计算机代写|数字硬件系统代写Digital hardware systems代考|ECE2544
如果你也在 怎样代写数字硬件系统Digital hardware systems这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
数字硬件是指与有线电视和卫星电视系统以及DVD和DVC播放器有关的集成接收器解码器或其他视频解码器,其中每一个都包含一个集成电路,该集成电路包含一个用于实施付费传输过程的装置。
statistics-lab™ 为您的留学生涯保驾护航 在代写数字硬件系统Digital hardware systems方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写数字硬件系统Digital hardware systems代写方面经验极为丰富,各种代写数字硬件系统Digital hardware systems相关的作业也就用不着说。
我们提供的数字硬件系统Digital hardware systems及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
计算机代写|数字硬件系统代写Digital hardware systems代考|Routing Architecture
The routing architecture of an FPLD determines a way in which the programmable switches and wiring segments are positioned to allow the programmable interconnection of logic cells. A routing architecture for an FPLD must meet two criteria: routability and speed. Routability refers to the capability of an FPLD to accommodate all the nets of a typical application, despite the fact that the wiring segments must be defined at the time the blank FPLD is made. Only switches connecting wiring segments can be programmed (customized) for a specific application, not the numbers, lengths or locations of the wiring segments themselves. The goal is to provide a sufficient number of wiring segments while not wasting chip area. It is also important that the routing of an application can be determined by an automated algorithm with minimal intervention.
Propagation delay through the routing is a major factor in FPLD performance. After routing an FPLD, the exact segments and switches used to establish the net are known and the delay from the driving output to each input can be computed. Any programmable switch (EPROM, pass-transistor, or antifuse) has a significant resistance and capacitance. Each time a signal passes through a programmable switch, another RC stage is added to the propagation delay. For a fixed R and C, the propagation delay mounts quadratically with the number of series RC stages. The use of a low resistance switch, such as antifuse, keeps the delay low and its distribution tight. Of equal significance is optimization of the routing architecture. Routing architectures of some commercial FPLD families are presented in this section.
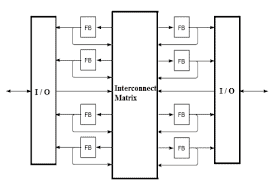
In order to present commercial routing architectures, we will use the routing architecture model shown in Figure 1.17. First, a few definitions are introduced in order to form a unified viewpoint when considering routing architectures.
A wire segment is a wire unbroken by programmable switches. One or more switches may attach to a wire segment. Typically, one switch is attached to the each end of a wire segment. A track is a sequence of one or more wire segments in a line. A routing channel is a group of parallel tracks.
计算机代写|数字硬件系统代写Digital hardware systems代考|FPLD Applications
FPLDs have been used in a large number of applications, ranging from the simple ones replacing glue logic to those implementing new computing paradigms, that are not possible using other technologies. In this section we will list some of them, as to make a classification into some typical groups, and emphasize most important features of each group.
CPLDs are used in applications that can efficiently use wide fan-in of AND/OR gates and do not need a large number of flip-flops. Examples of such circuits are various kinds of finite state machines. On the other hand, FPGAs with a large number of flip-flops are better suited for the applications that need memory functions and complex data paths. Also, due to their easy reprogrammability they become an important element of prototyping digital systems designs. As such they enable emulation of entire complex systems, and in many cases also their final implementation. Finally, all FPGAs as the static RAM based circuits allow at least a minimum level of dynamic reconfigurability. While all of them allow full device reconfiguration by downloading another bitstream (configuration file), some of them also allow partial reconfiguration. The partial reconfiguration provides change of the function of a part of the device, while the remaining part operates without disruption of the system function.
In order to visualize the range of current and potential applications, we have to mention typical features of FPLDs in terms of their capacity and speed. Today the leading suppliers of FPLDs offer devices containing up to 500,000 equivalent (twoinput NAND) gates, with a perspective to quadruple this figure in the next two to three years. These devices are delivered in a number of configurations so that application designers have the choice to fit their designs into a device with minimal capacity. They also come in a range of speed grades and different packages with different number of input/output pins. The number of pins sometimes exceeds 600 . The speed of circuits implemented in FPLDs varies depending primarily on application and design approach. As an illustration, all major manufacturers offer devices that provide full compliance with 64-bit $66 \mathrm{MHz}$ PCI-bus requirements.
数字硬件系统代考
计算机代写|数字硬件系统代写Digital hardware systems代考|Routing Architecture
FPLD 的路由架构决定了可编程开关和布线段的定位方式,以实现逻辑单元的可编程互连。FPLD 的布线架构必须满足两个标准:可布线性和速度。可布线性是指 FPLD 适应典型应用的所有网络的能力,尽管必须在制作空白 FPLD 时定义布线段。只有连接接线段的开关才能针对特定应用进行编程(定制),而不是接线段本身的数量、长度或位置。目标是在不浪费芯片面积的情况下提供足够数量的布线段。同样重要的是,应用程序的路由可以由自动化算法以最少的干预来确定。
通过路由的传播延迟是影响 FPLD 性能的主要因素。在对 FPLD 进行布线后,用于建立网络的确切段和开关是已知的,并且可以计算从驱动输出到每个输入的延迟。任何可编程开关(EPROM、传输晶体管或反熔丝)都有很大的电阻和电容。每次信号通过可编程开关时,传播延迟都会增加另一个 RC 级。对于固定的 R 和 C,传播延迟与串联 RC 级的数量呈二次方关系。使用低电阻开关(例如反熔丝)可保持较低的延迟和紧凑的分布。同样重要的是路由架构的优化。本节介绍了一些商业 FPLD 系列的路由架构。
为了展示商业路由架构,我们将使用图1.17所示的路由架构模型。首先,介绍一些定义,以便在考虑路由体系结构时形成统一的观点。
线段是可编程开关未断开的线。一个或多个开关可以连接到电线段。通常,一个开关连接到线段的每一端。轨道是一条线上的一系列一个或多个线段。路由通道是一组平行的轨道。
计算机代写|数字硬件系统代写Digital hardware systems代考|FPLD Applications
FPLD 已用于大量应用,从替换胶合逻辑的简单应用到实现新计算范例的应用,这些都是使用其他技术无法实现的。在本节中,我们将列出其中的一些,以将其分类为一些典型的组,并强调每个组的最重要特征。
CPLD 用于可有效使用宽扇入 AND/OR 门且不需要大量触发器的应用。这种电路的例子是各种有限状态机。另一方面,具有大量触发器的 FPGA 更适合需要存储功能和复杂数据路径的应用。此外,由于它们易于重新编程,它们成为数字系统设计原型设计的重要元素。因此,它们可以模拟整个复杂系统,在许多情况下还可以模拟它们的最终实施。最后,作为基于静态 RAM 的电路的所有 FPGA 至少允许最低水平的动态可重构性。虽然它们都允许通过下载另一个比特流(配置文件)进行完整的设备重新配置,但其中一些还允许部分重新配置。
为了可视化当前和潜在应用的范围,我们不得不提及 FPLD 在容量和速度方面的典型特征。如今,领先的 FPLD 供应商提供包含多达 500,000 个等效(双输入 NAND)门的器件,并有望在未来两到三年内将这一数字翻两番。这些设备以多种配置交付,因此应用程序设计人员可以选择将他们的设计融入具有最小容量的设备中。它们还具有一系列速度等级和具有不同数量输入/输出引脚的不同封装。引脚数有时会超过 600 个。在 FPLD 中实现的电路速度主要取决于应用和设计方法。例如,所有主要制造商都提供完全符合 64 位的设备66米H和PCI 总线要求。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。