写deep learning代考|MACHINE LEARNING
Machine learning is the subset of artificial intelligence (AI). Machine learning, as the name implies, is the capacity of a machine to learn. Machine learning is a branch of computer science that allows computers to learn and solve problems without being explicitly programmed. Here, we create a machine that performs duties similar to those performed by humans to decrease human labor. It is a branch of research that enables computers to learn new things using information fed to them and to produce more efficient output using that information. It is employed in a variety of professions and has gained notoriety in a variety of sectors. It is a fantastic technology that allows machines or computers to learn and solve complicated problems.
The term “deep learning” comes first from artificial neural networks [3]. A convolutional neural network is perhaps the most essential of the several deep learning networks since it considerably encourages the growth of image analysis. Generative adversarial network as a novel deep learning model offers up new boundaries for the study as well as application of deep learning which has lately received a lot of attention [4].
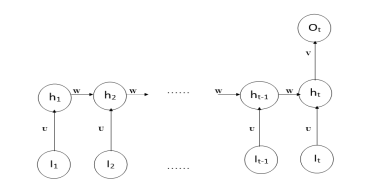
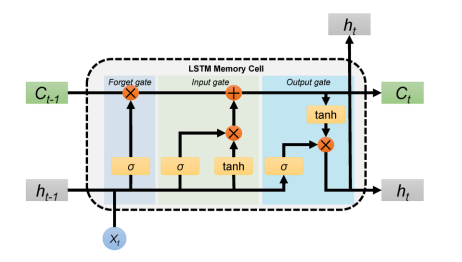
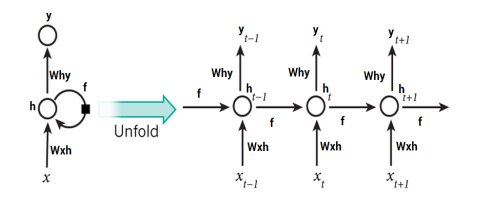
The biggest thrilling utilization of backpropagation since it was initially developed was for recurrent neural networks (RNNs) simulation. RNNs are also preferred for functions that need sequential inputs, like expression and vocabulary. It produces the output based on previous computation by using sequential information. Recurrent Neural Networks are similar to neural networks, however, they do not function in the same way. As humans, we do not think from the ground up. For example, if we’re watching a movie, we may guess what will happen next based on what we know about the prior one. A typical neural network, on the other hand, is unable to predict the next action in the film. Recurrent Neural Networks can address challenges like these. In a recurrent neural network, there is a loop in the network that keeps the data. It can take more than one input vector and produce more than one output vector. Recurrent neural networks use memory cells that are capable to capture information about long sequences. RNNs are extremely strong dynamic structures, although teaching them has proven difficult because backpropagated gradients expand or retreat at every time stage, causing them to burst or disappear over several time stages [7].
机器学习代写|深度学习project代写deep learning代考|CONVOLUTIONAL NEURAL NETWORK
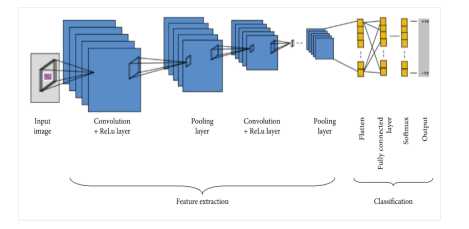
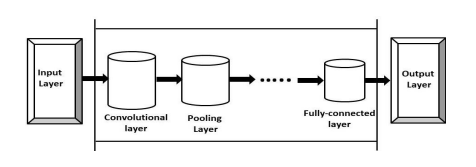
The neural network image processing group was the first to create the convolutional neural network. Convolutional neural networks are a type of deep neural network used in deep learning to analyze pictures.
