统计代写|时间序列分析代写Time-Series Analysis代考|STAT4025
如果你也在 怎样代写时间序列分析Time-Series Analysis这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
时间序列分析是分析在一个时间间隔内收集的一系列数据点的具体方式。在时间序列分析中,分析人员在设定的时间段内以一致的时间间隔记录数据点,而不仅仅是间歇性或随机地记录数据点。
statistics-lab™ 为您的留学生涯保驾护航 在代写时间序列分析Time-Series Analysis方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写时间序列分析Time-Series Analysis代写方面经验极为丰富,各种代写时间序列分析Time-Series Analysis相关的作业也就用不着说。
我们提供的时间序列分析Time-Series Analysis及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|时间序列分析代写Time-Series Analysis代考|Quasi-Biennial Oscillation
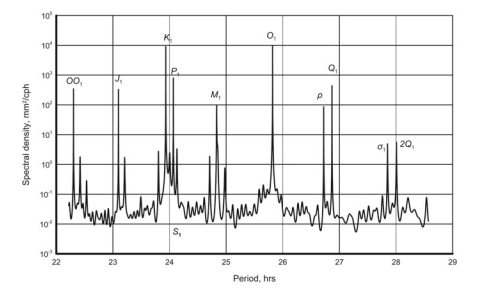
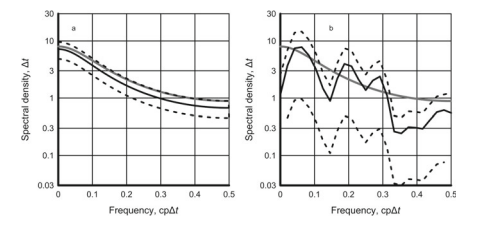
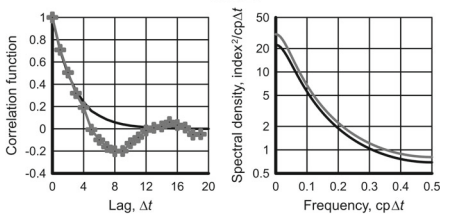
The Quasi-Biennial Oscillation will be discussed here at $\Delta t=1$ month. The time series used for this example is $\mathrm{QBO}$ at the atmospheric pressure level $20 \mathrm{hPa}$, which corresponds to the altitude of about $26 \mathrm{~km}$ above mean sea level (Fig. $6.5 \mathrm{a}$ and $# 2$ in Appendix). The spectral density estimate is shown in Fig. $6.5 \mathrm{~b}$ with the frequency axis given in a linear scale.
At the time when this text was being written, monthly observations of QBO were available from January 1953 through April of 2019 . The test extrapolation for the entire 2018 and the next six months of 2019, from May through November, which have been added in December 2019, is based upon the part of the time series that ends in December $2017(N=780)$.
The optimal, according to three of the five order selection criteria used here, is the AR model of order $p=10$ :
$$
x_{t}=\varphi_{1} x_{t-1}+\varphi_{2} x_{t-2}+\cdots+\varphi_{10} x_{t-10}+a_{t} .
$$
It means that the extrapolation equation is
$$
\hat{x}{t}(\tau)=\varphi{1} \hat{x}{t}(\tau-1)+\varphi{2} \hat{x}{t}(\tau-2)+\cdots+\varphi{10} \hat{x}{t}(\tau-10) $$ The white noise variance corresponding to the $\operatorname{AR}(10)$ model is $\sigma{a}^{2} \approx 21(\mathrm{~m} / \mathrm{s})^{2}$ while the total variance of wind speed at $20 \mathrm{hPa}$ is $\sigma_{x}^{2} \approx 389(\mathrm{~m} / \mathrm{s})^{2}$. Therefore, the predictability criterion $\rho(1) \approx 0.05$ and the correlation coefficient $(6.13)$ between the unknown true and predicted values of wind speed at lead time $\tau=1$ month is $0.97$. As seen from Fig. 6.6, the statistical predictability of $\mathrm{QBO}$ at the $20 \mathrm{hPa}$ level described with the predictability criteria $r_{e}(\tau)$ and $\rho(\tau)$ is quite high.
