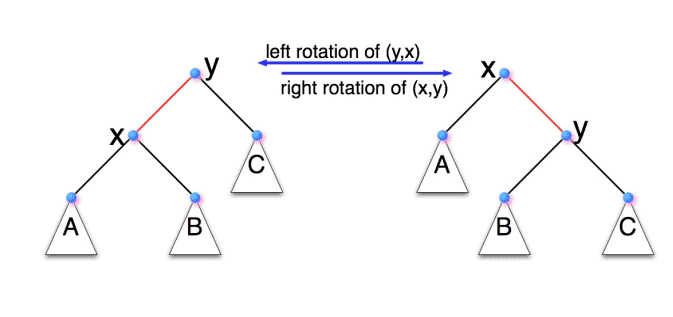
计算机代写|算法作业代写Algorithm代考|CS515
如果你也在 怎样代写算法Algorithm这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
statistics-lab™ 为您的留学生涯保驾护航 在代写算法Algorithm方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写算法Algorithm代写方面经验极为丰富,各种代写算法Algorithm相关的作业也就用不着说。
我们提供的算法Algorithm及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等楖率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
计算机代写|算法作业代写Algorithm代考|A Bad Example
As a prototypical example of a sequence of instructions that is not actually an algorithm, consider “Martin’s algorithm”: ${ }^{16}$ Pretty simple, except for that first step; it’s a doozy! A group of billionaire CEOs, Silicon Valley venture capitalists, or New York City real-estate hustlers might consider this an algorithm, because for them the first step is both unambiguous and trivial, ${ }^{17}$ but for the rest of us poor slobs, Martin’s procedure is too vague to be considered an actual algorithm. On the other hand, this is a perfect example of a reduction-it reduces the problem of being a millionaire and never paying taxes to the “easier” problem of acquiring a million dollars. We’ll see reductions over and over again in this book. As hundreds of businessmen and politicians have demonstrated, if you know how to solve the easier problem, a reduction tells you how to solve the harder one.
Martin’s algorithm, like some of our previous examples, is not the kind of algorithm that computer scientists are used to thinking about, because it is phrased in terms of operations that are difficult for computers to perform. This book focuses (almost!) exclusively on algorithms that can be reasonably implemented on a standard digital computer. Each step in these algorithms is either directly supported by common programming languages (such as arithmetic, assignments, loops, or recursion) or something that you’ve already learned how to do (like sorting, binary search, tree traversal, or singing ” $n$ Bottles of Beer on the Wall”).
计算机代写|算法作业代写Algorithm代考|Describing Algorithms
The skills required to effectively design and analyze algorithms are entangled with the skills required to effectively describe algorithms. At least in my classes, a complete description of any algorithm has four components:
- What: A precise specification of the problem that the algorithm solves.
- How: A precise description of the algorithm itself.
- Why: A proof that the algorithm solves the problem it is supposed to solve.
- How fast: An analysis of the running time of the algorithm.
It is not necessary (or even advisable) to develop these four components in this particular order. Problem specifications, algorithm descriptions, correctness proofs, and time analyses usually evolve simultaneously, with the development of each component informing the development of the others. For example, we may need to tweak the problem description to support a faster algorithm, or modify the algorithm to handle a tricky casc in the proof of correctncss. Nevertheless, presenting these components separately is usually clearest for the reader.
As with any writing, it’s important to aim your descriptions at the right audience; I recommend writing for a competent but skeptical programmer who is not as clever as you are. Think of yourself six months ago. As you develop any new algorithm, you will naturally build up lots of intuition about the problem and about how your algorithm solves it, and your informal reasoning will be guided by that intuition. But anyone reading your algorithm later, or the code you derive from it, won’t share your intuition or experience. Neither will your compiler. Neither will you six months from now. All they will have is your written description.
