统计代写|回归分析作业代写Regression Analysis代考|STAT311
如果你也在 怎样代写回归分析Regression Analysis 这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。回归分析Regression Analysis是一种显示两个或多个变量之间关系的统计方法。通常用图表表示,该方法检验因变量与自变量之间的关系。通常,自变量随因变量而变化,回归分析试图回答哪些因素对这种变化最重要。
回归分析Regression Analysis中的预测可以涵盖各种各样的情况和场景。例如,预测有多少人会看到广告牌可以帮助管理层决定投资广告是否是个好主意;在哪种情况下,这个广告牌能提供良好的投资回报?保险公司和银行大量使用回归分析的预测。有多少抵押贷款持有人会按时偿还贷款?有多少投保人会遭遇车祸或家中被盗?这些预测允许进行风险评估,但也可以预测最佳费用和溢价。
statistics-lab™ 为您的留学生涯保驾护航 在代写回归分析Regression Analysis方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写回归分析Regression Analysis代写方面经验极为丰富,各种代写回归分析Regression Analysis相关的作业也就用不着说。
统计代写|回归分析作业代写Regression Analysis代考|The Independence Assumption and Repeated Measurements
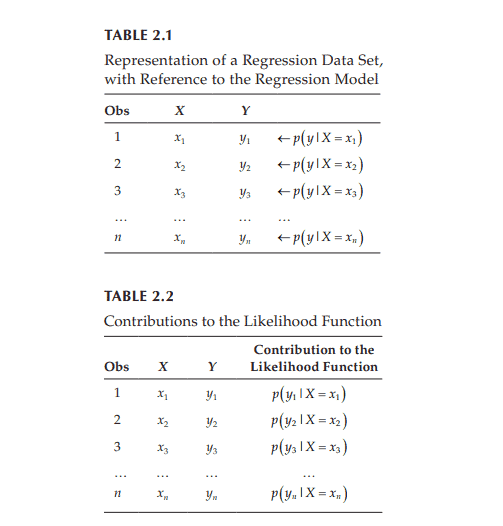
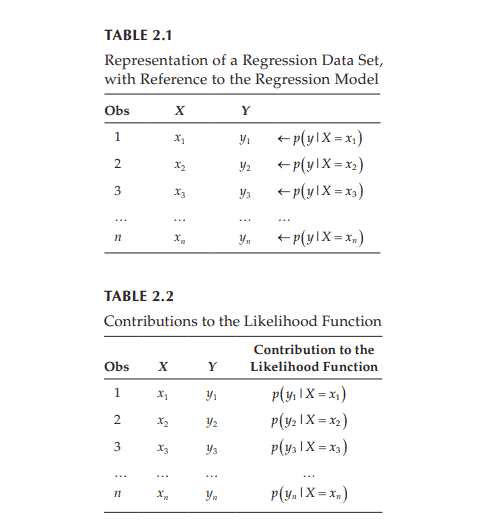
You know what? All the analyses we did on the charitable contributions prior to the subject/indicator variable model were grossly in error because the independence assumption was so badly violated. You may assume, nearly without question, that these 47 taxpayers are independent of one another. But you may not assume that the repeated observations on a given taxpayer are independent. Charitable behavior in different years is similar for given taxpayers; i.e., the observations are dependent rather than independent. It was wrong for us to assume that there were 470 independent observations in the data set. As you recall, the standard error formula has an ” $n$ ” in the denominator, so it makes a big difference whether you use $n=470$ or $n=47$. In particular, all the standard errors for models prior to the analysis above were too small.
Sorry about that! We would have warned you that all those analyses were questionable earlier, but there were other points that we needed to make. Those were all valid points for cases where the observations are independent, so please do not forget what you learned.
But now that you know, please realize that you must consider the dependence issue carefully. You simply cannot, and must not, treat repeated observations as independent. All of the standard errors will be grossly incorrect when you assume independence; the easiest way to understand the issue is to recognize that $n=470$ is quite a bit different from $n=47$.
