机器学习代写|决策树作业代写decision tree代考|Other Induction Strategies
如果你也在 怎样代写决策树decision tree这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
决策树是一种决策支持工具,它使用决策及其可能后果的树状模型,包括偶然事件结果、资源成本和效用。它是显示一个只包含条件控制语句的算法的一种方式。
statistics-lab™ 为您的留学生涯保驾护航 在代写决策树decision tree方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写决策树decision tree代写方面经验极为丰富,各种代写决策树decision tree相关的作业也就用不着说。
我们提供的决策树decision tree及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
机器学习代写|决策树作业代写decision tree代考|Other Induction Strategies
We presented a thorough review of the greedy top-down strategy for induction of decision trees in the previous section. In this section, we briefly present alternative strategies for inducing decision trees.
Bottom-up induction of decision trees was first mentioned in [59]. The authors propose a strategy that resembles agglomerative hierarchical clustering. The algorithm starts with each leaf having objects of the same class. In that way, a $k$-class
problem will generate a decision tree with $k$ leaves. The key idea is to merge, recursively, the two most similar classes in a non-terminal node. Then, a hyperplane is associated to the new non-terminal node, much in the same way as in top-down induction of oblique trees (in [59], a linear discriminant analysis procedure generates the hyperplanes). Next, all objects in the new non-terminal node are considered to be members of the same class (an artificial class that embodies the two clustered classes), and the procedure evaluates once again which are the two most similar classes. By recursively repeating this strategy, we end up with a decision tree in which the more obvious discriminations are done first, and the more subtle distinctions are postponed to lower levels. Landeweerd et al. [59] propose using the Mahalanobis distance to evaluate similarity among classes:
where $\mu_{y_{i}}$ is the mean attribute vector of class $y_{i}$ and $\Sigma$ is the covariance matrix pooled over all classes.
Some obvious drawbacks of this strategy of bottom-up induction are: (i) binaryclass problems provide a l-level decision tree (root node and two children); such a simple tree cannot model complex problems; (ii) instances from the same class may be located in very distinct regions of the attribute space, harming the initial assumption that instances from the same class should be located in the same leaf node; (iii) hierarchical clustering and hyperplane generation are costly operations; in fact, a procedure for inverting the covariance matrix in the Mahalanobis distance is usually of time complexity proportional to $O\left(n^{3}\right) .^{5}$ We believe these issues are among the main reasons why bottom-up induction has not become as popular as topdown induction. For alleviating these problems, Barros et al. [4] propose a bottom-up induction algorithm named BUTIA that combines EM clustering with SVM classifiers. The authors later generalize BUTIA to a framework for generating oblique decision trees, namely BUTIF [5], which allows the application of different clustering and classification strategies.
Hybrid induction was investigated in [56]. The ideia is to combine both bottom-up and top-down approaches for building the final decision tree. The algorithm starts by executing the bottom-up approach as described above until two subgroups are achieved. Then, two centers (mean attribute vectors) and covariance information are extracted from these subgroups and used for dividing the training data in a topdown fashion according to a normalized sum-of-squared-error criterion. If the two new partitions induced account for separated classes, then the hybrid induction is finished; otherwise, for each subgroup that does not account for a class, recursively executes the hybrid induction by once again starting with the bottom-up procedure. Kim and Landgrebe [56] argue that in hybrid induction “It is more likely to converge to classes of informational value, because the clustering initialization provides early
guidance in that direction, while the straightforward top-down approach does not guarantee such convergence”.
Several studies attempted on avoiding the greedy strategy usually employed for inducing trees. For instance, lookahead was employed for trying to improve greedy induction $[17,23,29,79,84]$. Murthy and Salzberg [79] show that one-level lookahead does not help building significantly better trees and can actually worsen the quality of trees induced. A more recent strategy for avoiding greedy decision-tree induction is to generate decision trees through evolutionary algorithms. The idea involved is to consider each decision tree as an individual in a population, which is evolved through a certain number of generations. Decision trees are modified by genetic operators, which are performed stochastically. A thorough review of decisiontree induction through evolutionary algorithms is presented in [6].
机器学习代写|决策树作业代写decision tree代考|Chapter Remarks
In this chapter, we presented the main design choices one has to face when programming a decision-tree induction algorithm. We gave special emphasis to the greedy top-down induction strategy, since it is by far the most researched technique for decision-tree induction.
