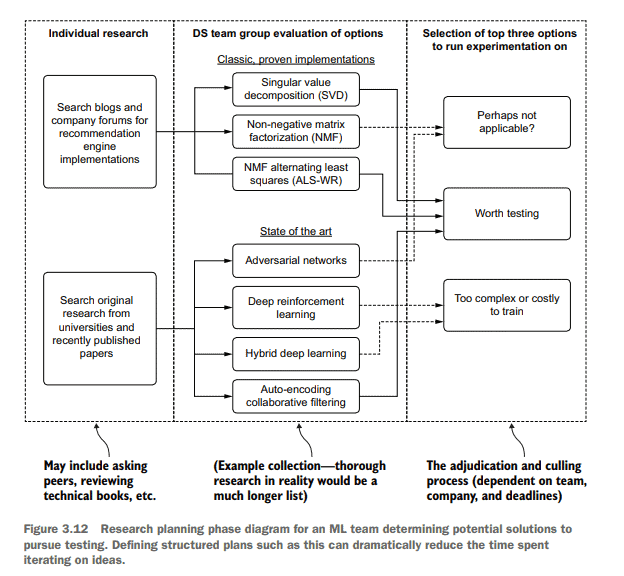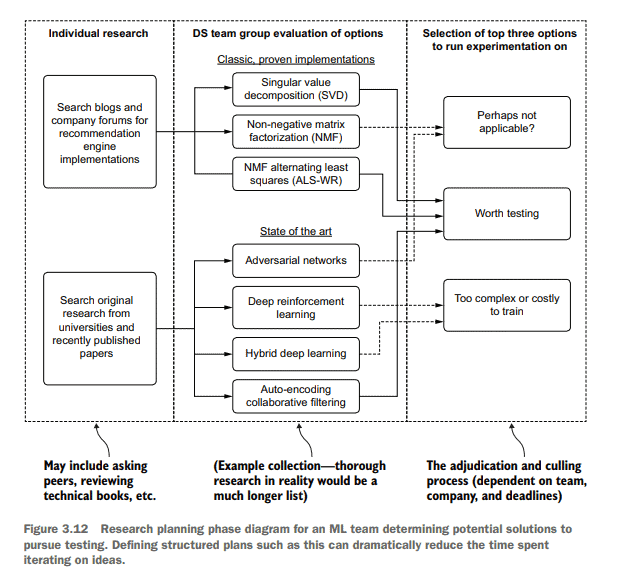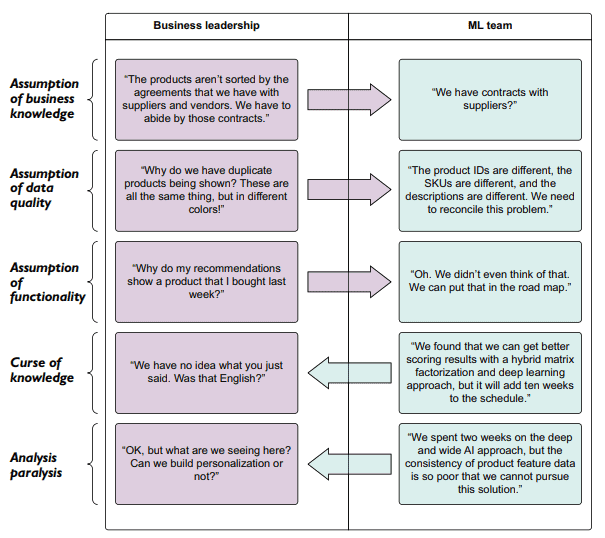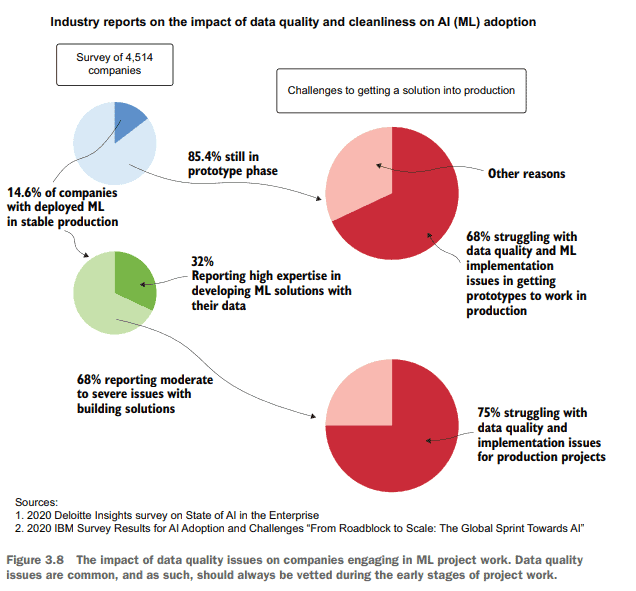
计算机代写|机器学习代写machine learning代考|Performing data analysis
如果你也在 怎样代写机器学习Machine Learning 这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。机器学习Machine Learning是一个致力于理解和建立 “学习 “方法的研究领域,也就是说,利用数据来提高某些任务的性能的方法。机器学习算法基于样本数据(称为训练数据)建立模型,以便在没有明确编程的情况下做出预测或决定。机器学习算法被广泛用于各种应用,如医学、电子邮件过滤、语音识别和计算机视觉,在这些应用中,开发传统算法来执行所需任务是困难的或不可行的。
机器学习Machine Learning程序可以在没有明确编程的情况下执行任务。它涉及到计算机从提供的数据中学习,从而执行某些任务。对于分配给计算机的简单任务,有可能通过编程算法告诉机器如何执行解决手头问题所需的所有步骤;就计算机而言,不需要学习。对于更高级的任务,由人类手动创建所需的算法可能是一个挑战。在实践中,帮助机器开发自己的算法,而不是让人类程序员指定每一个需要的步骤,可能会变得更加有效 。
statistics-lab™ 为您的留学生涯保驾护航 在代写机器学习 machine learning方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写机器学习 machine learning代写方面经验极为丰富,各种代写机器学习 machine learning相关的作业也就用不着说。
