统计代写|线性回归分析代写linear regression analysis代考|What model diagnostics should you do?
如果你也在 怎样代写线性回归分析linear regression analysis这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
回归分析是一种强大的统计方法,允许你检查两个或多个感兴趣的变量之间的关系。虽然有许多类型的回归分析,但它们的核心都是考察一个或多个自变量对因变量的影响。
statistics-lab™ 为您的留学生涯保驾护航 在代写线性回归分析linear regression analysis方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写线性回归分析linear regression analysis代写方面经验极为丰富,各种代写线性回归分析linear regression analysis相关的作业也就用不着说。
我们提供的线性回归分析linear regression analysis及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等楖率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|线性回归分析代写linear regression analysis代考|What model diagnostics should you do?
None! Well, most of the time, none. This is my view, and I might be wrong. Others (including your professor) may have valid reasons to disagree. But here is the argument why, in most cases, there is no need to perform any model diagnostics.
The two most common model diagnostics that are conducted are:
- checking for heteroskedasticity
- checking for non-normal error terms (Assumption A3 in Section 2.10).
One problem is that the tests are not great. The tests will indicate whether there is statisticallysignificant evidence for heteroskedasticity or non-normal error terms, but they certainly cannot prove that there is not any heteroskedasticity or non-normal error terms.
Regarding heteroskedasticity, your regression probably has heteroskedasticity. And, given that it is costless and painless to fix, you should probably include the heteroskedasticity correction.
Regarding non-normal error terms, recall that, due to the Central Limit Theorem, error terms will be approximately normal if the sample size is large enough (i.e., at least 200 observations at worst, and perhaps only 15 observations would suffice). However, this is not necessarily the case if: (1) the dependent variable is a dummy variable; and (2) there is not a large-enough set of explanatory variables. That said, a problem is that the test for non-normality (which tests for skewness and kurtosis) is highly unstable for small samples.
Having non-normal error terms means that the t-distribution would not apply to the standard errors, so the $t$-stats, standard levels of significance, confidence intervals, and $\mathrm{p}$-values would be a little off-target. The simple solution for cases in which there is the potential for non-normal errors is to require a lower $\mathrm{p}$-value than you otherwise would to conclude that there is a relationship between the explanatory and dependent variables.
I am not overly concerned by problems with non-normal errors because they are small potatoes when weighed against the Bayes critique of $\mathrm{p}$-values and the potential biases from PITFALLS (Chapter 6). If you have a valid study that is pretty convincing in terms of the PITFALLS being unlikely and having low-enough p-values in light of the Bayes critique, then having non-normal error terms would most likely not matter.
One potentially-useful diagnostic would be to check for outliers having large effects on the coefficient estimates. This would likely not be a concern with dependent variables that have a compact range of possible values, such as academic achievement test scores. But it could be the case with dependent variables on individual/family income or corporate profits/revenue, among other such outcomes with potentially large-outlying values of the dependent variable. Extreme values of explanatory variables could also be problematic. In these situations, it could be worth a diagnostic check of outliers for the dependent variable or the residuals. One could estimate the model without the big outliers to see how the results are affected. Of course, the outliers are supposedly legitimate observations, so any results without the outliers are not necessarily more correct. The ideal situation would be that the direction and magnitude of the estimates are consistent between the models with and without the outliers.
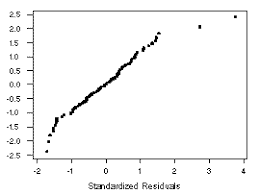
Outliers, if based on residuals, could be detected by residual plots. Alternatively, one potential rule that could be used for deleting outliers is based on calculating the standardized residual, which is the actual residual divided by the standard deviation of the residual-there is no need to subtract the mean of the residual since it is zero. The standardized residual indicates how many standard deviations away from zero a residual is. One could use an outlier rule, such as deleting observations with the absolute value of the standardized residual greater than some value, say, 5. With the adjusted sample, one would re-estimate a model to determine how stable the main results are.