The results of prediction test with the initial time in December 2017 (Fig. 6.7a) show that the AR method of extrapolation is working quite well with this time series: 19 of the 20 monthly forecasts stay within the $90 \%$ confidence limits. More predictions are given from December 2018 through January 2021 for future verification (Fig. 6.7b). The data used for the AR models were from January 1953 through December 2017 and through December 2018 , respectively. By the time when the book was ready for the publisher, more observations became available and they are included into Fig. 6.7b. The quality of extrapolation seems to be high, but one should have in mind that the $90 \%$ confidence intervals shown in the figure are wide.
统计代写|时间序列分析代写Time-Series Analysis代考|ENSO Components
Predicting the behavior of the oceanic ENSO component-sea surface temperature in equatorial Pacific-is regarded as a very important task in climatology and oceanography (e.g., #3 and #4 in Appendix). Attempts to predict ENSO’s atmospheric component-the Southern Oscillation Index-do not seem to be numerous (e.g., Kepenne and Ghil 1992). In this section, both tasks will be treated within the KWT framework.
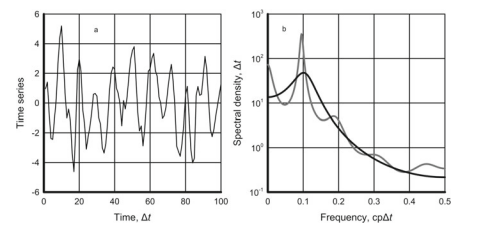
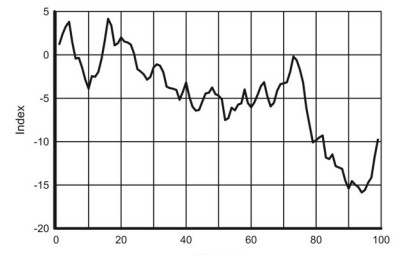
At the annual sampling rate, the ENSO components behave similar to white noise (Chap. 5); their predictions through any probabilistic method would be practically useless. In the current example, the statistical forecasts of sea surface temperature in the ENSO area NINO3 $\left(5^{\circ} \mathrm{N}-5^{\circ} \mathrm{S}, 150^{\circ} \mathrm{W}-90^{\circ} \mathrm{W}\right)$ and the Southern Oscillation Index are executed at a monthly sampling rate using the data from January 1854 through February 2019 and from 1876 through February 2019 , respectively. The data are available at websites #5 and #6 given in Appendix below. The NINO3 time series is shown in Fig. 6.8a. It can be treated as a sample of a stationary process.
The autoregressive analysis of this time series showed an AR(5) model as optimal. Its spectral density estimates are shown in Fig. $6.8 \mathrm{~b}$. The low-frequency part of the spectrum up to $0.5$ cpy contains about $70 \%$ of the NINO3 variance and the ratio of the white noise RMS to the NINO3 RMS is 0.39. In contrast to the annual global
temperature with the trend present, the predictability of NINO3 diminishes quite fast, but, as seen from Fig. 6.9, it still extends to several months.
A KWT prediction from the end of 2017 through January 2019 is given in Fig. $6.10 \mathrm{a}$. The result of the test turned out to be satisfactory but one has to remember that the $90 \%$ confidence limits for the extrapolated values are rather wide. Only the first four or five predicted values lie within the relatively narrow interval not exceeding $\pm \sigma_{x}$
统计代写|时间序列分析代写Time-Series Analysis代考|Madden-Julian Oscillation
This data set is taken from site #7 in Appendix below. As mentioned in Chap. 5 , the components of MJO regarded as samples of scalar processes may possess relatively high statistical predictability. At the unit lead time (one day), the statistical predictability criterion $\rho$ (1) for the RMM1 component equals to about $0.18$ and the process should be studied in more detail. The predictability of the RMM1 time series decreases rather fast (Fig. 6.12), but it stays acceptable up to 6 days. The RMM2 component behaves in the same way.