计算机代写|机器学习代写machine learning代考|Performing data analysis
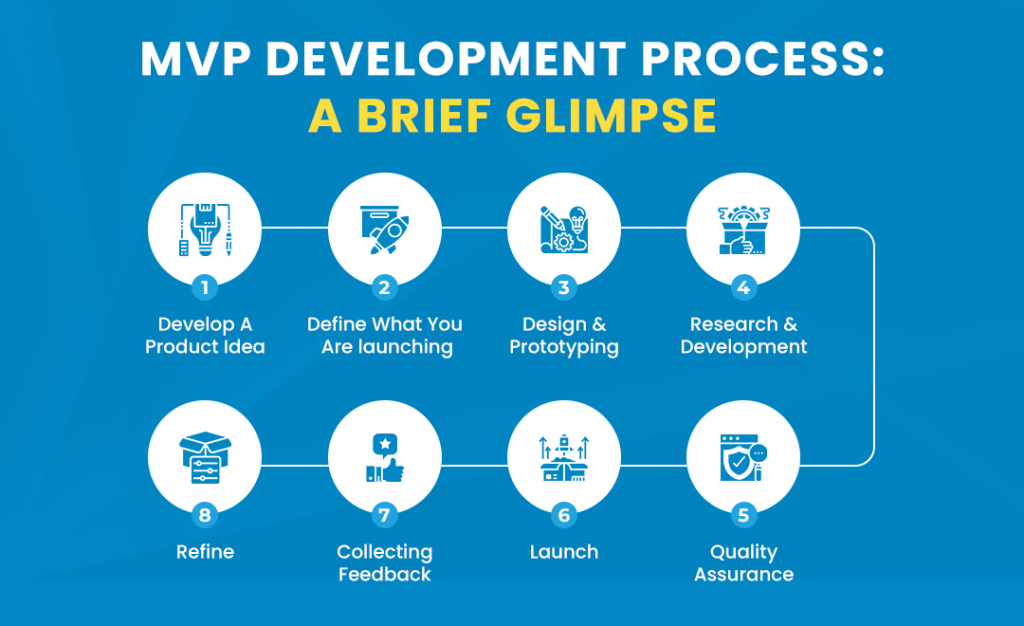
In the course of researching possible solutions, a lot of people seem to find trend visualizations pretty helpful. Not only does this activity prepare for baseline visualizations of the data to the broader business unit team that will be the consumers of the project solution, but it can help minimize unforeseen issues with the data that might be uncovered much later in the project; these issues could require a complete rework of the solution (and potentially a cancellation of the project if the rework is too expensive from a time and resources perspective). To marginalize the risk associated with finding out too late about a serious flaw in the data, we’re going to build a few analytics visualizations.