统计代写|线性回归分析代写linear regression analysis代考|What the research on the hot hand in basketball tells us about
A friend of mine, drawn to the larger questions on life, called me recently and said that we are all alone – that humans are the only intelligent life in the universe. Rather than questioning him on the issue I have struggled with (whether humans, such as myself, should be categorized as “intelligent” life), I decided to focus on the main issue he raised and asked how he came to such a conclusion. Apparently, he had installed one of those contraptions in his backyard that searches for aliens. Honestly, he has so much junk in his backyard that I hadn’t even noticed. He said that he hadn’t received any signals in two years, so we must be alone.
While I have no idea whether we are alone in the universe, I know that my curious friend is not alone in his logic. A recent Wall Street Journal article made a similar logical conclusion in an article with some plausible arguments on why humans may indeed be alone in the universe. One of those arguments was based on the “deafening silence” from the 40-plus-year Search for Extraterrestrial Intelligence (SETI) project, with the conclusion that this is strong evidence that there is no other intelligent life (Metaxas, 2014). Never mind that SETI only searches our galaxy (of the estimated 170-plus billion galaxies in the universe) and that for us to find life on some planet, we have to be aiming our SETI at that planet (instead of the other 100 billion or so planets in our galaxy) at the same time (within the 13.6 billion years our galaxy has been in existence) that the alien geeks on that planet are emitting strong-enough radio signals in our direction (with a 600-plus-year lag for the radio signals to reach us). It may be that some form of aliens sent radio signals our way 2.8 billion years ago (before they went extinct after elininating their Environmental Protection Ageney), purposefully-striked-through and our amoeba-like ancestors had not yet developed the SETI technology to detect the signals.
The flawed logic here, as you have probably determined, is that lack of evidence is not proof of non-existence. This is particularly the case when you have a weak test for what you are looking for.
This logic flaw happens to be very common among academics. One line of research that has been subject to such faulty logic is that on the hot hand in basketball. The “hot hand” is a situation in which a player has a period (often within a single game) with a systematically higher probability of making shots (adjusting for the difficulty of the shot) than the player normally would have. The hot hand can occur in just about any other sport or activity, such as baseball, bowling, dance, test-taking, etc. In basketball, virtually all players and fans believe in the hot hand, based on witnessing players such as Stephen Curry go through stretches in which they make a series of high-difficulty shots. Yet, from 1985 to 2009 , plenty of researchers tested for the hot hand in basketball by using various tests to essentially determine whether a player was more likely to make a shot after a made shot (or consecutive made shots) than after a missed shot. They found no evidence of the hot hand. Their conclusion was “the hot hand is a myth.”
But then a few articles, starting in 2010, found evidence for the hot hand. And, as Stone (2012), Arkes (2013), and Miller and Sanjurjo (2018) show, the tests for the studies in the first 25 years were pretty weak tests for the hot hand because of some modeling problems, one of which I will describe in Box 6.4 in the next chapter.
The conclusions from those pre-2010 studies should not have been “the hot hand is a myth,” but rather “there is no evidence for the hot hand in basketball.” The lack of evidence was not proof of the non-existence of the hot hand. Using the same logic, in the search for aliens, the lack of evidence is not proof of non-existence, especially given that the tests have been weak. ${ }^5 \mathrm{I}$ ‘d bet my friend’s SETI machine that the other life forms out there, if they exist, would make proper conclusions on the basketball hot hand (and that they won’t contact us until we collectively get it right on the hot hand).
线性回归代写
统计代写|线性回归分析代写linear regression analysis代考|What model diagnostics should you do?
