统计代写|数据科学、大数据和数据多样性代写Data Science, Big Data and Data Variety代考|IS471
如果你也在 怎样代写数据科学、大数据和数据多样性Data Science, Big Data and Data Variety这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
数据科学是一个领域。大数据是一种收集、维护和处理巨大信息的技术。它是关于在各种操作中收集、处理、分析和利用数据。它更具有概念性。
statistics-lab™ 为您的留学生涯保驾护航 在代写数据科学、大数据和数据多样性Data Science, Big Data and Data Variety方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写数据科学、大数据和数据多样性Data Science, Big Data and Data Variety代写方面经验极为丰富,各种代写数据科学、大数据和数据多样性Data Science, Big Data and Data Variety相关的作业也就用不着说。
我们提供的数据科学、大数据和数据多样性Data Science, Big Data and Data Variety及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|数据科学、大数据和数据多样性代写Data Science, Big Data and Data Variety代考|Implications About Machine Learning Model Error
Although using MLMs has notable advantages for creating sampling designs, these methods are not without error. Misclassification errors result when MLMs fail to correctly classify units. In sample frame development, machine learning algorithms are applied to classify an image, land plot, or some other related unit as eligible for inclusion in the frame or ineligible. A false positive misclassification error results in a frame that might result in overcoverage of the actual population and lead to inefficiencies in survey data collection. A false negative misclassification error results in undercoverage and may lead to biased estimates if there is a systematic difference between population units correctly included on the frame and those excluded. To our knowledge, there is little work on the impact of this type of machine learning error on final survey estimates although Eck et al. (2019) discuss this as a future area of research. Moreover, there is even less understanding of how tuning parameter selection in these machine learning algorithms might be related to these potential survey errors and how one might incorporate this aspect of survey estimation into the classification algorithm.
By default, most machine learning algorithms optimize classifications to balance false positives with false negatives: however, one can use additional cost functions within these algorithms to penalize false positives at a higher rate than false negatives or vice versa. In frame development, one might argue that false negatives (leading to undercoverage) may be the more critical error. However, if there are no systematic differences on the survey outcome between correctly included and incorrectly excluded cases, then there might be more tolerance for this type of error. On the other hand, one could argue that if data collection costs are expensive (as in in-person or on-the-ground data collection or collection via expensive sensor equipment), then false positives might be the more critical error. If the false positive rate is high, for example then an eligibility screener may be necessary as an additional survey process step to ensure that only eligible population units be included in final analyses. In any case, it seems important to be able to quantify the impact of these errors before using MLMs for sampling frame development so that either the final results or choices of which of many MLMs lead to the best possible sample frame for use in the final sampling design can be assessed accordingly.
统计代写|数据科学、大数据和数据多样性代写Data Science, Big Data and Data Variety代考|Data Type Considerations and Implications About Data Errors
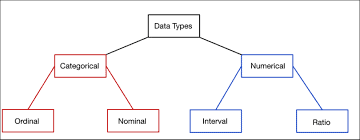
Most of the unsupervised MLMs create population groupings using a collection of continuous covariates. Cluster solutions are often sensitive to variable scaling so if the continuous variables have different scales, transforming the variables so they are all on the same scale is often recommended (Hastie, Tibshirani, and Friedman 2001). However, not all frame or auxiliary variables that are available for use in such segmentation are continuous. Scaling binary or nominal variables and treating them as continuous variables does not make much sense and could impact interpretability of results. Sampling designs seeking to leverage auxiliary information that is a mix of continuous, ordinal, and nominal variables may need to be modified by selecting a different proximity measure or using a method that allows for a mix of variable types such as hierarchical clustering with an appropriate distance measure. Boriah et al. (2008) compared 14 different similarity measures for categorical data for use with a $k$-nearest neighbors algorithm for outlier detection. Their experimental results suggest that there is no one best performing similarity measure, and the authors urge researchers to carefully consider how a particular similarity measure handles the different characteristics of the categorical variables in a given dataset prior to selecting the measure. Rather than focusing on different proximity measures for clustering data based on categorical variables, researchers have also explored using different statistics for creating the clusters including $k$-modes (Huang 1998) or fuzzy $k$-modes (Huang and Ng 1999; Kim, Lee, and Lee 2004). These methods use a single distance function appropriate for categorical variables. For datasets with categorical and continuous variables, Huang (1998) proposes a $k$-prototypes clustering algorithm based on a combination of two distance functions applied to categorical and continuous variables, respectively. When cases are to be clustered using only categorical variables or a mix of categorical and continuous variables, as often occurs in survey research applications, the results of the clustering will likely be more reproducible and interpretable and more likely to represent the underlying constructs, if any. within the collection of variables. Sampling designs seeking to give variables unequal influence on the creation of population segments may also benefit from using an additional weighting variable in the unsupervised MLM where the weights specify each variable’s relative influence on the overall segmentation.