Prediction examples (Fig. 6.13) turned out to be rather successful even for longer lead times, but the confidence bounds are rather wide. The cycles with periods close to 50 days cannot be reliably reproduced by the extrapolation trajectory at lead times close to the period of the cycle.
If the sampling rate is increased from 1 day to 10 days, the resulting time series becomes poorly predictable even at the unit lead time, that is, at 10 days. As both the original time series RMM1 and RMM2 and the time series with $\Delta t=10$ days are Gaussian or close to Gaussian, one can say that the Madden-Julian Oscillation is practically unpredictable at that sampling rate in spite of the presence of a significant spectral maximum.
The examples in this chapter include five rather typical and at the same time dissimilar cases with the sampling rates of one year, one month, and one day; they can be summed up in the following way:
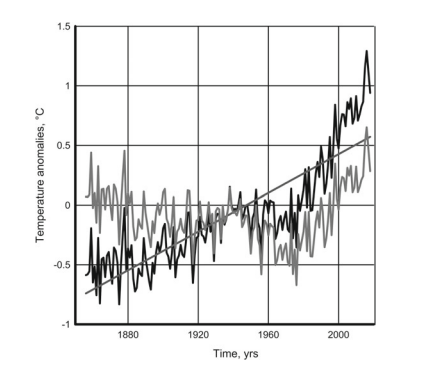
- the global surface temperature that has some predictability due to the dominant role of low-frequency variations even when the linear trend is deleted.
- highly predictable Quasi-Biennial Oscillation whose spectrum contains a powerful peak at the low-frequency part of the spectrum,
- SOI-the atmospheric component of ENSO-which contains a statistically significant spectral maximum and still has low predictability because of the low dynamic range of its spectrum.
- MJO, with its smooth spectral maximum and acceptable forecasts at several lead times.
In conclusion, it has been shown here that the use of a forecasting method which agrees with the Kolmogorov-Wiener theory of extrapolation produces satisfactory results if the spectrum of the time series is concentrated within a relatively narrow frequency band. If the spectrum is spread more or less evenly over frequency, the time series is practically unpredictable. In all cases, even when the latest and previously unknown values of the time series lie close to the predicted trajectory, one should keep in mind the width of the confidence interval as a function of lead time. It is the quantity that defines the usefulness of forecasts.
时间序列分析代考
统计代写|时间序列分析代写Time-Series Analysis代考|Quasi-Biennial Oscillation
准双年振荡将在此处讨论Δ吨=1月。此示例使用的时间序列是问乙○在大气压水平20H磷一个,这对应于大约的高度26 ķ米高于平均海平面(图6.5一个和# 2# 2在附录中)。谱密度估计如图 1 所示。6.5 b频率轴以线性比例给出。
在撰写本文时,可获取 1953 年 1 月至 2019 年 4 月期间的 QBO 月度观察结果。2019 年 12 月添加的整个 2018 年和 2019 年接下来六个月(从 5 月到 11 月)的测试推断基于 12 月结束的时间序列部分2017(ñ=780).
根据此处使用的五个订单选择标准中的三个,最优的是订单的 AR 模型p=10 :
X吨=披1X吨−1+披2X吨−2+⋯+披10X吨−10+一个吨.
