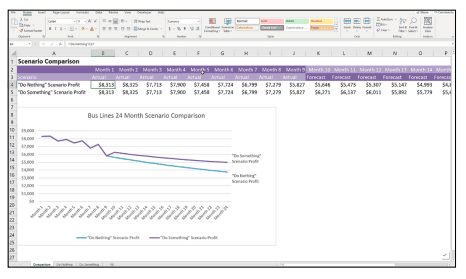
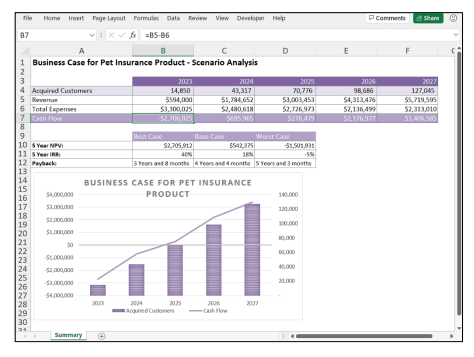
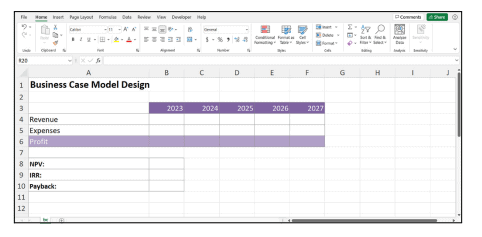
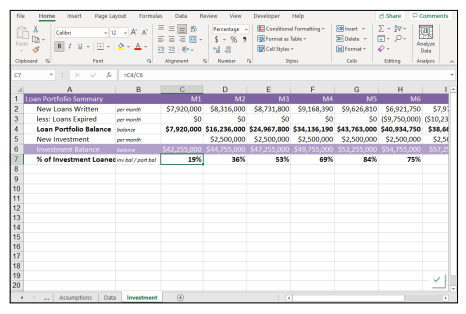
商科代写|商业建模代写Business Modeling代考|INFS6016
如果你也在 怎样代写商业建模Business Modeling这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
商业建模是一种风格化的模式,描述了公司如何创造并向客户提供价值,以及他们如何为此获得回报。
statistics-lab™ 为您的留学生涯保驾护航 在代写商业建模Business Modeling方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写商业建模Business Modeling代写方面经验极为丰富,各种代写商业建模Business Modeling相关的作业也就用不着说。
我们提供的商业建模Business Modeling及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
商科代写|商业建模代写Business Modeling代考|Process Flow
When we look at the work of Shigeo Shingo about improvement of production processes, he is not talking about processes as such, but rather at process delays. Essentially, he is discussing lossless transitions between (sub)processes and reduction of avoidable waste in transformation (sub)processes [6]. Any storage that is not required for stabilisation of the product is considered a process delay, and as such a loss to be avoided. However, when the period between order and delivery is shorter than the actual time it takes to manufacture a product, stocks are necessary. Therefore, reduction of process delay is key to Shingo’s thinking. Faster production throughput implies less need for stocks, and shifts production from push to pull.
Process improvement is fundamentally about time and timing. Underutilisation of production capacity is allowed when it reduces significantly throughput time. As an example, imagine a production company where the packaging is the bottleneck. The company has to find a balance between order lead time, customer service levels, idle time of expensive packaging equipment, and scrapped stock waiting for orders that did not materialise. Considerations of production cost would argue against investments in equipment, market considerations would argue against higher lead times. Taiichi Ohno writes “In production, ‘waste’ refers to all elements of production that only increase cost without adding value – for example, excess people, inventory, and equipment” [7]. The company will have to balance excess equipment against excess stocks. “Idle equipment” cannot always be equated to “excess equipment”.
To summarise, this kind of process thinking is primarily about pull, flow and avoidance of delays. This requires balancing on both the design level (production capacities) and the operational level (mechanisms for mutual adjustment/modification of production capacities). Processes can be recognised on different aggregation levels. They can be continuous or discrete. To realise flow through processes mechanisms must be in place that prevent unwanted intermediate stocks and unnecessary waiting between (sub)processes.