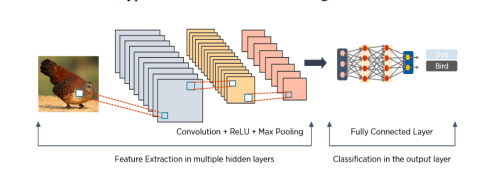
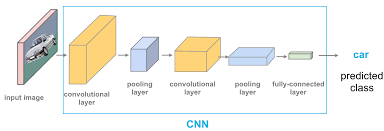
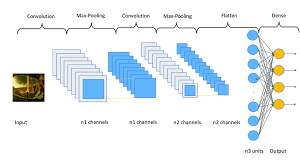
Convolutional neural networks are extensively employed in image identification, object identification, picture classifications, and face identification, among other applications. Convolution takes an input picture, works on it, and then uses the values to categorize it (either cat or dog, pen or pencil). ConvNets are developed to accommodate data in the form of several arrays, such as a color image made up of three $2 \mathrm{D}$ arrays representing pixel elevations in each of the color channels. As attribute extractors, a CNN uses two operations as convolution and pooling. As in a multi-layer perceptron, the output of this series of operations is bound to a completely connected layer. Convolutional neural networks are often used on text in Natural Language Processing. There are two types of pooling used: max-pooling and average-pooling. When we use CNN for text instead of images, we display the text with a 1-Dimensional string. CNN is mostly used in sentence classification in NLP tasks. Microsoft earlier released a range of optical character recognition software, as well as handwriting recognition software, specifically focuses on ConvNet [5]. ConvNets were still used to recognize objects in real photographs, such as faces as well as legs, and even to recognize faces in the early 1990 s [6].
Generative adversarial network (GAN) is a novel deep learning concept that includes a unique neural network model that trains generator as well as discriminator at the same time. The generator’s job is to know and understand the probability distribution of actual images and afterward add random noise to them to make false images, whereas the discriminator’s job is to determine whether a source variable is genuine or not [17]. The discriminator, as well as generator, has been tweaked to enhance their performance. The generative adversarial network training process is unique in that it has been using backpropagation to train as well as utilizes the confrontation of two neural networks as training metric, significantly reducing the training problem as well as improving the training effectiveness of the induced model. A generative adversarial network provides an opportunity to learn deep representation without having to label your training data extensively [18]. One of the most often used generative adversarial network applications is computer vision [19].
