机器学习代写|流形学习代写manifold data learning代考|ICML2022
如果你也在 怎样代写流形学习manifold data learning这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
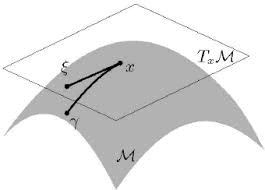
流形学习是机器学习的一个流行且快速发展的子领域,它基于一个假设,即一个人的观察数据位于嵌入高维空间的低维流形上。本文介绍了流形学习的数学观点,深入探讨了核学习、谱图理论和微分几何的交叉点。重点放在图和流形之间的显著相互作用上,这构成了流形正则化技术的广泛使用的基础。
statistics-lab™ 为您的留学生涯保驾护航 在代写流形学习manifold data learning方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写流形学习manifold data learning代写方面经验极为丰富,各种代写流形学习manifold data learning相关的作业也就用不着说。
我们提供的流形学习manifold data learning及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
机器学习代写|流形学习代写manifold data learning代考|History of Probabilistic Dimensionality Reduction
The probabilistic variants of many of the spectral dimensionality reduction methods were gradually developed and proposed. For example, probabilistic $P C A[50,62]$ is the stochastic version of PCA, and it assumes that data are obtained by the addition of noise to the linear projection of a latent random variable. It can be demonstrated that PCA is a special case of probabilistic PCA, where the variance of noise tends to zero. The probabilistic PCA, itself, is a special case of factor analysis [17]. In the factor analysis, the different dimensions of noise can be correlated, while they are uncorrelated and isometric in the probabilistic PCA. The factor analysis and the probabilistic PCA use expectation maximization and variational inference on the data.
The linear spectral dimensionality reduction methods, such as PCA and FDA, learn a projection matrix from the data for better data representation or more separation between classes. In 1984, it was surprisingly determined that if a random matrix is used for the linear projection of the data, without being learned from the data, it represents data well! The correctness of this mystery of random projection was proven by the Johnson-Lindenstrauss lemma [33], which put a bound on the error of preservation of the distances in the subspace. Later, nonlinear variants of random projection were developed, including random Fourier features [48] and random kitchen sinks [49].
Sufficient Dimension Reduction $(S D R)$ is another family of probabilistic methods, whose first method was proposed in 1991 [39]. It is used for finding a transformation of data to a lower-dimensional space, which does not change the conditional of labels given data. Therefore, the subspace is sufficient for predicting labels from projected data onto the subspace. SDR was mainly proposed for high-dimensional regression, where the regression labels are used. Later, Kernel Dimensionality Reduction $(K D R)$ was proposed [18] as a method in the family of SDR for dimensionality reduction in machine learning.
Stochastic Neighbour Embedding (SNE) was proposed in 2003 [30] and took a probabilistic approach to dimensionality reduction. It attempted to preserve the probability of a point being a neighbour of others in the subspace. A problem with SNE was that it could not find an optimal subspace because it was not possible for it to preserve all the important information of high-dimensional data in the low-dimensional subspace. Therefore, t-SNE was proposed [41], which used another distribution with more capacity in the subspace. This allowed t-SNE to preserve a larger amount of information in the low-dimensional subspace. A recent successful probabilistic dimensionality reduction method is the Uniform Manifold Approximation and Projection (UMAP) [43], which is widely used for data visualization. Today, both t-SNE and UMAP are used for high-dimensional data visualization, especially in the visualization of extracted features in deep learning. They have also been widely used for visualizing high-dimensional genome data.
机器学习代写|流形学习代写manifold data learning代考|History of Neural Network-Based Dimensionality
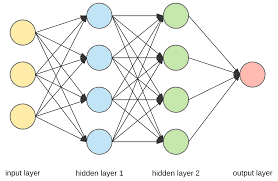
Neural networks are machine learning models modeled after the neural structure of the human brain. Neural networks are currently powerful tools for representation learning and dimensionality reduction. In the 1990s, researchers’ interest in neural networks decreased; this was called the winter of neural networks. This winter occurred mainly because networks could not become deep, as gradients vanished after many layers of network during optimization. The success of kernel support vector machines [10] also exaggerated this winter. In 2006, Hinton and Salakhutdinov demonstrated that a network’s weights can be initialized using energy-based training, where the layers of the network are considered stacks of Restricted Boltzmann Machines (RBM) [1,31]. RBM is a two-layer structure of neurons, whose weights between the two layers are trained using maximum likelihood estimation [68]. This initialization saved the neural network from the vanishing gradient problem and ended the neural networks’ winter. A deep network using RBM training was named the deep belief network [29]. Although, later, the proposal of the ReLU activation function [23] and the dropout technique [59] made it possible to train deep neural networks with random initial weights [24].
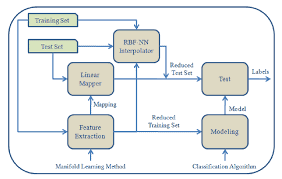
In fundamental machine learning, people often extract features using traditional dimensionality reduction and then apply the classification, regression, or clustering task afterwards. However, modern deep learning extracts features and learns embedding spaces in the layers of the network; this process is called end-to-end. Therefore, deep learning can be seen as performing a form of dimensionality reduction as part of its model. One problem with end-to-end models is that they are harder to troubleshoot if the performance is not satisfactory on a part of the data. The insights and meaning of the data coming from representation learning are critical to fully understand a model’s performance. Some of these insights can be useful for improving or understanding how deep neural networks operate. Researchers often visualize the extracted features of a neural network to interpret and analyze why deep learning is working properly on their data.
