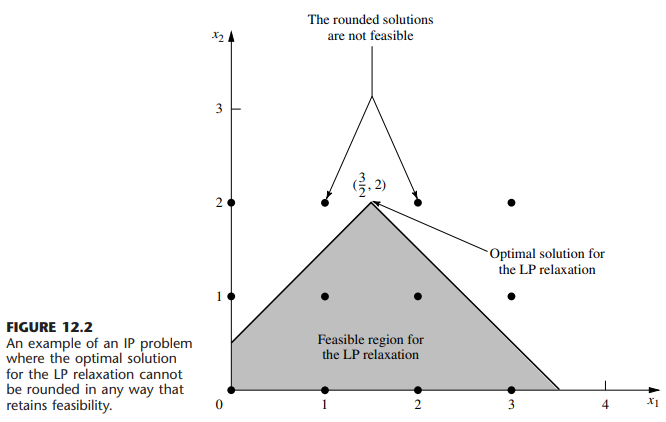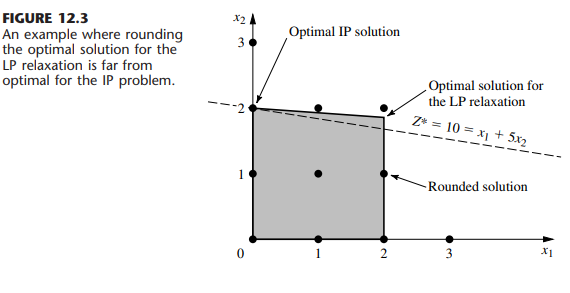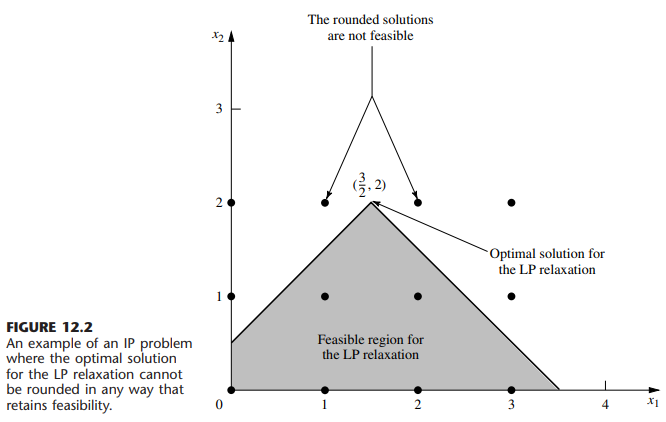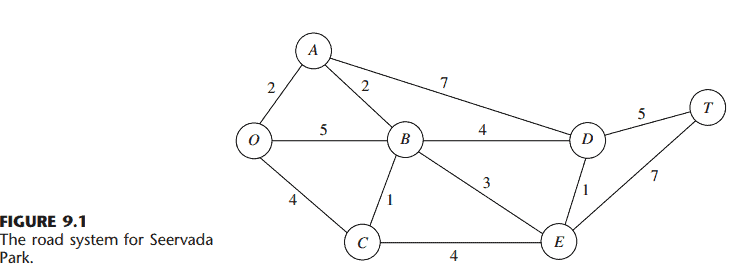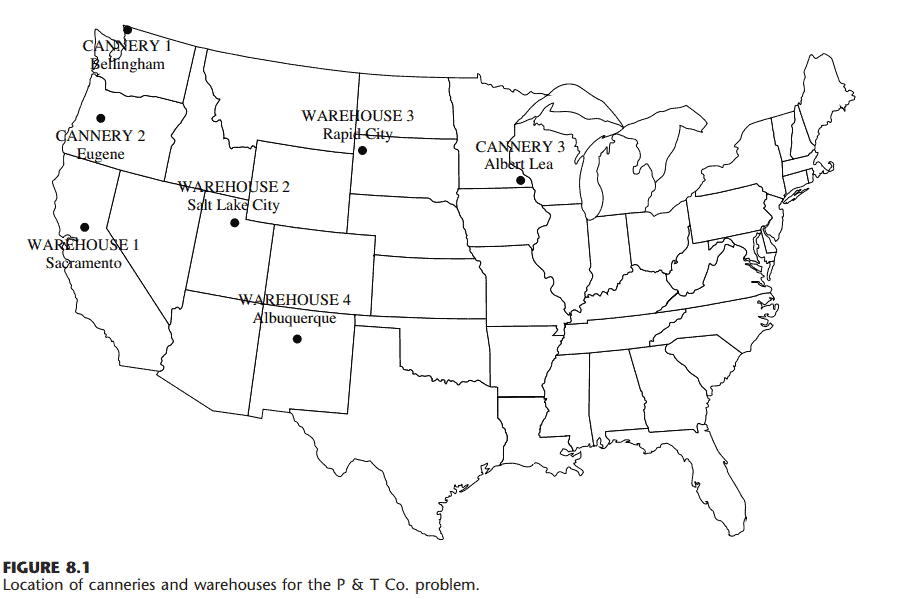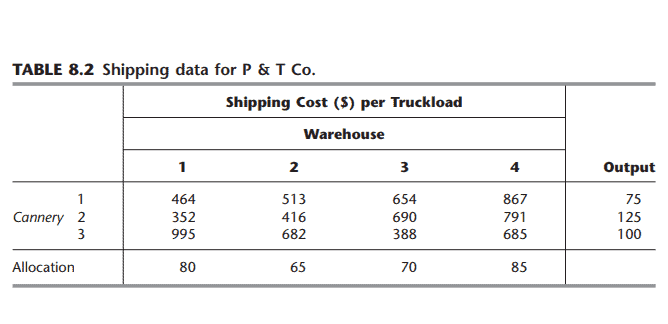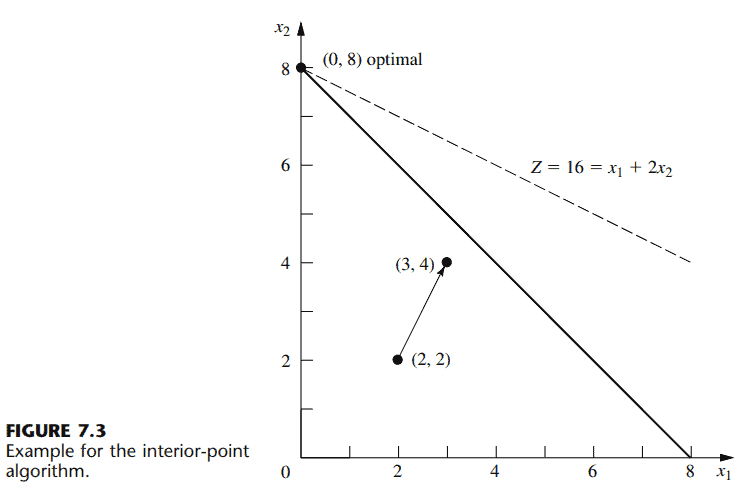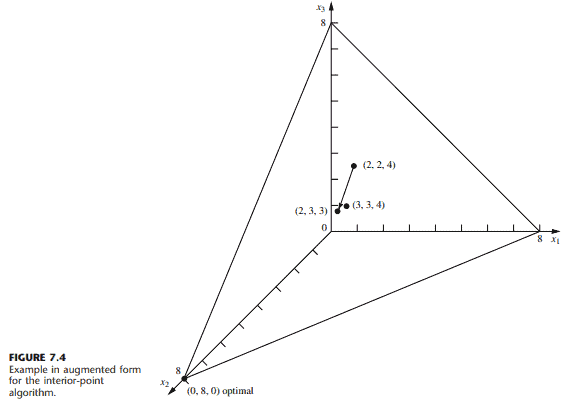
数学代写|运筹学作业代写operational research代考|MTH2105
如果你也在 怎样代写运筹学Operations Research 这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。运筹学Operations Research为管理者、工程师和任何有更好解决方案的实践者提供更好的解决方案。这门科学诞生于第二次世界大战期间。虽然它最初用于军事行动,但它的应用以某种形式扩展到地球上的任何领域。
运筹学Operations Research是将科学方法应用于解决复杂问题,指导和管理工业、商业、政府和国防中由人、机器、材料和资金组成的大型系统。独特的方法是开发一个系统的科学模型,包括诸如变化和风险等因素的测量,以此来预测和比较不同决策、战略或控制的结果。其目的是帮助管理层科学地确定其政策和行动。
statistics-lab™ 为您的留学生涯保驾护航 在代写运筹学operational research方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写运筹学operational research代写方面经验极为丰富,各种代写运筹学operational research相关的作业也就用不着说。
数学代写|运筹学作业代写operational research代考|A BRANCH-AND-BOUND ALGORITHM FOR MIXED INTEGER PROGRAMMING
We shall now consider the general MIP problem, where some of the variables (say, $I$ of them) are restricted to integer values (but not necessarily just 0 and 1) but the rest are ordinary continuous variables. For notational convenience, we shall order the variables so that the first $I$ variables are the integer-restricted variables. Therefore, the general form of the problem being considered is
$$
\text { Maximize } \quad Z=\sum_{j=1}^n c_j x_j,
$$
subject to
$$
\sum_{j=1}^n a_{i j} x_j \leq b_i, \quad \text { for } i=1,2, \ldots, m,
$$
and
$$
\begin{aligned}
& x_j \geq 0, \quad \text { for } j=1,2, \ldots, n, \
& x_j \text { is integer, for } j=1,2, \ldots, I ; I \leq n .