Regardless of the type of data used in the machine learning algorithms, the impact of error within the variables themselves on the overall segmentation results is not well understood. Errors in the measurement of auxiliary, frame, or survey variables that are used in unsupervised machine learning algorithms to create population segments are of particular interest since we readily experience and quantify this type of error within the total survey error framework. Pankowska et al. (2018) explored the impact of survey measurement error on the correct classification of respondents into known groups using both GMMs as well as density-based spatial clustering of applications with noise (DBSCAN). Their simulation experiment varied the type of measurement error, the number of variables considered in the clustering that had error, the error rate, and the magnitude of the error. Pankowska and colleagues found that GMM is less sensitive to measurement errors compared to DBSCAN. Measurement error, regardless of method, has a very strong biasing effect for correctly recovering the true underlying grouping structure if the measurement error is systematic, rather than random, and all variables have high levels of measurement error.
数据科学、大数据和数据多样性代考
统计代写|数据科学、大数据和数据多样性代写Data Science, Big Data and Data Variety代考|Implications About Machine Learning Model Error
尽管使用 MLM 在创建抽样设计方面具有显着优势,但这些方法并非没有错误。当 MLM 未能正确分类单位时,会导致错误分类错误。在样本框架开发中,机器学习算法用于将图像、地块或其他一些相关单元分类为有资格包含在框架中或不符合条件。误报错误分类错误会导致可能导致对实际人口的过度覆盖并导致调查数据收集效率低下的框架。如果框架中正确包含的人口单位与排除的人口单位之间存在系统差异,则假阴性错误分类错误会导致覆盖不足,并可能导致估计有偏差。据我们所知,尽管 Eck 等人,关于这种类型的机器学习错误对最终调查估计的影响的研究很少。(2019)将此作为未来的研究领域进行讨论。此外,对于这些机器学习算法中的调整参数选择如何与这些潜在的调查错误相关,以及如何将调查估计的这一方面纳入分类算法的理解甚至更少。
默认情况下,大多数机器学习算法会优化分类以平衡假阳性和假阴性:但是,可以在这些算法中使用额外的成本函数来以比假阴性更高的速率惩罚假阳性,反之亦然。在框架开发中,有人可能会争辩说假阴性(导致覆盖不足)可能是更严重的错误。但是,如果正确包含和错误排除的案例之间的调查结果没有系统差异,那么对此类错误的容忍度可能会更高。另一方面,有人可能会争辩说,如果数据收集成本很高(例如在现场或现场数据收集或通过昂贵的传感器设备收集),那么误报可能是更严重的错误。如果误报率高,例如,作为额外的调查过程步骤,可能需要资格筛选器,以确保只有符合条件的人口单位被包括在最终分析中。在任何情况下,在使用 MLM 进行抽样框架开发之前,能够量化这些错误的影响似乎很重要,以便最终结果或许多 MLM 的选择导致用于最终抽样的最佳样本框架可以相应地评估设计。
统计代写|数据科学、大数据和数据多样性代写Data Science, Big Data and Data Variety代考|Data Type Considerations and Implications About Data Errors
大多数无监督 MLM 使用一组连续协变量来创建群体分组。聚类解决方案通常对变量尺度敏感,因此如果连续变量具有不同尺度,则通常建议转换变量以使它们都处于相同尺度(Hastie、Tibshirani 和 Friedman 2001)。然而,并非所有可用于此类分割的帧或辅助变量都是连续的。缩放二元或名义变量并将它们视为连续变量没有多大意义,并且可能会影响结果的可解释性。采样设计试图利用连续的、有序的、混合的辅助信息,可能需要通过选择不同的邻近度度量或使用允许混合变量类型的方法(例如具有适当距离度量的层次聚类)来修改名义变量。博里亚等人。(2008) 比较了分类数据的 14 种不同的相似性度量,以用于ķ- 用于异常值检测的最近邻算法。他们的实验结果表明,没有一种表现最好的相似性度量,作者敦促研究人员在选择度量之前仔细考虑特定的相似性度量如何处理给定数据集中分类变量的不同特征。研究人员并没有关注基于分类变量对数据进行聚类的不同邻近度度量,而是探索了使用不同的统计数据来创建聚类,包括ķ-modes (Huang 1998) or fuzzy ķ模式(Huang 和 Ng 1999;Kim、Lee 和 Lee 2004)。这些方法使用适用于分类变量的单个距离函数。对于具有分类变量和连续变量的数据集,Huang (1998) 提出了一个ķ-原型聚类算法基于分别应用于分类变量和连续变量的两个距离函数的组合。当仅使用分类变量或分类变量和连续变量的组合对案例进行聚类时(这在调查研究应用程序中经常发生),聚类结果可能更具有可重复性和可解释性,并且更有可能代表潜在的结构(如果有的话) . 在变量集合中。试图对创建人口细分的变量产生不同影响的抽样设计也可能受益于在无监督 MLM 中使用额外的加权变量,其中权重指定每个变量对整体细分的相对影响。