Confused? Simulation to the rescue! The following R code simulates and analyzes data where there are 3 subjects, with 100 replications on each, and with a strong correlation (similarity) of the data on each subject.
$$
\begin{aligned}
& \mathrm{s}=3 \quad # \text { subjects } \
& r=100 \quad # \text { replications within subject } \
& \mathrm{X}=\operatorname{rnorm}(\mathrm{s}) ; \mathrm{X}=\operatorname{rep}(\mathrm{X}, \text { each }=r) \text { +rnorm }\left(r^{\star} s, 0, .001\right) \
& \mathrm{a}=\operatorname{rnorm}(\mathrm{s}) ; \mathrm{a}=\operatorname{rep}(\mathrm{a}, \text { each }=r)
\end{aligned}
$$
$e=\operatorname{rnorm}(s \star r, 0, .001)$
epsilon $=\mathrm{a}+\mathrm{e}$
$\mathrm{Y}=0+0 \star \mathrm{X}+\operatorname{rnorm}\left(\mathrm{S}^* \mathrm{r}\right)$ tepsilon # $\mathrm{Y}$ unrelated to $\mathrm{X}$
sub $=\operatorname{rep}(1: s$, each $=r)$
summary $(\operatorname{lm}(\mathrm{Y} \sim \mathrm{X}))$ # Highly significant $\mathrm{X}$ effect
$\operatorname{summary}(\operatorname{lm}(\mathrm{Y} \sim \mathrm{X}+$ as.factor $($ sub $)))$ # Insignificant $\mathrm{X}$ effect
统计代写|回归分析作业代写Regression Analysis代考|Predicting Hans’ Graduate GPA: Theory Versus Practice
Hans is applying for graduate school at Calisota Tech University (CTU). He sends CTU his quantitative score on the GRE entrance examination $\left(X_1=140\right)$, his verbal score on the $\operatorname{GRE}\left(X_2=160\right)$, and his undergraduate GPA $\left(X_3=2.7\right)$. What would be his final graduate GPA at CTU?
Of course, no one can say. But what we do know, from the Law of Total Variance discussed in Chapter 6, is that the variance of the conditional distribution of $Y=$ final CTU GPA is smaller on average when you consider additional variables. Specifically,
$$
\mathrm{E}\left{\operatorname{Var}\left(Y \mid X_1, X_2, X_3\right)\right} \leq \mathrm{E}\left{\operatorname{Var}\left(Y \mid X_1, X_2\right)\right} \leq \mathrm{E}\left{\operatorname{Var}\left(Y \mid X_1\right)\right}
$$
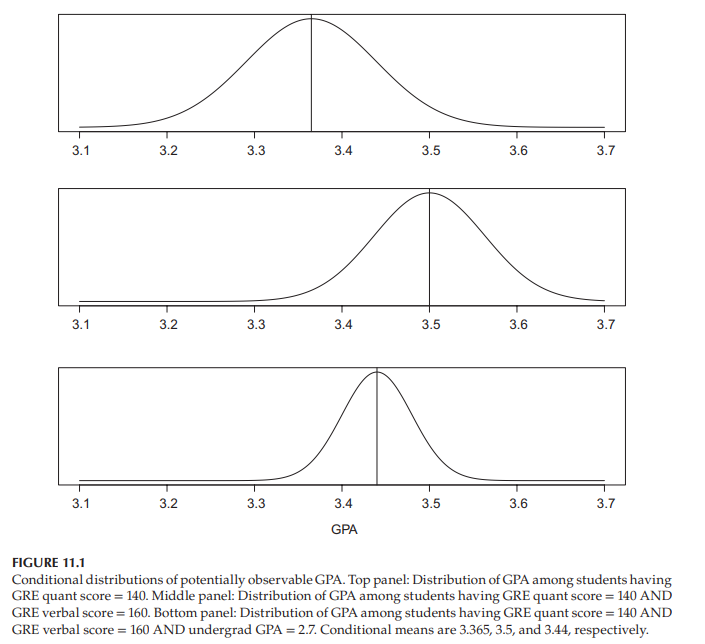
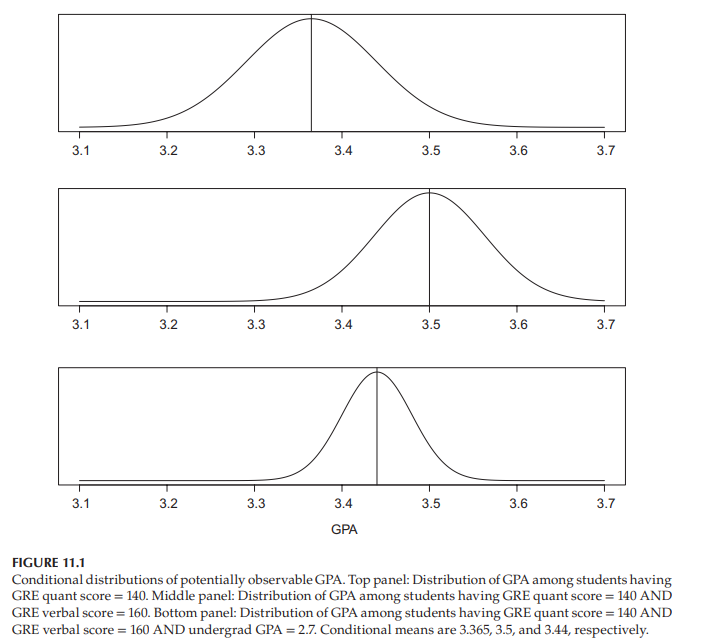
Figure 11.1 shows how these inequalities might appear, as they relate to Hans. The variation in potentially observable GPAs among students who are like Hans in that they have GRE Math $=140$ is shown in the top panel. Some of that variation is explained by different verbal abilities among students, and the second panel removes that source of variation by considering GPA variation among students who, like Hans, have GRE Math $=140$, and GRE Verbal $=160$. But some of that variation is explained by the general student diligence. Assuming undergraduate GPA is a reasonable measure of such “diligence,” the final panel removes that source of variation by considering GPA variation among students who, like Hans, have GRE Math $=140$, and GRE verbal $=160$, and undergrad GPA $=2.7$. Of course, this can go on and on if additional variables were available, with each additional variable removing a source of variation, leading to distributions with smaller and smaller variances.