The relation of a business process to preceding and subsequent processes is another thing. The classic waterfall approach of IT projects is a prototypical example where each subsequent process is triggered by its preceding process and the chain of processes is carried out linearly, without going back to previous processes, until the end result. A second kind of process structure is linear with feedback, either directly feeding information back to a preceding process, or indirectly via some monitoring process. This process structure is found in conventional production companies. A third kind of process structure is with mutual adjustment between preceding and subsequent processes. Here a kind of reciprocity is to be found between preceding and subsequent processes, and this process structure is more likely to be found in production organisations that are based on the lean ideas.
商科代写|商业建模代写Business Modeling代考|Coping with Variability
In order to create constant outputs that are useful for customers or internal subsequent processes, business processes must be able to absorb variability. Irregularities in inputs or in the processing that are not absorbed will be passed on as irregularities in outputs.
Often, there will be a trade-off between extra costs caused by eliminating variability in the processes (creating extra consumption of resources. extra waste, and/or late delivery) and the extra costs of not fulfilling specifications and expectations for customers or for subsequent processes. Dealing with such trade-offs might be subject to coordination processes within the company or between the company and its customers.
In the design and execution of business processes there are different dimensions of variability, and different ways for coping with variability. One dimension is quality and deals with specifications and tolerances. Elimination of output variability can be achieved by elimination of variability of input in combination with standardisation of processes (Mintzberg: standardisation of work) [8]. A second way of elimination of output variability is to allow variability of input and have processes in place that eliminate variability in the processes (Mintzberg: standardisation of output). The third option is to allow variability at the output of the process, and then the question is how much the customer or the next internal process can and will tolerate.
Another dimension of variability is quantity and timing. This dimension is about getting the right amount of output at the right time available out of the process, and this requires the right amounts of resources at the right time available for consumption in the process. Some variability will be absorbed in the process. Variability in quantity and time between processes must be resolved by mutual adjustments of the processes, or by rescheduling. Major readjustments will be made dependent on a broad range of competing values. Will a delivery be on time but incomplete, or late and complete? Will an internal process be on time but generate extra costs, or late without extra production costs? This kind of decision making might also depend on the creativity of experienced people. Sometimes people can find smart ways to lessen the negative effects of product or production variability, by balancing requirements and possibilities of efficiency, specifications, timing, and allowable tolerances. Decision making in this kind of adjustment processes requires that a broad range of experience and competence is represented, because (1) heterogeneous values must be weighed against each other and (2) detailed knowledge about processes is needed to evaluate what is really possible in the given situation. And, where the output for customers is affected, both the specific agreement with the customer and the general conventions are important factors in balancing obligations and costs.
商科代写|商业建模代写Business Modeling代考|Machine Metaphor
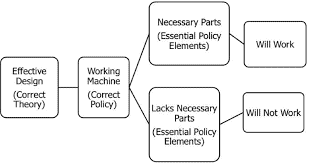
Gareth Morgan wrote about the mechanical view on organisations “When we talk about an organisation, we usually have in mind a state of orderly relations between clearly defined parts that have some determinate order. Although the image may not be explicit, we are talking about a set of mechanical relations. We talk about organisations as if they were machines, and as a consequence we tend to expect them to operate as machines: in a routinized, efficient, reliable, and predictable way” [9]. Peter Senge wrote about the machine metaphor something similar: “A machine exists for a purpose conceived of by its builders” and “To be effective, a machine must be controllable by its operators. This, of course, is the raison d’être of management – to control the enterprise” [10]. Such a view on organisations is reflected in the usage of the concept of enterprise engineering, which suggests that a company can be engineered like a machine. The Complete Business Process Handbook defines a business process “as a collection of tasks and activities (business operations and actions) consisting of employees, materials, machines, systems and methods that are being structured in such a way as to design, create, and deliver a product or service to the customer” [11] In the formal BPMN specification of the OMG a business process is defined as “A defined set of business activities that represent the steps required to achieve a business objective. It includes the flow and use of information and resources.” [12] These definitions match pretty good with the OED entry for a machine “An apparatus for applying mechanical power, consisting of a number of interrelated parts, each having a definite function” [1], apart from the application of mechanical power.
