统计代写|STAT311 Linear regression
Statistics-lab™可以为您提供metrostate.edu STAT311 Linear regression线性回归课程的代写代考和辅导服务!

STAT311 Linear regression课程简介
This course covers various statistical models such as simple linear regression, multiple regression, and analysis of variance. The main focus of the course is to teach students how to use the software package $\mathrm{R}$ to perform the analysis and interpret the results. Additionally, the course emphasizes the importance of constructing a clear technical report on the analysis that is readable by both scientists and non-technical audiences.
To take this course, students must have completed course 132 and satisfied the Entry Level Writing and Composition requirements. This course satisfies the General Education Code W requirement.
PREREQUISITES
Covers simple linear regression, multiple regression, and analysis of variance models. Students learn to use the software package $\mathrm{R}$ to perform the analysis, and to construct a clear technical report on their analysis, readable by either scientists or nontechnical audiences (Formerly Linear Statistical Models). Prerequisite(s): course 132 and satisfaction of the Entry Level Writing and Composition requirements. Gen. Ed. Code(s): W
STAT311 Linear regression HELP(EXAM HELP, ONLINE TUTOR)
Proposition 3.1. Suppose that a numerical variable selection method suggests several submodels with $k$ predictors, including a constant, where $2 \leq k \leq p$
a) The model $I$ that minimizes $C_p(I)$ maximizes $\operatorname{corr}\left(r, r_I\right)$.
b) $C_p(I) \leq 2 k$ implies that $\operatorname{corr}\left(\mathrm{r}, \mathrm{r}{\mathrm{I}}\right) \geq \sqrt{1-\frac{\mathrm{p}}{\mathrm{n}}}$. c) As $\operatorname{corr}\left(r, r_I\right) \rightarrow 1$, $$ \operatorname{corr}\left(\boldsymbol{x}^{\mathrm{T}} \hat{\boldsymbol{\beta}}, \boldsymbol{x}{\mathrm{I}}^{\mathrm{T}} \hat{\boldsymbol{\beta}}{\mathrm{I}}\right)=\operatorname{corr}(\mathrm{ESP}, \mathrm{ESP}(\mathrm{I}))=\operatorname{corr}\left(\hat{\mathrm{Y}}, \hat{\mathrm{Y}}{\mathrm{I}}\right) \rightarrow 1
$$
Remark 3.1. Consider the model $I_i$ that deletes the predictor $x_i$. Then the model has $k=p-1$ predictors including the constant, and the test statistic is $t_i$ where
$$
t_i^2=F_{I_i}
$$
Using Definition 3.8 and $C_p\left(I_{\text {full }}\right)=p$, it can be shown that
$$
C_p\left(I_i\right)=C_p\left(I_{\text {full }}\right)+\left(t_i^2-2\right) .
$$
Using the screen $C_p(I) \leq \min (2 k, p)$ suggests that the predictor $x_i$ should not be deleted if
$$
\left|t_i\right|>\sqrt{2} \approx 1.414
$$
If $\left|t_i\right|<\sqrt{2}$, then the predictor can probably be deleted since $C_p$ decreases. The literature suggests using the $C_p(I) \leq k$ screen, but this screen eliminates too many potentially useful submodels.
Proposition 3.2. Suppose that every submodel contains a constant and that $\boldsymbol{X}$ is a full rank matrix.