Regarding top-down induction, we presented the most well-known splitting measures for univariate decision trees, as well as some new criteria found in the literature, in an unified notation. Furthermore, we introduced some strategies for building decision trees with multivariate tests, the so-called oblique trees. In particular, we showed that efficient oblique decision-tree induction has to make use of heuristics in order to derive “good” hyperplanes within non-terminal nodes. We detailed the strategy employed in the $\mathrm{OCl}$ algorithm $[77,80]$ for deriving hyperplanes with the help of a randomized perturbation process. Following, we depicted the most common stopping criteria and post-pruning techniques employed in classic algorithms such as CART [12] and C4.5 [89], and we ended the discussion on top-down induction with an enumeration of possible strategies for dealing with missing values, either in the growing phase or during classification of a new instance.
We ended our analysis on decision trees with some alternative induction strategies, such as bottom-up induction and hybrid-induction. In addition, we briefly discussed work that attempt to avoid the greedy strategy, by either implementing lookahead techniques, evolutionary algorithms, beam-search, linear programming, (non-) incremental restructuring, skewing, or anytime learning. In the next chapters, we present an overview of evolutionary algorithms and hyper-heuristics, and review how they can be applied to decision-tree induction.
机器学习代写|决策树作业代写decision tree代考|Evolutionary Algorithms
Evolutionary algorithms (EAs) are a collection of optimisation techniques whose design is based on metaphors of biological processes. Fretias [20] defines EAs as “stochastic search algorithms inspired by the process of neo-Darwinian evolution”, and Weise [44] states that “EAs are population-based metaheuristic optimisation algorithms that use biology-inspired mechanisms (…) in order to refine a set of solution candidates iteratively”.
The idea surrounding EAs is the following. There is a population of individuals, where each individual is a possible solution to a given problem. This population evolves towards increasingly better solutions through stochastic operators. After the evolution is completed, the fittest individual represents a “near-optimal” solution for the problem at hand.
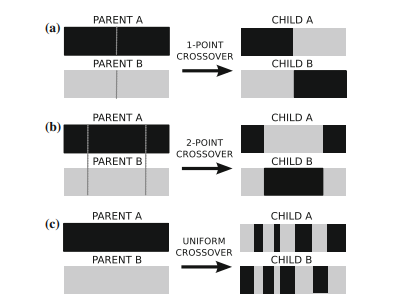
For evolving individuals, an EA evaluates each individual through a fitness function that measures the quality of the solutions that are being evolved. After the evaluation of all individuals that are part of the initial population, the algorithm’s iterative process starts. At each iteration, hereby called generation, the fittest individuals have a higher probability of being selected for reproduction to increase the chances of producing good solutions. The selected individuals undergo stochastic genetic operators, such as crossover and mutation, producing new offspring. These new individuals will replace the current population of individuals and the evolutionary process continues until a stopping criterion is satisfied (e.g., until a fixed number of generations is achieved, or until a satisfactory solution has been found).