Of course, Morgan has offered not only the machine metaphor, but also the metaphors for the organisation as an organism, as a brain, as a culture, as political system, as psychic prison, as flux and transformation, and as domination. Each metaphor helps to see certain aspects of an organisation by comparing typical organisational features with features of the concept of the machine, organism, brain, et cetera. In this sense each metaphor is “true” in the sense that the organisation can be considered to have similar features as a machine. At the same time, the concepts brought together in the metaphor differ in many other respects. Morgan has described this paradox of the metaphor as the phenomenon that the statement “A is $\mathrm{B}$ ” can be both very useful and patently false at the same time. Taken metaphorically, the statement “the organisation is a machine” or “the organisation is an organism” can generate insights in the workings of an organisation as a consequence of the similarities between machine and organisation or between an organism and an organisation.
商业建模代考
商科代写|商业建模代写Business Modeling代考|Process Flow
当我们看到 Shigeo Shingo 关于改进生产流程的工作时,他不是在谈论流程本身,而是在谈论流程延迟。从本质上讲,他正在讨论(子)过程之间的无损转换以及减少转换(子)过程中可避免的浪费[6]。任何不需要稳定产品的储存都被视为过程延迟,因此应避免损失。但是,当订购和交货之间的时间比制造产品的实际时间短时,库存是必要的。因此,减少流程延迟是新乡思考的关键。更快的生产吞吐量意味着对库存的需求更少,并将生产从推动转向拉动。
流程改进基本上与时间和时机有关。当生产能力显着减少生产时间时,允许未充分利用生产能力。例如,想象一家生产公司,其中包装是瓶颈。公司必须在订单提前期、客户服务水平、昂贵包装设备的闲置时间和等待未实现订单的报废库存之间找到平衡。生产成本的考虑会反对设备投资,市场的考虑会反对更长的交货时间。Taiichi Ohno 写道:“在生产中,‘浪费’是指所有只会增加成本而不增加价值的生产要素——例如,过剩的人员、库存和设备”[7]。公司将不得不平衡过剩设备和过剩库存。
总而言之,这种流程思维主要是关于拉动、流动和避免延迟。这需要在设计层面(生产能力)和运营层面(相互调整/修改生产能力的机制)上进行平衡。可以在不同的聚合级别上识别流程。它们可以是连续的或离散的。为实现流程流程机制必须到位,以防止不必要的中间库存和(子)流程之间不必要的等待。
业务流程与前后流程的关系是另一回事。IT 项目的经典瀑布方法是一个原型示例,其中每个后续流程都由其前面的流程触发,并且流程链线性执行,无需回到先前的流程,直到最终结果。第二种流程结构与反馈是线性的,要么直接将信息反馈给前一个流程,要么通过一些监控流程间接反馈。这种工艺结构存在于传统的生产公司中。第三种工艺结构是前后工序相互调整。在这里,可以在前后过程之间找到一种互惠性,