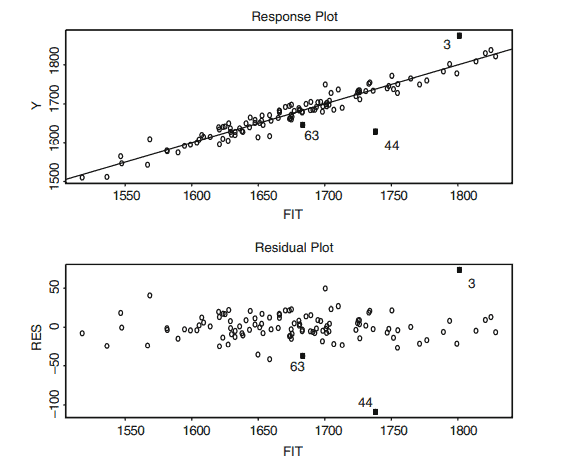
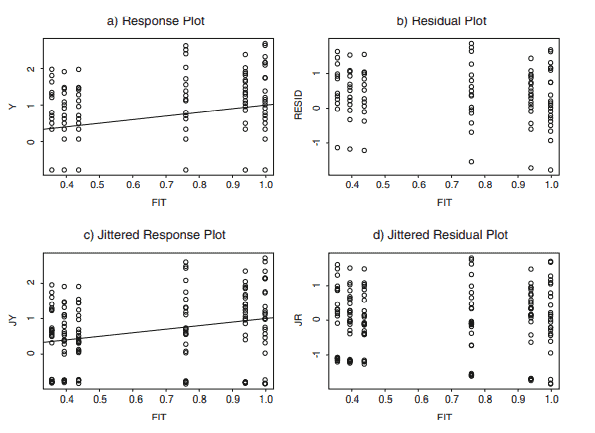
Response Plot: i) If $w=\hat{Y}I$ and $z=Y$, then the OLS line is the identity line. ii) If $w=Y$ and $z=\hat{Y}_I$, then the OLS line has slope $b=\left[\operatorname{corr}\left(Y, \hat{Y}_I\right)\right]^2=$ $R^2(I)$ and intercept $a=\bar{Y}\left(1-R^2(I)\right)$ where $\bar{Y}=\sum{i=1}^n Y_i / n$ and $R^2(I)$ is the coefficient of multiple determination from the candidate model.
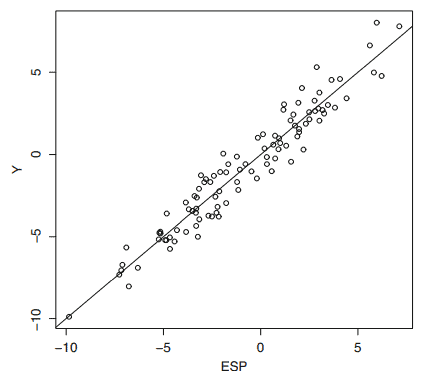
FF or EE Plot: iii) If $w=\hat{Y}_I$ and $z=\hat{Y}$, then the OLS line is the identity line. Note that $E S P(I)=\hat{Y}_I$ and $E S P=\hat{Y}$.
iv) If $w=\hat{Y}$ and $z=\hat{Y}_I$, then the OLS line has slope $b=\left[\operatorname{corr}\left(\hat{Y}, \hat{Y}_I\right)\right]^2=$ $S S R(I) / S S R$ and intercept $a=\bar{Y}[1-(S S R(I) / S S R)]$ where SSR is the regression sum of squares.
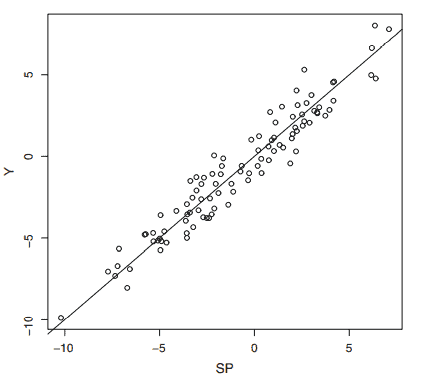
RR Plot: v) If $w=r$ and $z=r_I$, then the OLS line is the identity line.
vi) If $w=r_I$ and $z=r$, then $a=0$ and the OLS slope $b=\left[\operatorname{corr}\left(r, r_I\right)\right]^2$ and
$$
\operatorname{corr}\left(r, r_I\right)=\sqrt{\frac{S S E}{S S E(I)}}=\sqrt{\frac{n-p}{C_p(I)+n-2 k}}=\sqrt{\frac{n-p}{(p-k) F_I+n-p}} .