Deep metric learning [35] utilizes deep neural networks for extracting lowdimensional descriptive features from data at the last or one-to-last layer of the network. Siamese networks [11] are important network structures for deep metric learning. They contain several identical networks that share their weights, but have different inputs. Contrastive loss [27] and triplet loss [56] are two well-known loss functions that were proposed for training Siamese networks. Deep reconstruction autoencoders also make it possible to capture informative features at the bottleneck between the encoder and decoder.
流形学习代写
机器学习代写|流形学习代写manifold data learning代考|History of Probabilistic Dimensionality Reduction
许多谱降维方法的概率变体逐渐被开发和提出。例如,概率PCA[50,62]是 PCA 的随机版本,它假设数据是通过将噪声添加到潜在随机变量的线性投影中获得的。可以证明 PCA 是概率 PCA 的一个特例,其中噪声的方差趋于零。概率 PCA 本身是因子分析的一个特例 [17]。在因子分析中,噪声的不同维度可以相关,而在概率PCA中它们是不相关和等距的。因子分析和概率 PCA 对数据使用期望最大化和变分推理。
PCA 和 FDA 等线性光谱降维方法从数据中学习投影矩阵,以实现更好的数据表示或更好的类间分离。1984年,令人惊奇地确定,如果用一个随机矩阵来做数据的线性投影,不用从数据中学习,就可以很好地表示数据!Johnson-Lindenstrauss 引理 [33] 证明了这种随机投影之谜的正确性,该引理限制了子空间中距离保存的误差。后来,开发了随机投影的非线性变体,包括随机傅立叶特征 [48] 和随机厨房水槽 [49]。
足够的降维(小号丁R)是另一类概率方法,其第一个方法于 1991 年提出 [39]。它用于寻找数据到低维空间的转换,这不会改变给定数据的标签条件。因此,子空间足以预测来自投影数据到子空间的标签。SDR 主要是为高维回归提出的,其中使用了回归标签。后来,内核降维(钾丁R)被提议 [18] 作为 SDR 家族中的一种方法,用于机器学习中的降维。
随机邻域嵌入(SNE)于 2003 年提出 [30],并采用概率方法来降维。它试图保留一个点作为子空间中其他点的邻居的概率。SNE 的一个问题是它找不到最佳子空间,因为它不可能在低维子空间中保留高维数据的所有重要信息。因此,t-SNE被提出[41],它使用了另一种子空间容量更大的分布。这允许 t-SNE 在低维子空间中保留大量信息。最近成功的概率降维方法是均匀流形近似和投影(UMAP)[43],它被广泛用于数据可视化。今天,t-SNE和UMAP都用于高维数据可视化,特别是深度学习中提取特征的可视化。它们还被广泛用于可视化高维基因组数据。
机器学习代写|流形学习代写manifold data learning代考|History of Neural Network-Based Dimensionality
神经网络是模仿人脑神经结构的机器学习模型。神经网络目前是表示学习和降维的强大工具。20 世纪 90 年代,研究人员对神经网络的兴趣下降;这被称为神经网络的冬天。这个冬天的发生主要是因为网络无法变深,因为在优化过程中,梯度在多层网络之后消失了。内核支持向量机 [10] 的成功也在这个冬天被夸大了。2006 年,Hinton 和 Salakhutdinov 证明了可以使用基于能量的训练来初始化网络的权重,其中网络的层被视为受限玻尔兹曼机 (RBM) 的堆栈 [1,31]。RBM是神经元的两层结构,其两层之间的权重使用最大似然估计 [68] 进行训练。这种初始化将神经网络从梯度消失问题中解救出来,结束了神经网络的寒冬。使用 RBM 训练的深度网络被命名为深度信念网络 [29]。尽管后来,ReLU 激活函数 [23] 和 dropout 技术 [59] 的提出使训练具有随机初始权重的深度神经网络成为可能 [24]。
在基础机器学习中,人们通常使用传统的降维方法提取特征,然后再应用分类、回归或聚类任务。然而,现代深度学习提取特征并学习网络层中的嵌入空间;这个过程称为端到端。因此,深度学习可以被视为执行一种形式的降维,作为其模型的一部分。端到端模型的一个问题是,如果部分数据的性能不令人满意,则很难对其进行故障排除。来自表示学习的数据的见解和意义对于充分理解模型的性能至关重要。其中一些见解可能有助于改进或理解深度神经网络的运作方式。
深度度量学习 [35] 利用深度神经网络从网络最后一层或最后一层的数据中提取低维描述性特征。孪生网络 [11] 是深度度量学习的重要网络结构。它们包含几个共享权重但具有不同输入的相同网络。Contrastive loss [27] 和 triplet loss [56] 是两个众所周知的损失函数,它们被提议用于训练 Siamese 网络。深度重建自动编码器还可以在编码器和解码器之间的瓶颈处捕获信息特征。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。