商科代写|商业建模代写Business Modeling代考|Coping with Variability
为了创建对客户或内部后续流程有用的恒定输出,业务流程必须能够吸收可变性。未吸收的输入或处理中的不规则将作为输出的不规则传递。
通常,在消除流程可变性(造成额外的资源消耗、额外浪费和/或延迟交付)与未满足客户或后续规范和期望的额外成本之间需要权衡取舍。过程。处理此类权衡可能需要公司内部或公司与其客户之间的协调过程。
在业务流程的设计和执行中,存在不同维度的可变性,以及应对可变性的不同方法。一个维度是质量,涉及规格和公差。可以通过消除输入的可变性与流程标准化相结合来消除输出可变性(Mintzberg:工作标准化)[8]。消除输出可变性的第二种方法是允许输入可变性并建立消除过程可变性的过程(Mintzberg:输出标准化)。第三种选择是允许流程输出的可变性,然后问题是客户或下一个内部流程可以并且将容忍多少。
可变性的另一个维度是数量和时间。这个维度是关于在正确的时间从流程中获得正确数量的输出,这需要在正确的时间在流程中消耗正确数量的资源。在此过程中会吸收一些可变性。流程之间的数量和时间的差异必须通过流程的相互调整或重新安排来解决。将根据广泛的竞争价值观进行重大调整。交货会准时但不完整,还是迟到但完整?内部流程会按时完成但会产生额外成本,还是会延迟但不会产生额外的生产成本?这种决策也可能取决于有经验的人的创造力。有时,人们可以通过平衡效率、规格、时间和允许公差的要求和可能性,找到减少产品或生产可变性的负面影响的聪明方法。在这种调整过程中的决策需要代表广泛的经验和能力,因为(1)必须权衡不同的价值观,(2)需要有关过程的详细知识来评估什么是真正可能的给定的情况。而且,当客户的产出受到影响时,与客户的具体协议和一般约定都是平衡义务和成本的重要因素。在这种调整过程中的决策需要代表广泛的经验和能力,因为(1)必须权衡不同的价值观,(2)需要有关过程的详细知识来评估什么是真正可能的给定的情况。而且,当客户的产出受到影响时,与客户的具体协议和一般约定都是平衡义务和成本的重要因素。在这种调整过程中的决策需要代表广泛的经验和能力,因为(1)必须权衡不同的价值观,(2)需要有关过程的详细知识来评估什么是真正可能的给定的情况。而且,当客户的产出受到影响时,与客户的具体协议和一般约定都是平衡义务和成本的重要因素。
商科代写|商业建模代写Business Modeling代考|Machine Metaphor
加雷斯·摩根(Gareth Morgan)写过关于组织的机械观点“当我们谈论一个组织时,我们通常会想到具有某种确定顺序的明确定义的部分之间的有序关系状态。尽管图像可能不明确,但我们正在谈论一组机械关系。我们谈论组织时就好像它们是机器一样,因此我们倾向于期望它们像机器一样运行:以一种常规化、高效、可靠和可预测的方式”[9]。Peter Senge 写了类似的机器比喻:“一台机器的存在是为了它的建造者设想的目的”和“为了有效,一台机器必须由它的操作员控制。这当然是管理的存在理由——控制企业”[10]。这种对组织的看法反映在企业工程概念的使用上,这表明公司可以像机器一样被工程化。完整的业务流程手册将业务流程定义为“由员工、材料、机器、系统和方法组成的任务和活动(业务运营和行动)的集合,这些任务和活动的结构设计、创建和交付给客户的产品或服务”[11] 在 OMG 的正式 BPMN 规范中,业务流程被定义为“一组定义的业务活动,代表实现业务目标所需的步骤。它包括信息和资源的流动和使用。” [12] 这些定义与 OED 中关于机器的条目“一种用于施加机械动力的设备,
当然,摩根不仅提供了机器隐喻,还提供了组织作为有机体、大脑、文化、政治体系、心理监狱、流动和转变以及统治的隐喻。通过将典型的组织特征与机器、有机体、大脑等概念的特征进行比较,每个隐喻都有助于了解组织的某些方面。从这个意义上说,每个隐喻都是“真实的”,因为组织可以被认为具有与机器相似的特征。同时,隐喻中汇集的概念在许多其他方面也有所不同。摩根将这个隐喻的悖论描述为这样一种现象,即“A 是乙” 可以同时非常有用,但显然是错误的。打个比方,“组织是一台机器”或“组织是一个有机体”这句话可以产生对组织运作的洞察力,因为机器和组织之间或有机体和组织之间有相似之处。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。