无论机器学习算法中使用的数据类型如何,变量本身的误差对整体分割结果的影响都不是很清楚。在无监督机器学习算法中用于创建人口细分的辅助、框架或调查变量的测量误差特别令人感兴趣,因为我们很容易在总调查误差框架内体验和量化这种类型的误差。Pankowska 等人。(2018 年)使用 GMM 和基于密度的噪声应用空间聚类(DBSCAN)探讨了调查测量误差对将受访者正确分类为已知组的影响。他们的模拟实验改变了测量误差的类型、聚类中考虑的有误差的变量数量、错误率、以及误差的大小。Pankowska 及其同事发现,与 DBSCAN 相比,GMM 对测量误差的敏感性较低。如果测量误差是系统的而不是随机的,并且所有变量都具有高水平的测量误差,那么无论采用何种方法,测量误差对于正确恢复真实的潜在分组结构具有非常强的偏差效应。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。
| R语言代写 | 问卷设计与分析代写 |
| PYTHON代写 | 回归分析与线性模型代写 |
| MATLAB代写 | 方差分析与试验设计代写 |
| STATA代写 | 机器学习/统计学习代写 |
| SPSS代写 | 计量经济学代写 |
| EVIEWS代写 | 时间序列分析代写 |
| EXCEL代写 | 深度学习代写 |
| SQL代写 | 各种数据建模与可视化代写 |
The graphs above are incomplete. These figures only show a vertex with degree four (vertex E), its nearest neighbors (A, B, C, and D), and segments of A-C Kempe chains. The entire graphs would also contain several other vertices (especially, more colored the same as B or D) and enough edges to be MPG’s. The left figure has A connected to $C$ in a single section of an A-C Kempe chain (meaning that the vertices of this chain are colored the same as A and C). The left figure shows that this A-C Kempe chain prevents B from connecting to $\mathrm{D}$ with a single section of a B-D Kempe chain. The middle figure has A and C in separate sections of A-C Kempe chains. In this case, B could connect to D with a single section of a B-D Kempe chain. However, since the A and C of the vertex with degree four lie on separate sections, the color of C’s chain can be reversed so that in the vertex with degree four, C is effectively recolored to match A’s color, as shown in the right figure. Similarly, D’s section could be reversed in the left figure so that D is effectively recolored to match B’s color.
Kempe also attempted to demonstrate that vertices with degree five are fourcolorable in his attempt to prove the four-color theorem [Ref. 2], but his argument for vertices with degree five was shown by Heawood in 1890 to be insufficient [Ref. 3]. Let’s explore what happens if we attempt to apply our reasoning for vertices with degree four to a vertex with degree five.
数学代写|图论作业代写Graph Theory代考|The previous diagrams
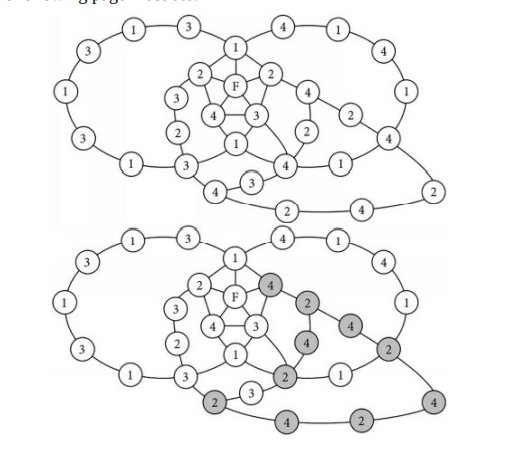
The previous diagrams show that when the two color reversals are performed one at a time in the crossed-chain graph, the first color reversal may break the other chain, allowing the second color reversal to affect the colors of one of F’s neighbors. When we performed the $2-4$ reversal to change B from 2 to 4 , this broke the 1-4 chain. When we then performed the 2-3 reversal to change E from 3, this caused C to change from 3 to 2 . As a result, F remains connected to four different colors; this wasn’t reversed to three as expected.