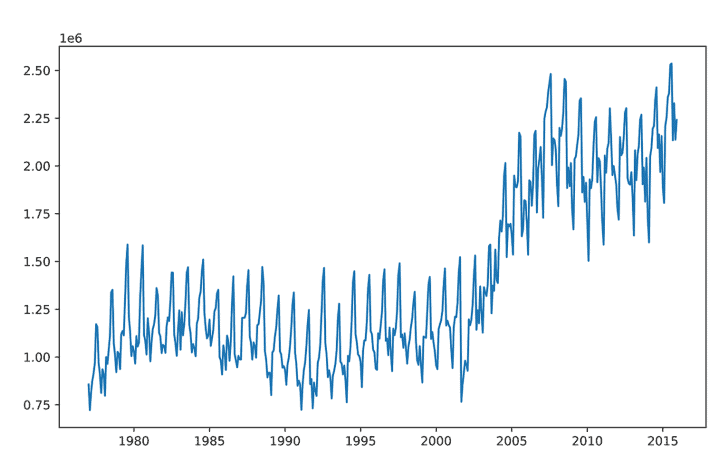
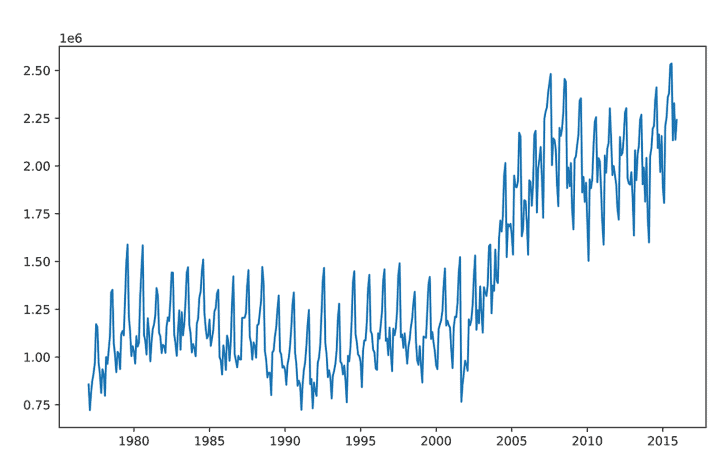
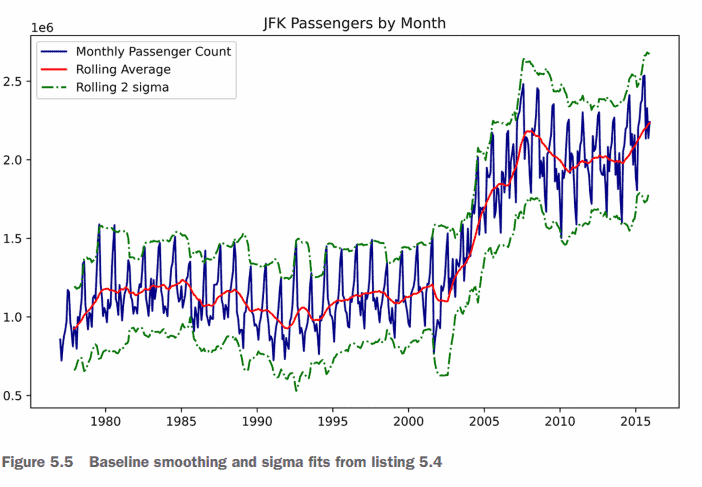
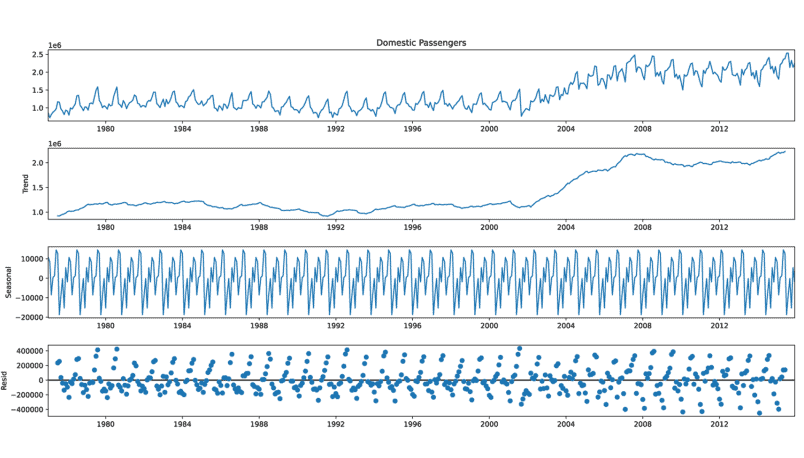
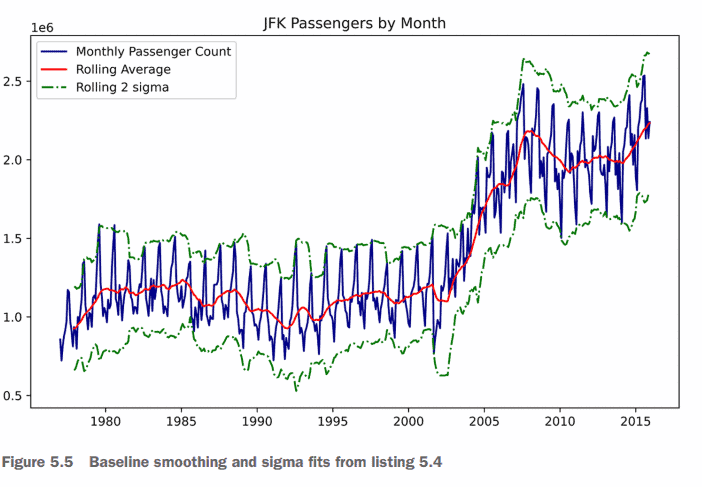
Based on the initial raw data visualization built in listing 5.1 (and shown in figure 5.3), we notice a great deal of noise in the dataset. Having a great deal of noise in a trend can certainly help visualize the general trend line, so let’s start by applying a smoothing function to the raw data trend for the domestic passengers at JFK. The script that we’re going to be executing is in the following listing, utilizing basic matplotlib visualizations.
Running this code in our Jupyter notebook will generate the plot shown in figure 5.5. Note how the general trend of the data looks when smoothed and realize that a definite step function occurs around 2002. Also note that the stddev varies widely during different time periods. After 2008, the variance becomes much broader than it had been historically.
The trend is OK, and somewhat useful for understanding the potential problems that might arise from building training and validation datasets that don’t reflect the trend change. (Specifically, we can see what might happen if we train up to the year 2000 and expect that a model will accurately predict from 2000 to 2015.)
During the research and planning phase, however, we found a great many mentions of stationarity in time series and how certain model types can really struggle with predicting a nonstationary trend. We should take a look at what that is all about.
For this, we’re going to use an augmented Dickey-Fuller stationarity test, provided in the statsmodels module. This test will inform us of whether we need to provide stationarity adjustments to the time series for particular models that are incapable of handling nonstationary data. If the test comes back with a value indicating that the time series is stationary, essentially all models can use the raw data with no transformations applied to it. However, if the data is nonstationary, extra work will be required. The script to run this test for the JFK domestic passengers series is shown next.
计算机代写|机器学习代写machine learning代考|HOW CLEAN IS OUR DATA?
Data cleanliness issues are one of the prime reasons for an MVP extending much longer than was promised to a business. Identifying bad data points is crucial not only for the purposes of modeling training effectiveness, but also to help tell a story to the business about why certain outputs of the model might be less than accurate at times. Building a series of visualizations that can communicate the complexities of latent factors, data-quality issues, and other unforeseen elements that can affect the solution can serve as a powerful tool during discussions with the project’s business unit.