没有任何!好吧,大多数时候,没有。这是我的观点,我可能是错的。其他人(包括你的教授)可能有正当理由不同意。但这是为什么在大多数情况下不需要执行任何模型诊断的论点。
进行的两种最常见的模型诊断是:
- 检查异方差
- 检查非正态误差项(第 2.10 节中的假设 A3)。
一个问题是测试不是很好。检验将表明是否存在异方差或非正态误差项的统计显着证据,但它们当然不能证明不存在任何异方差或非正态误差项。
关于异方差性,您的回归可能具有异方差性。而且,鉴于修复起来既无成本又无痛,您可能应该包括异方差校正。
关于非正态误差项,回想一下,根据中心极限定理,如果样本量足够大(即最坏情况下至少有 200 个观测值,也许只有 15 个观测值就足够了),误差项将近似为正态。但是,如果出现以下情况则不一定如此: (1) 因变量是虚拟变量;(2) 没有足够大的解释变量集。也就是说,一个问题是非正态性测试(测试偏度和峰度)对于小样本来说非常不稳定。
具有非正态误差项意味着 t 分布不适用于标准误差,因此吨-统计、显着性标准水平、置信区间和p-values 会有点偏离目标。对于可能出现非正态错误的情况,简单的解决方案是要求较低的p-value 比你否则得出的结论是解释变量和因变量之间存在关系。
我并不过分担心非正态误差的问题,因为当与贝叶斯对p-来自 PITFALLS(第 6 章)的价值观和潜在偏见。如果您有一项有效的研究,就 PITFALLS 不太可能并且根据贝叶斯批判具有足够低的 p 值而言,该研究非常有说服力,那么具有非正态误差项很可能无关紧要。
一种可能有用的诊断方法是检查对系数估计值有很大影响的异常值。对于具有紧凑可能值范围的因变量(例如学业成绩测试分数),这可能不是一个问题。但是,个人/家庭收入或公司利润/收入的因变量可能就是这种情况,以及其他具有因变量的潜在大异常值的结果。解释变量的极值也可能有问题。在这些情况下,可能值得对因变量或残差的异常值进行诊断检查。人们可以在没有大异常值的情况下估计模型,看看结果是如何受到影响的。当然,离群值应该是合法的观察结果,所以没有异常值的任何结果都不一定更正确。理想情况是估计的方向和大小在有和没有异常值的模型之间是一致的。
如果基于残差,则可以通过残差图检测异常值。或者,可用于删除离群值的一个潜在规则是基于计算标准化残差,即实际残差除以残差的标准差——无需减去残差的均值,因为它为零。标准化残差表示残差与零的标准差有多少。可以使用异常值规则,例如删除标准化残差的绝对值大于某个值(例如 5)的观测值。使用调整后的样本,可以重新估计模型以确定主要结果的稳定性。
统计代写|线性回归分析代写linear regression analysis代考|What the research on the hot hand in basketball tells us about
我的一个朋友被生命中更大的问题所吸引,最近给我打电话说我们都是孤独的——人类是宇宙中唯一的智慧生命。我没有就我一直在纠结的问题(人类,比如我自己,是否应该被归类为“智能”生命)质疑他,而是决定专注于他提出的主要问题,并询问他是如何得出这样的结论的。显然,他在自家后院安装了其中一个搜索外星人的装置。老实说,他的后院有那么多垃圾,我什至都没注意到。他说他已经两年没有收到任何信号了,所以我们肯定是一个人。
虽然我不知道我们在宇宙中是否是孤独的,但我知道我好奇的朋友在他的逻辑上并不孤单。《华尔街日报》最近的一篇文章在一篇文章中得出了类似的逻辑结论,并就为什么人类在宇宙中确实可能是孤独的提出了一些似是而非的论据。其中一个论点是基于 40 多年的搜寻外星智能 (SETI) 项目的“震耳欲聋的沉默”,得出的结论是,这是不存在其他智慧生命的有力证据(Metaxas,2014 年)。不要介意 SETI 只搜索我们的星系(宇宙中估计有 170 多亿个星系),为了让我们在某个星球上找到生命,我们必须将 SETI 瞄准那个星球(而不是其他 1000 亿或所以我们银河系中的行星)同时(在 13. 我们的银河系已经存在了 60 亿年),那个星球上的外星极客正在向我们的方向发射足够强的无线电信号(无线电信号到达我们有 600 多年的滞后)。可能是某种形式的外星人在 28 亿年前(在他们取消环境保护署后灭绝之前)向我们发送了无线电信号,有目的地通过,而我们的变形虫类祖先尚未开发出 SETI 技术来检测信号。