There are several kinds of EAs, such as genetic algorithms (GAs), genetic programming (GP), classifier systems (CS), evolution strategies (ES), evolutionary programming (EP), estimation of distribution algorithms (EDA), etc. This chapter will focus on GA and GP, the most commonly used EAs for data mining [19]. At a high level of abstraction, GAs and GP can be described by the pseudocode in Algorithm $1 .$
决策树代写
机器学习代写|决策树作业代写decision tree代考|Other Induction Strategies
我们在上一节中对用于归纳决策树的贪心自上而下策略进行了全面回顾。在本节中,我们简要介绍了诱导决策树的替代策略。
决策树的自下而上归纳在 [59] 中首次提到。作者提出了一种类似于凝聚层次聚类的策略。该算法从每个叶子具有相同类的对象开始。这样,一个ķ-班级
问题将生成一个决策树ķ树叶。关键思想是递归地合并非终端节点中两个最相似的类。然后,超平面与新的非终端节点相关联,这与自上而下的倾斜树归纳方法非常相似(在 [59] 中,线性判别分析程序生成超平面)。接下来,新的非终端节点中的所有对象都被认为是同一类的成员(体现两个聚类类的人工类),并且该过程再次评估哪些是两个最相似的类。通过递归重复这个策略,我们最终得到一个决策树,其中首先进行更明显的区分,而将更细微的区分推迟到较低级别。兰德维尔德等人。[59] 建议使用马氏距离来评估类之间的相似性:
在哪里μ是一世是类的平均属性向量是一世和Σ是汇集在所有类上的协方差矩阵。
这种自下而上归纳策略的一些明显缺点是:(i)二元类问题提供了一个 l 级决策树(根节点和两个孩子);这样一棵简单的树不能模拟复杂的问题;(ii) 来自同一类的实例可能位于属性空间的非常不同的区域,损害了来自同一类的实例应该位于同一叶节点的初始假设;(iii) 层次聚类和超平面生成是昂贵的操作;事实上,在马氏距离中反转协方差矩阵的过程通常与时间复杂度成正比这(n3).5我们认为这些问题是自下而上归纳没有像自上而下归纳那样流行的主要原因之一。为了缓解这些问题,Barros 等人。[4] 提出了一种名为 BUTIA 的自下而上的归纳算法,它将 EM 聚类与 SVM 分类器相结合。作者后来将 BUTIA 推广到生成倾斜决策树的框架,即 BUTIF [5],它允许应用不同的聚类和分类策略。
在[56]中研究了混合诱导。想法是结合自下而上和自上而下的方法来构建最终的决策树。该算法首先执行如上所述的自下而上方法,直到获得两个子组。然后,从这些子组中提取两个中心(平均属性向量)和协方差信息,并用于根据归一化误差平方和标准以自上而下的方式划分训练数据。如果这两个新的分区导致了分离的类,那么混合归纳就结束了;否则,对于每个不考虑类的子组,通过再次从自下而上过程开始递归地执行混合归纳。Kim 和 Landgrebe [56] 认为,在混合归纳中,“它更有可能收敛到信息价值类别,
在这个方向上提供指导,而直接的自上而下的方法并不能保证这种趋同”。
一些研究试图避免通常用于诱导树的贪婪策略。例如,前瞻被用于试图改进贪婪归纳[17,23,29,79,84]. Murthy 和 Salzberg [79] 表明,一级前瞻无助于构建明显更好的树木,实际上会恶化诱导的树木质量。最近避免贪婪决策树归纳的策略是通过进化算法生成决策树。所涉及的想法是将每个决策树视为群体中的一个个体,它是通过一定数量的世代进化而来的。决策树由随机执行的遗传算子修改。[6] 中介绍了通过进化算法对决策树归纳的全面回顾。
机器学习代写|决策树作业代写decision tree代考|Chapter Remarks
在本章中,我们介绍了在编写决策树归纳算法时必须面对的主要设计选择。我们特别强调了贪心自上而下的归纳策略,因为它是迄今为止研究最多的决策树归纳技术。
关于自上而下的归纳,我们提出了最知名的单变量决策树拆分度量,以及文献中发现的一些新标准,以统一的符号表示。此外,我们介绍了一些用于构建具有多变量测试的决策树的策略,即所谓的倾斜树。特别是,我们展示了有效的倾斜决策树归纳必须利用启发式算法才能在非终端节点内推导出“好的”超平面。我们详细介绍了这Cl算法[77,80]用于在随机扰动过程的帮助下推导超平面。接下来,我们描述了 CART [12] 和 C4.5 [89] 等经典算法中使用的最常见的停止标准和后剪枝技术,并通过列举可能的处理策略来结束关于自上而下归纳的讨论缺少值,无论是在成长阶段还是在新实例的分类过程中。
我们用一些替代的归纳策略结束了对决策树的分析,例如自下而上的归纳和混合归纳。此外,我们简要讨论了试图通过实施前瞻技术、进化算法、波束搜索、线性规划、(非)增量重组、倾斜或随时学习来避免贪婪策略的工作。在接下来的章节中,我们将概述进化算法和超启发式,并回顾如何将它们应用于决策树归纳。
机器学习代写|决策树作业代写decision tree代考|Evolutionary Algorithms
进化算法 (EA) 是一组优化技术,其设计基于生物过程的隐喻。Fretias [20] 将 EA 定义为“受新达尔文进化过程启发的随机搜索算法”,Weise [44] 指出,“EA 是基于群体的元启发式优化算法,它使用受生物学启发的机制 (…)迭代地细化一组候选解决方案”。
围绕 EA 的想法如下。有一群人,其中每个人都是给定问题的可能解决方案。这个群体通过随机算子向越来越好的解决方案发展。进化完成后,最适合的个体代表手头问题的“接近最佳”解决方案。
对于进化中的个体,EA 通过一个适应度函数来评估每个个体,该函数测量正在进化的解决方案的质量。在对属于初始种群的所有个体进行评估后,算法的迭代过程开始。在每次迭代中,在此称为生成,最适合的个体有更高的概率被选中进行繁殖,以增加产生良好解决方案的机会。选定的个体经过随机遗传算子,例如交叉和突变,产生新的后代。这些新个体将取代当前个体种群并且进化过程继续直到满足停止标准(例如,直到达到固定数量的世代,或直到找到令人满意的解决方案)。
EA有几种类型,如遗传算法(GAs)、遗传编程(GP)、分类系统(CS)、进化策略(ES)、进化编程(EP)、分布估计算法(EDA)等。本章将重点介绍 GA 和 GP,这是数据挖掘中最常用的 EA [19]。在高抽象层次上,GAs 和 GP 可以用 Algorithm 中的伪代码来描述1.

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。