深度学习代写
机器学习代写|深度学习project代写deep learning代考|ARTIFICIAL INTELLIGENCE
深度学习帮助具有各种计算层的模拟技术获得数据表示的多个抽象阶段。这些技术极大地提高了语音检测、视觉目标识别、粒子识别以及包括药物发现和基因组学在内的各种其他领域的地位。深度学习使用反向传播方法来展示计算机如何调整输入变量,这些输入变量用于从后续层的描述中测量每一层的值,从而揭示大量数据的详细结构 [1]。深度学习可能是精度最高的、有监督的以及时间和成本效益最高的机器学习方法。
让我们从智力的定义开始。智力被定义为学习和解决问题的能力。它的主要目标是创造出非常聪明的计算机,它们可以像人类一样智能地行动。如果计算机学习新信息,它可以根据以前的经验智能地解决现实世界的问题。众所周知,智力是学习和解决问题的能力,而智力是通过知识获得的,知识是通过信息获得的,信息是通过先前的经验和通过培训获得的经验获得的。最后,通过结合所有要素,我们可以得出结论,人工智能可以获取知识并将其应用于基于他们以前的经验智能地执行任务。推理、学习、解决问题和感知都是智能的各个方面。人工智能系统需要最大限度地减少人类的工作量。自然语言处理 (NLP)、语音识别、医疗保健、视觉系统和汽车只是应用中的一小部分。代理及其周围环境构成了一个人工智能系统。环境由传感器感知,环境由效应器做出反应。智能代理设定目标并且对实现这些目标非常感兴趣。人工智能开发了一些工具来帮助处理棘手和复杂的问题,包括神经网络、语言、搜索和优化以及不确定推理等。代理及其周围环境构成了一个人工智能系统。环境由传感器感知,环境由效应器做出反应。智能代理设定目标并且对实现这些目标非常感兴趣。人工智能开发了一些工具来帮助处理棘手和复杂的问题,包括神经网络、语言、搜索和优化以及不确定推理等。代理及其周围环境构成了一个人工智能系统。环境由传感器感知,环境由效应器做出反应。智能代理设定目标并且对实现这些目标非常感兴趣。人工智能开发了一些工具来帮助处理棘手和复杂的问题,包括神经网络、语言、搜索和优化以及不确定推理等。
机器学习代写|深度学习project代写deep learning代考|MACHINE LEARNING
机器学习是人工智能 (AI) 的子集。机器学习,顾名思义,就是机器学习的能力。机器学习是计算机科学的一个分支,它允许计算机在没有明确编程的情况下学习和解决问题。在这里,我们创建了一台执行与人类相似的任务的机器,以减少人工。它是一个研究分支,它使计算机能够使用提供给它们的信息来学习新事物,并使用该信息产生更有效的输出。它受雇于各种职业,并在各个领域声名狼藉。这是一项了不起的技术,可以让机器或计算机学习和解决复杂的问题。
“深度学习”一词首先来自人工神经网络 [3]。卷积神经网络可能是几个深度学习网络中最重要的,因为它极大地促进了图像分析的发展。生成对抗网络作为一种新颖的深度学习模型,为深度学习的研究和应用提供了新的界限,最近受到了很多关注[4]。
自最初开发以来,反向传播最令人兴奋的用途是用于循环神经网络 (RNN) 模拟。对于需要顺序输入的函数,如表达式和词汇表,RNN 也是首选。它使用顺序信息基于先前的计算产生输出。循环神经网络与神经网络相似,但是它们的功能不同。作为人类,我们不会从头开始思考。例如,如果我们正在看一部电影,我们可能会根据我们对前一部电影的了解来猜测接下来会发生什么。另一方面,典型的神经网络无法预测电影中的下一个动作。循环神经网络可以解决这些挑战。在循环神经网络中,网络中有一个循环来保存数据。它可以采用多个输入向量并产生多个输出向量。循环神经网络使用能够捕捉长序列信息的记忆细胞。RNN 是非常强大的动态结构,尽管教学它们已被证明是困难的,因为反向传播的梯度在每个时间阶段都会扩大或缩小,导致它们在多个时间阶段内爆发或消失 [7]。
机器学习代写|深度学习project代写deep learning代考|CONVOLUTIONAL NEURAL NETWORK
神经网络图像处理组率先创建了卷积神经网络。卷积神经网络是一种用于深度学习分析图片的深度神经网络。
卷积神经网络广泛用于图像识别、物体识别、图片分类和人脸识别等应用。卷积获取输入图片,对其进行处理,然后使用这些值对其进行分类(猫或狗,钢笔或铅笔)。ConvNets 被开发来容纳几个数组形式的数据,例如由三个组成的彩色图像2D表示每个颜色通道中的像素高度的数组。作为属性提取器,CNN 使用卷积和池化两种操作。就像在多层感知器中一样,这一系列操作的输出绑定到一个完全连接的层。卷积神经网络通常用于自然语言处理中的文本。池化有两种类型:最大池化和平均池化。当我们将 CNN 用于文本而不是图像时,我们使用一维字符串显示文本。CNN 主要用于 NLP 任务中的句子分类。微软早些时候发布了一系列光学字符识别软件,以及手写识别软件,特别关注 ConvNet [5]。ConvNets 仍然被用来识别真实照片中的物体,比如人脸和腿,
生成对抗网络 (GAN) 是一种新颖的深度学习概念,它包括一个独特的神经网络模型,可以同时训练生成器和判别器。生成器的工作是了解和理解实际图像的概率分布,然后向它们添加随机噪声以制作虚假图像,而鉴别器的工作是确定源变量是否真实[17]。鉴别器和生成器已经过调整以提高它们的性能。生成对抗网络训练过程的独特之处在于它一直使用反向传播进行训练,并利用两个神经网络的对抗作为训练指标,显着减少了训练问题并提高了诱导模型的训练效果。生成对抗网络提供了学习深度表示的机会,而无需大量标记您的训练数据 [18]。最常用的生成对抗网络应用之一是计算机视觉 [19]。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。