$$
Proof: Recall that $\boldsymbol{H}$ and $\boldsymbol{H}_I$ are symmetric idempotent matrices and that $\boldsymbol{H}_I=\boldsymbol{H}_I$. The mean of OLS fitted values is equal to $\bar{Y}$ and the mean of OLS residuals is equal to 0 . If the OLS line from regressing $z$ on $w$ is $\hat{z}=a+b w$, then $a=\bar{z}-b \bar{w}$ and $$
b=\frac{\sum\left(w_i-\bar{w}\right)\left(z_i-\bar{z}\right)}{\sum\left(w_i-\bar{w}\right)^2}=\frac{S D(z)}{S D(w)} \operatorname{corr}(z, w) .
$$
Also recall that the OLS line passes through the means of the two variables $(\bar{w}, \bar{z})$
$\left(^\right)$ Notice that the OLS slope from regressing $z$ on $w$ is equal to one if and only if the OLS slope from regressing $w$ on $z$ is equal to $[\operatorname{corr}(z, w)]^2$. i) The slope $b=1$ if $\sum \hat{Y}{I, i} Y_i=\sum \hat{Y}{I, i}^2$. This equality holds since $\hat{\boldsymbol{Y}}I^T \boldsymbol{Y}=$ $\boldsymbol{Y}^T \boldsymbol{H}_I \boldsymbol{Y}=\boldsymbol{Y}^T \boldsymbol{H}_I \boldsymbol{H}_I \boldsymbol{Y}=\hat{\boldsymbol{Y}}_I^T \hat{\boldsymbol{Y}}_I$. Since $b=1, a=\bar{Y}-\bar{Y}=0$. ii) By $\left(^\right)$, the slope
$$
b=\left[\operatorname{corr}\left(Y, \hat{Y}_I\right)\right]^2=R^2(I)=\frac{\sum\left(\hat{Y}{I, i}-\bar{Y}\right)^2}{\sum\left(Y_i-\bar{Y}\right)^2}=\operatorname{SSR}(I) / \operatorname{SSTO} .
$$
The result follows since $a=\bar{Y}-b \bar{Y}$.
iii) The slope $b=1$ if $\sum \hat{Y}{I, i} \hat{Y}_i=\sum \hat{Y}{I, i}^2$. This equality holds since $\hat{\boldsymbol{Y}}^T \hat{\boldsymbol{Y}}_I=\boldsymbol{Y}^T \boldsymbol{H} \boldsymbol{H}_I \boldsymbol{Y}=\boldsymbol{Y}^T \boldsymbol{H}_I \boldsymbol{Y}=\hat{\boldsymbol{Y}}_I^T \hat{\boldsymbol{Y}}_I$. Since $b=1, a=\bar{Y}-\bar{Y}=0$.
iv) From iii),
$$
1=\frac{S D(\hat{Y})}{S D\left(\hat{Y}_I\right)}\left[\operatorname{corr}\left(\hat{Y}, \hat{Y}_I\right)\right] .
$$
Textbooks
• An Introduction to Stochastic Modeling, Fourth Edition by Pinsky and Karlin (freely
available through the university library here)
• Essentials of Stochastic Processes, Third Edition by Durrett (freely available through
the university library here)
To reiterate, the textbooks are freely available through the university library. Note that
you must be connected to the university Wi-Fi or VPN to access the ebooks from the library
links. Furthermore, the library links take some time to populate, so do not be alarmed if
the webpage looks bare for a few seconds.

Statistics-lab™可以为您提供metrostate.edu STAT311 Linear regression线性回归课程的代写代考和辅导服务! 请认准Statistics-lab™. Statistics-lab™为您的留学生涯保驾护航。