One of the most important points that we’ll have to explain about the forecasting from this project is that it will not, and cannot, be an infallible system. Many unknowns remain in our dataset-elements of influence to the trend that are either too complex to track, too expensive to model, or nearly impossible to predict-that need to feed into the algorithm. For the case of univariate time-series models, nothing is going into the model other than the trending data itself. In the case of more complex implementations, such as windowed approaches and deep learning models like long short-term memory (LSTM) recurrent neural networks (RNNs), even though we can create vectors that contain much more information, we don’t always have the capability or the time to collate all of the features that could influence the trend.
To aid in having this conversation, we can take a look at a simple method of identifying outlier values that are dramatically different from what we would otherwise expect from a seasonally influenced trend. A relatively easy way to do this with series data is to use a differencing function on the sorted data. This can be accomplished as shown in the following listing.
机器学习代考
计算机代写|机器学习代写machine learning代考|Performing data analysis
在研究可能的解决方案的过程中,许多人似乎发现趋势可视化非常有用。此活动不仅为数据的基线可视化做好准备,更广泛的业务单元团队将成为项目解决方案的消费者,而且它可以帮助最小化可能在项目后期发现的数据不可预见的问题;这些问题可能需要对解决方案进行彻底的返工(如果从时间和资源的角度来看,返工过于昂贵,可能会取消项目)。为了排除因发现数据中严重缺陷太晚而带来的风险,我们将构建一些分析可视化。
基于清单5.1中内置的初始原始数据可视化(如图5.3所示),我们注意到数据集中存在大量噪声。在趋势中有大量的噪声当然可以帮助可视化总体趋势线,因此让我们首先对JFK国内乘客的原始数据趋势应用平滑函数。我们将要执行的脚本在下面的清单中,它利用了基本的matplotlib可视化。
在Jupyter笔记本中运行这段代码将生成如图5.5所示的图。注意数据平滑后的总体趋势,并意识到在2002年左右出现了一个明确的阶跃函数。还要注意,标准开发在不同的时间段变化很大。2008年之后,这种差异比历史上任何时候都要大得多。
这种趋势是可以的,并且在一定程度上有助于理解构建没有反映趋势变化的训练和验证数据集可能产生的潜在问题。(具体来说,如果我们训练到2000年,并期望一个模型能够准确预测2000年到2015年的情况,我们可以看到可能会发生什么。)
然而,在研究和规划阶段,我们发现大量提到时间序列的平稳性,以及某些模型类型如何真正难以预测非平稳趋势。我们应该看看这是怎么回事。
为此,我们将使用statmodels模块中提供的增强Dickey-Fuller平稳性检验。该测试将告知我们是否需要为无法处理非平稳数据的特定模型提供时间序列的平稳性调整。如果测试返回的值表明时间序列是平稳的,那么基本上所有模型都可以使用原始数据,而不需要对其进行转换。但是,如果数据是非平稳的,则需要额外的工作。下面显示为JFK国内乘客系列运行此测试的脚本。
计算机代写|机器学习代写machine learning代考|HOW CLEAN IS OUR DATA?
数据清洁度问题是MVP延长时间远远超过承诺的主要原因之一。识别错误的数据点是至关重要的,这不仅是为了对训练有效性进行建模,而且还有助于向业务人员说明为什么模型的某些输出有时可能不太准确。构建一系列可视化,可以传达潜在因素的复杂性、数据质量问题和其他可能影响解决方案的不可预见的元素,可以作为与项目业务单位讨论期间的强大工具。
关于这个项目的预测,我们必须解释的最重要的一点是,它不会,也不可能是一个绝对正确的系统。我们的数据中仍然存在许多未知因素——影响趋势的因素要么太复杂而无法追踪,要么太昂贵而无法建模,要么几乎不可能预测——这些因素需要输入到算法中。对于单变量时间序列模型,除了趋势数据本身之外,没有任何东西进入模型。在更复杂的实现中,例如窗口方法和长短期记忆(LSTM)递归神经网络(rnn)等深度学习模型,即使我们可以创建包含更多信息的向量,我们也并不总是有能力或时间来整理可能影响趋势的所有特征。
为了帮助进行这一讨论,我们可以看一看一种简单的方法来识别异常值,这些异常值与我们对季节性影响趋势的预期有很大不同。对于序列数据,一种相对简单的方法是对排序后的数据使用差分函数。这可以按照以下清单所示完成。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。