这意味着外推方程是
X^吨(τ)=披1X^吨(τ−1)+披2X^吨(τ−2)+⋯+披10X^吨(τ−10)白噪声方差对应于和(10)模型是σ一个2≈21( 米/s)2而风速的总方差为20H磷一个是σX2≈389( 米/s)2. 因此,可预测性准则ρ(1)≈0.05和相关系数(6.13)在提前期风速的未知真实值和预测值之间τ=1月份是0.97. 从图 6.6 可以看出,问乙○在20H磷一个用可预测性标准描述的水平r和(τ)和ρ(τ)相当高。
初始时间在 2017 年 12 月的预测检验结果(图 6.7a)表明,外推的 AR 方法在这个时间序列上运行良好:20 个月度预测中有 19 个保持在90%置信限度。从 2018 年 12 月到 2021 年 1 月给出了更多预测,以供未来验证(图 6.7b)。用于 AR 模型的数据分别为 1953 年 1 月至 2017 年 12 月和 2018 年 12 月。当这本书准备好供出版商使用时,更多的观察结果变得可用,它们被包含在图 6.7b 中。外推的质量似乎很高,但应该记住,90%图中显示的置信区间很宽。
统计代写|时间序列分析代写Time-Series Analysis代考|ENSO Components
预测海洋ENSO 分量的行为——赤道太平洋的海表温度——被认为是气候学和海洋学中一项非常重要的任务(例如,附录中的#3 和#4)。预测ENSO 的大气成分——南方涛动指数——的尝试似乎并不多(例如,Kepenne 和Ghil 1992)。在本节中,这两个任务都将在 KWT 框架内处理。
在年采样率下,ENSO 分量的行为类似于白噪声(第 5 章);他们通过任何概率方法进行的预测实际上都是无用的。在本例中,ENSO 地区 NINO3 的海面温度统计预报(5∘ñ−5∘小号,150∘在−90∘在)和南方涛动指数分别使用 1854 年 1 月至 2019 年 2 月和 1876 年至 2019 年 2 月的数据以每月采样率执行。数据可在以下附录中给出的网站#5 和#6 上获得。NINO3 时间序列如图 6.8a 所示。它可以被视为一个平稳过程的样本。
该时间序列的自回归分析表明 AR(5) 模型是最优的。其谱密度估计如图 1 所示。6.8 b. 频谱的低频部分高达0.5cpy 包含大约70%NINO3 方差和白噪声 RMS 与 NINO3 RMS 之比为 0.39。与每年的全球
随着温度的变化趋势,NINO3 的可预测性下降得相当快,但从图 6.9 可以看出,它仍然延续到几个月。
从 2017 年底到 2019 年 1 月的 KWT 预测如图 1 所示。6.10一个. 测试结果证明是令人满意的,但人们必须记住,90%外推值的置信限相当宽。只有前四个或五个预测值位于相对狭窄的区间内,不超过±σX
统计代写|时间序列分析代写Time-Series Analysis代考|Madden-Julian Oscillation
该数据集取自以下附录中的站点 #7。如第 1 章所述。如图5所示,作为标量过程样本的MJO的分量可能具有较高的统计可预测性。在单位提前期(一天),统计可预测性标准ρ(1) 对于 RMM1 组件,大约等于0.18并且应该更详细地研究这个过程。RMM1 时间序列的可预测性下降得相当快(图 6.12),但在 6 天之内仍然可以接受。RMM2 组件的行为方式相同。
预测示例(图 6.13)即使在较长的交付周期内也相当成功,但置信区间相当宽。周期接近 50 天的周期不能通过接近周期周期的提前期的外推轨迹可靠地再现。
如果采样率从 1 天增加到 10 天,即使在单位提前期(即 10 天)时,所得到的时间序列也变得难以预测。作为原始时间序列 RMM1 和 RMM2 以及具有Δ吨=10天是高斯或接近高斯,可以说,尽管存在显着的光谱最大值,但在该采样率下,马登-朱利安振荡实际上是不可预测的。
本章的例子包括五个比较典型但又不同的案例,采样率分别为一年、一个月和一天;它们可以用以下方式总结:
- 由于低频变化的主导作用,即使在线性趋势被删除的情况下,全球地表温度也具有一定的可预测性。
- 高度可预测的准两年振荡,其频谱在频谱的低频部分包含一个强大的峰值,
- SOI——ENSO 的大气成分——包含一个统计上显着的光谱最大值,并且由于其光谱的低动态范围而仍然具有低的可预测性。
- MJO,具有平滑的光谱最大值和在几个前置时间可接受的预测。
总之,这里已经表明,如果时间序列的频谱集中在相对窄的频带内,使用符合 Kolmogorov-Wiener 外推理论的预测方法会产生令人满意的结果。如果频谱在频率上或多或少地分布均匀,则时间序列实际上是不可预测的。在所有情况下,即使时间序列的最新值和以前未知的值接近预测轨迹,也应牢记置信区间的宽度与前置时间的函数关系。它是定义预测有用性的数量。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。