Even if you never have to explain your algorithms to anyone else, it’s still important to develop them with an audience in mind. Trying to communicate clearly forces you to think more clearly. In particular, writing for a novice audience, who will interpret your words exactly as written, forces you to work through fine details, no matter how “obvious” or “intuitive” your high-level ideas may seem at the moment. Similarly, writing for a skeptical audience forces you to develop robust arguments for correctness and efficiency, instead of trusting your intuition or your intelligence. ${ }^{18}$
I cannot emphasize this point enough: Your primary job as an algorithm designer is teaching other people how and why your algorithms work. If you can’t communicate your ideas to other human beings, they may as well not exist. Producing correct and efficient executable code is an important but secondary goal. Convincing yourself, your professors, your (prospective) employers, your colleagues, or your students that you are smart is at best a distant third.
算法代考
计算机代写|算法作业代写Algorithm代考|A Bad Example
作为实际上不是算法的指令序列的原型示例,请考虑“马丁算法”:16非常简单,除了第一步;真是太棒了!一群亿万富翁 CEO、硅谷风险资本家或纽约市的房地产骗子可能会认为这是一种算法,因为对他们来说,第一步既明确又微不足道,17但对于我们这些可怜的懒汉来说,马丁的程序太模糊了,不能被认为是一个实际的算法。另一方面,这是减少的一个完美例子——它将成为百万富翁和从不纳税的问题减少到获得一百万美元的“更容易”的问题。我们将在本书中一次又一次地看到减少。正如成百上千的商人和政治家所证明的那样,如果你知道如何解决更简单的问题,那么减少就会告诉你如何解决更难的问题。
Martin 的算法,就像我们之前的一些例子一样,不是计算机科学家习惯思考的那种算法,因为它是用计算机难以执行的操作来表述的。本书(几乎!)专注于可以在标准数字计算机上合理实现的算法。这些算法中的每一步要么由通用编程语言直接支持(例如算术、赋值、循环或递归),要么是您已经学会如何做的事情(例如排序、二分搜索、树遍历或唱歌)n墙上的啤酒瓶”)。
计算机代写|算法作业代写Algorithm代考|Describing Algorithms
有效设计和分析算法所需的技能与有效描述算法所需的技能纠缠在一起。至少在我的课程中,任何算法的完整描述都包含四个部分:
- 什么:算法解决的问题的精确说明。
- 如何:算法本身的精确描述。
- 为什么:算法解决了它应该解决的问题的证明。
- 多快:分析算法的运行时间。
没有必要(甚至不建议)按此特定顺序开发这四个组件。问题规范、算法描述、正确性证明和时间分析通常同时发展,每个组件的发展都会影响其他组件的发展。例如,我们可能需要调整问题描述以支持更快的算法,或者修改算法以处理 correctncss 证明中的棘手 casc。然而,单独呈现这些组件通常对读者来说是最清楚的。
与任何写作一样,将您的描述针对正确的受众很重要;我建议为一个不如你聪明但有能力但持怀疑态度的程序员写作。想想六个月前的你自己。当你开发任何新算法时,你自然会建立很多关于问题和你的算法如何解决它的直觉,你的非正式推理将受这种直觉的指导。但是以后阅读您的算法或您从中得出的代码的任何人都不会分享您的直觉或经验。你的编译器也不会。六个月后你也不会。他们所拥有的只是您的书面描述。
即使您永远不必向其他任何人解释您的算法,在开发它们时考虑到受众仍然很重要。试图清晰地沟通会迫使你更清晰地思考。特别是,为新手读者写作,他们会完全按照书面解释你的话,这会迫使你处理细节,无论你的高级想法目前看起来多么“明显”或“直觉”。同样,为持怀疑态度的观众写作会迫使您为正确性和效率提出强有力的论据,而不是相信您的直觉或智慧。18
我怎么强调这一点都不为过:作为算法设计者,你的主要工作是教别人你的算法如何工作以及为什么工作。如果您不能将您的想法传达给其他人,那么他们可能就不存在了。生成正确且高效的可执行代码是一个重要但次要的目标。让你自己、你的教授、你的(未来的)雇主、你的同事或你的学生相信你很聪明,充其量只是遥远的三分之一。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。