The means of the distributions shown in Figure 11.1 are $3.365,3.5$, and 3.44 , respectively. If you were to use one of the distributions to predict Hans, which one would you pick? Clearly, you should pick the one with the smallest variance. His ultimate GPA will be the same number under all three distributions, and since the third distribution has the smallest variance, his GPA will likely be closer to its mean (3.44) than to the other distribution means (3.365 or 3.5).
回归分析代写
统计代写|回归分析作业代写Regression Analysis代考|The Independence Assumption and Repeated Measurements
你知道吗?在主体/指标变量模型之前,我们对慈善捐款所做的所有分析都是严重错误的,因为独立性假设被严重违反了。你可以毫无疑问地假设,这47个纳税人是相互独立的。但你可能不会认为,对某一特定纳税人的反复观察是独立的。同一纳税人不同年度的慈善行为相似;也就是说,观测结果是依赖的,而不是独立的。假设数据集中有470个独立的观测值是错误的。正如您所记得的,标准误差公式的分母中有一个“$n$”,因此使用$n=470$还是$n=47$有很大的不同。特别是,在上述分析之前,所有模型的标准误差都太小。
很抱歉!我们早就警告过你们,所有这些分析都是有问题的,但我们还需要说明其他几点。这些都是有效点在观察是独立的情况下,所以请不要忘记你学过的东西。
但是现在您知道了,请意识到您必须仔细考虑依赖性问题。你不能,也不应该,把重复的观察看作是独立的。当你假设独立时所有的标准误差都是非常不正确的;理解这个问题的最简单方法是认识到$n=470$与$n=47$有很大的不同。
困惑了吗?模拟救援!下面的R代码模拟和分析了有3个受试者的数据,每个受试者有100个重复,并且每个受试者的数据具有很强的相关性(相似性)。
$$
\begin{aligned}
& \mathrm{s}=3 \quad # \text { subjects } \
& r=100 \quad # \text { replications within subject } \
& \mathrm{X}=\operatorname{rnorm}(\mathrm{s}) ; \mathrm{X}=\operatorname{rep}(\mathrm{X}, \text { each }=r) \text { +rnorm }\left(r^{\star} s, 0, .001\right) \
& \mathrm{a}=\operatorname{rnorm}(\mathrm{s}) ; \mathrm{a}=\operatorname{rep}(\mathrm{a}, \text { each }=r)
\end{aligned}
$$
$e=\operatorname{rnorm}(s \star r, 0, .001)$
$=\mathrm{a}+\mathrm{e}$
$\mathrm{Y}=0+0 \star \mathrm{X}+\operatorname{rnorm}\left(\mathrm{S}^* \mathrm{r}\right)$ tempsilon # $\mathrm{Y}$与$\mathrm{X}$无关
子$=\operatorname{rep}(1: s$,每个$=r)$
总结$(\operatorname{lm}(\mathrm{Y} \sim \mathrm{X}))$ #高度显著$\mathrm{X}$效应
$\operatorname{summary}(\operatorname{lm}(\mathrm{Y} \sim \mathrm{X}+$ as。因子$($ sub $)))$ #不显著$\mathrm{X}$效应
统计代写|回归分析作业代写Regression Analysis代考|Predicting Hans’ Graduate GPA: Theory Versus Practice
汉斯正在申请加州理工大学(CTU)的研究生院。他把GRE入学考试的定量成绩$\left(X_1=140\right)$、口头成绩$\operatorname{GRE}\left(X_2=160\right)$和本科GPA $\left(X_3=2.7\right)$发给CTU。他在CTU毕业时的平均绩点是多少?