Unfortunately, you can’t perform both reversals “at the same time” for the following reason. Let’s attempt to perform both reversals “at the same time.” In this crossed-chain diagram, when we swap 2 and 4 on B’s side of the 1-3 chain, one of the 4’s in the 1-4 chain may change into a 2, and when we swap 2 and 3 on E’s side of the 1-4 chain, one of the 3’s in the 1-3 chain may change into a 2 . This is shown in the following figure: one 2 in each chain is shaded gray. Recall that these figures are incomplete; they focus on one vertex (F), its neighbors (A thru E), and Kempe chains. Other vertices and edges are not shown.
Note how one of the 3’s changed into 2 on the left. This can happen when we reverse $\mathrm{C}$ and $\mathrm{E}$ (which were originally 3 and 2 ) on E’s side of the 1-4 chain. Note also how one of the 4’s changed into 2 on the right. This can happen when we reverse B and D (which were originally 2 and 4) outside of the 1-3 chain. Now we see where a problem can occur when attempting to swap the colors of two chains at the same time. If these two 2’s happen to be connected by an edge like the dashed edge shown above, if we perform the double reversal at the same time, this causes two vertices of the same color to share an edge, which isn’t allowed. We’ll revisit Kempe’s strategy for coloring a vertex with degree five in Chapter $25 .$
图论代考
数学代写|图论作业代写Graph Theory代考|The shading of one section of the B-R
由于 Kempe 链的每个部分都与同一颜色对的其他部分隔离,因此 Kempe 链的任何部分的颜色可以颠倒,但仍满足四色定理。这是一个重要且有用的概念。
上面 BR 链的一个部分的阴影说明了任何 Kempe 链的任何部分的颜色如何可以反转。请注意,我们反转了 BR 链的一个部分的颜色,但没有反转中心部分的颜色。同一条链的每个部分的颜色可以独立于该链的其他部分反转。
为什么 PG 有 Kempe 链?很容易理解为什么 MPG 有 Kempe 链。(由于 PG 是通过从 MPG 中去除边缘而形成的,并且由于适用于 MPG 的着色也适用于 PG,因此 PG 也具有 Kempe 链。)
- MPG 是三角测量的。它由具有三个边和三个顶点的面组成。
- 每个面的三个顶点必须是三种不同的颜色。
- 每条边由两个相邻的三角形共享,形成一个四边形。
- 每个四边形将有 3 或 4 种不同的颜色。如果与共享边相对的两个顶点恰好是相同的颜色,则它有 3 种颜色。
- 对于每个四边形,四个顶点中的至少 1 个顶点和最多 3 个顶点具有任何颜色对的颜色。例如,具有 R、G、B 和G有 1 个顶点R−是和3个顶点乙−G,或者您可以将其视为 1 个顶点乙−是和3个顶点G−R,或者您可以将其视为 BR 的 2 个顶点和 GY 的 2 个顶点。在后一种情况下,2G’ 不是同一链的连续颜色。
- 当您将更多三角形组合在一起(四边形仅组合两个)并考虑可能的颜色时,您将看到 Kempe 的部分
链子出现。我们将在 Chápter 中看到这些 Kémpé chảins 是如何出现的21.
也很容易看出一对颜色(如 RY)将如何与其对应颜色(BG)相邻:
- 画一张R顶点和一个是由边连接的顶点。
- 如果一个新顶点连接到这些顶点中的每一个,它必须是乙或者G.
- 如果一个新顶点连接到 R 而不是是,可能是是,乙, 或者G.
- 如果一个新的顶点连接到是但不是R,可能是R,乙, 或者G.
- RY 链要么继续增长,要么被 B 包围,G.