正如您可能已经确定的那样,这里有缺陷的逻辑是缺乏证据并不能证明不存在。当您对要查找的内容进行弱测试时尤其如此。
这种逻辑缺陷恰好在学术界非常普遍。受制于这种错误逻辑的一项研究是关于篮球的热手。“热手”是这样一种情况,在这种情况下,一名球员有一段时间(通常在一场比赛中)比球员通常有更高的投篮概率(根据投篮难度进行调整)。热手几乎可以发生在任何其他运动或活动中,例如棒球、保龄球、舞蹈、应试等。在篮球运动中,几乎所有球员和球迷都相信热手,这是基于斯蒂芬库里等球员的见证经历他们进行一系列高难度投篮的阶段。然而,从 1985 年到 2009 年,许多研究人员通过各种测试来测试篮球中的热手,从根本上确定一名球员在投篮命中(或连续投篮命中)后是否比投丢后更有可能投篮。他们没有发现热手的证据。他们的结论是“热手是一个神话”。
但是从 2010 年开始的几篇文章找到了热手的证据。而且,正如 Stone(2012 年)、Arkes(2013 年)以及 Miller 和 Sanjurjo(2018 年)所表明的那样,由于某些建模问题,前 25 年的研究测试对热手的测试非常薄弱,其中之一是我将在下一章专栏 6.4 中描述。
那些 2010 年之前的研究得出的结论不应该是“热手是一个神话”,而是“篮球中没有热手的证据”。缺乏证据并不能证明热手不存在。使用相同的逻辑,在寻找外星人时,缺乏证据并不是不存在的证据,特别是考虑到测试一直很薄弱。5我我敢打赌我朋友的 SETI 机器,如果存在其他生命形式,他们会在篮球热手上做出正确的结论(并且他们不会联系我们,直到我们共同在热手上找到它)。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
随机过程代考
在概率论概念中,随机过程是随机变量的集合。 若一随机系统的样本点是随机函数,则称此函数为样本函数,这一随机系统全部样本函数的集合是一个随机过程。 实际应用中,样本函数的一般定义在时间域或者空间域。 随机过程的实例如股票和汇率的波动、语音信号、视频信号、体温的变化,随机运动如布朗运动、随机徘徊等等。
贝叶斯方法代考
贝叶斯统计概念及数据分析表示使用概率陈述回答有关未知参数的研究问题以及统计范式。后验分布包括关于参数的先验分布,和基于观测数据提供关于参数的信息似然模型。根据选择的先验分布和似然模型,后验分布可以解析或近似,例如,马尔科夫链蒙特卡罗 (MCMC) 方法之一。贝叶斯统计概念及数据分析使用后验分布来形成模型参数的各种摘要,包括点估计,如后验平均值、中位数、百分位数和称为可信区间的区间估计。此外,所有关于模型参数的统计检验都可以表示为基于估计后验分布的概率报表。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
statistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
机器学习代写
随着AI的大潮到来,Machine Learning逐渐成为一个新的学习热点。同时与传统CS相比,Machine Learning在其他领域也有着广泛的应用,因此这门学科成为不仅折磨CS专业同学的“小恶魔”,也是折磨生物、化学、统计等其他学科留学生的“大魔王”。学习Machine learning的一大绊脚石在于使用语言众多,跨学科范围广,所以学习起来尤其困难。但是不管你在学习Machine Learning时遇到任何难题,StudyGate专业导师团队都能为你轻松解决。
多元统计分析代考
基础数据: $N$ 个样本, $P$ 个变量数的单样本,组成的横列的数据表
变量定性: 分类和顺序;变量定量:数值
数学公式的角度分为: 因变量与自变量
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。