当然,谁也说不准。但是我们确实知道,从第6章讨论的总方差定律,当你考虑额外的变量时,$Y=$最终CTU GPA的条件分布的方差平均较小。具体来说,
$$
\mathrm{E}\left{\operatorname{Var}\left(Y \mid X_1, X_2, X_3\right)\right} \leq \mathrm{E}\left{\operatorname{Var}\left(Y \mid X_1, X_2\right)\right} \leq \mathrm{E}\left{\operatorname{Var}\left(Y \mid X_1\right)\right}
$$
图11.1显示了这些不平等在与Hans相关时可能出现的情况。像汉斯一样有GRE数学$=140$的学生的潜在可观察到的gpa的变化显示在顶部的面板中。这种差异的部分原因是学生的语言表达能力不同,第二个小组通过考虑像汉斯这样有GRE数学$=140$和GRE语言$=160$的学生的GPA差异,消除了这种差异的来源。但这种差异的一部分可以用学生的勤奋程度来解释。假设本科GPA是衡量这种“勤奋”的一个合理标准,那么最后的小组就会考虑像汉斯这样拥有GRE数学$=140$、GRE语言$=160$和本科GPA $=2.7$的学生的GPA差异,从而消除这种差异的来源。当然,如果有额外的变量可用,这种情况还会继续下去,每个额外的变量都会消除一个变异源,导致方差越来越小的分布。
图11.1所示分布的均值分别为$3.365,3.5$和3.44。如果你要用其中一个分布来预测汉斯,你会选哪个?显然,你应该选择方差最小的那个。他的最终GPA在所有三个分布下都是相同的数字,并且由于第三个分布的方差最小,他的GPA可能更接近其平均值(3.44),而不是另一个分布的平均值(3.365或3.5)。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
微观经济学代写
微观经济学是主流经济学的一个分支,研究个人和企业在做出有关稀缺资源分配的决策时的行为以及这些个人和企业之间的相互作用。my-assignmentexpert™ 为您的留学生涯保驾护航 在数学Mathematics作业代写方面已经树立了自己的口碑, 保证靠谱, 高质且原创的数学Mathematics代写服务。我们的专家在图论代写Graph Theory代写方面经验极为丰富,各种图论代写Graph Theory相关的作业也就用不着 说。
线性代数代写
线性代数是数学的一个分支,涉及线性方程,如:线性图,如:以及它们在向量空间和通过矩阵的表示。线性代数是几乎所有数学领域的核心。
博弈论代写
现代博弈论始于约翰-冯-诺伊曼(John von Neumann)提出的两人零和博弈中的混合策略均衡的观点及其证明。冯-诺依曼的原始证明使用了关于连续映射到紧凑凸集的布劳威尔定点定理,这成为博弈论和数学经济学的标准方法。在他的论文之后,1944年,他与奥斯卡-莫根斯特恩(Oskar Morgenstern)共同撰写了《游戏和经济行为理论》一书,该书考虑了几个参与者的合作游戏。这本书的第二版提供了预期效用的公理理论,使数理统计学家和经济学家能够处理不确定性下的决策。
微积分代写
微积分,最初被称为无穷小微积分或 “无穷小的微积分”,是对连续变化的数学研究,就像几何学是对形状的研究,而代数是对算术运算的概括研究一样。
它有两个主要分支,微分和积分;微分涉及瞬时变化率和曲线的斜率,而积分涉及数量的累积,以及曲线下或曲线之间的面积。这两个分支通过微积分的基本定理相互联系,它们利用了无限序列和无限级数收敛到一个明确定义的极限的基本概念 。
计量经济学代写
什么是计量经济学?
计量经济学是统计学和数学模型的定量应用,使用数据来发展理论或测试经济学中的现有假设,并根据历史数据预测未来趋势。它对现实世界的数据进行统计试验,然后将结果与被测试的理论进行比较和对比。
根据你是对测试现有理论感兴趣,还是对利用现有数据在这些观察的基础上提出新的假设感兴趣,计量经济学可以细分为两大类:理论和应用。那些经常从事这种实践的人通常被称为计量经济学家。
Matlab代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。