- 如果你关注 B 和 G,你会为它的链条得出类似的结论。
- 如果一条链条完全被其对应物包围,则链条的新部分可能会出现在其对应物的另一侧。
Kempe 证明了所有具有四阶的顶点(那些恰好连接到其他四个顶点的顶点)都是四色的 [Ref. 2]。例如,考虑下面的中心顶点。
数学代写|图论作业代写Graph Theory代考|In the previous figure
在上图中,顶点和是四度,因为它连接到其他四个顶点。Kempe 表明顶点 A、B、C 和 D 不能被强制为四种不同的颜色,这样顶点 E 总是可以被着色而不会违反四色定理,无论 MPG 的其余部分看起来如何上一页显示的部分。
- A 和 C 或者是 AC Kempe 链的同一部分的一部分,或者它们各自位于 AC Kempe 链的不同部分。(如果一种和C例如,是红色和黄色的,则 AC 链是红黄色链。) – 如果一种和C每个位于 AC Kempe 链的不同部分,其中一个部分的颜色可以反转,这有效地重新着色 C 以匹配 A 的颜色。如果 A 和 C 是 AC Kempe 链的同一部分的一部分,则 B 和 D每个都必须位于 BD Kempe 链的不同部分,因为 AC Kempe 链将阻止任何 BD Kempe 链从 B 到达 D。(如果乙和D是蓝色和绿色,例如,那么一种BD Kempe 链是蓝绿色链。)在这种情况下,由于 B 和 D 分别位于 BD Kempe 链的不同部分,因此 BD Kempe 链的其中一个部分的颜色可以反转,这有效地重新着色 D 以匹配 B颜色。– 因此,可以使 C 与 A 具有相同的颜色或使 D 具有与 A 相同的颜色乙通过反转 Kempe 链的分离部分。
上面的图表是不完整的。这些图只显示了一个四阶顶点(顶点 E)、它的最近邻居(A、B、C 和 D),以及 AC Kempe 链的片段。整个图还将包含几个其他顶点(特别是与 B 或 D 相同的颜色)和足够多的边以成为 MPG。左图有 A 连接到C在 AC Kempe 链的单个部分中(意味着该链的顶点颜色与 A 和 C 相同)。左图显示此 AC Kempe 链阻止 B 连接到DBD Kempe 链条的一个部分。中间的数字在 AC Kempe 链的不同部分有 A 和 C。在这种情况下,B 可以通过 BD Kempe 链的单个部分连接到 D。但是,由于四阶顶点的 A 和 C 位于不同的部分,因此可以反转 C 链的颜色,以便在四阶顶点中,C 有效地重新着色以匹配 A 的颜色,如右图所示. 类似地,可以在左图中反转 D 的部分,以便有效地重新着色 D 以匹配 B 的颜色。
Kempe 还试图证明五阶顶点是可四色的,以证明四色定理 [Ref. 2],但 Heawood 在 1890 年证明他关于五次顶点的论点是不充分的 [Ref. 3]。让我们探讨一下如果我们尝试将我们对度数为四的顶点的推理应用于度数为五的顶点会发生什么。
数学代写|图论作业代写Graph Theory代考|The previous diagrams
前面的图表显示,当在交叉链图中一次执行两种颜色反转时,第一次颜色反转可能会破坏另一个链,从而允许第二次颜色反转影响 F 的一个邻居的颜色。当我们执行2−4反转将 B 从 2 更改为 4 ,这打破了 1-4 链。然后,当我们执行 2-3 反转以将 E 从 3 更改时,这导致 C 从 3 更改为 2 。结果,F 仍然连接到四种不同的颜色;这并没有像预期的那样反转为三个。
不幸的是,由于以下原因,您不能“同时”执行两个冲销。让我们尝试“同时”执行两个反转。在这个交叉链图中,当我们在 1-3 链的 B 侧交换 2 和 4 时,1-4 链中的一个 4 可能会变成 2,当我们在 E 侧交换 2 和 3 时1-4 链,1-3 链中的 3 之一可能会变为 2 。如下图所示:每条链中的一个 2 为灰色阴影。回想一下,这些数字是不完整的;他们专注于一个顶点 (F)、它的邻居 (A 到 E) 和 Kempe 链。其他顶点和边未显示。
请注意左侧的 3 之一如何变为 2。当我们反转时会发生这种情况C和和(最初是 3 和 2 )在 1-4 链的 E 侧。还要注意 4 个中的一个如何在右侧变为 2。当我们在 1-3 链之外反转 B 和 D(最初是 2 和 4)时,就会发生这种情况。现在我们看到了尝试同时交换两条链的颜色时会出现问题的地方。如果这两个 2 恰好通过上图虚线这样的边连接起来,如果我们同时进行双重反转,就会导致两个相同颜色的顶点共享一条边,这是不允许的。我们将在第 1 章重新讨论 Kempe 为五阶顶点着色的策略25.
统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。