\end{aligned}
$$
(When $I=n$, this problem becomes the pure IP problem.)
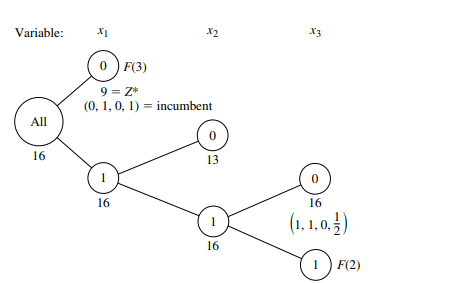
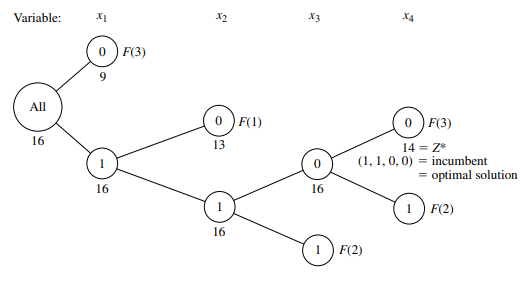
We shall describe a basic branch-and-bound algorithm for solving this problem that, with a variety of refinements, has provided a standard approach to MIP. The structure of this algorithm was first developed by R. J. Dakin, ${ }^1$ based on a pioneering branch-andbound algorithm by A. H. Land and A. G. Doig. ${ }^2$
This algorithm is quite similar in structure to the BIP algorithm presented in the preceding section. Solving LP relaxations again provides the basis for both the bounding and fathoming steps. In fact, only four changes are needed in the BIP algorithm to deal with the generalizations from binary to general integer variables and from pure IP to mixed IP.
One change involves the choice of the branching variable. Before, the next variable in the natural ordering $-x_1, x_2, \ldots, x_n$-was chosen automatically. Now, the only variables considered are the integer-restricted variables that have a noninteger value in the optimal solution for the LP relaxation of the current subproblem. Our rule for choosing among these variables is to select the first one in the natural ordering. (Production codes generally use a more sophisticated rule.)
数学代写|运筹学作业代写operational research代考|OTHER DEVELOPMENTS IN SOLVING BIP PROBLEMS
Integer programming has been an especially exciting area of OR since the mid-1980s because of the dramatic progress being made in its solution methodology.
Background
To place this progress into perspective, consider the historical background. One big breakthrough had come in the 1960 s and early 1970 s with the development and refinement of the branch-and-bound approach. But then the state of the art seemed to hit a plateau. Relatively small problems (well under 100 variables) could be solved very efficiently, but even a modest increase in problem size might cause an explosion in computation time beyond feasible limits. Little progress was being made in overcoming this exponential growth in computation time as the problem size was increased. Many important problems arising in practice could not be solved.
Then came the next breakthrough in the mid-1980s, as reported largely in four papers published in 1983, 1985, 1987, and 1991. (See Selected References 3, 6, 10, and 5.)
In the 1983 paper, Harlan Crowder, Ellis Johnson, and Manfred Padberg presented a new algorithmic approach to solving pure BIP problems that had successfully solved problems with no apparent special structure having up to 2,756 variables! This paper won the Lanchester Prize, awarded by the Operations Research Society of America for the most notable publication in operations research during 1983. In the 1985 paper, Ellis Johnson, Michael Kostreva, and Uwe Suhl further refined this algorithmic approach.
However, both of these papers were limited to pure BIP. For IP problems arising in practice, it is quite common for all the integer-restricted variables to be binary, but a large proportion of these problems are mixed BIP problems. What was critically needed was a way of extending this same kind of algorithmic approach to mixed BIP. This came in the 1987 paper by Tony Van Roy and Laurence Wolsey of Belgium. Once again, problems of very substantial size (up to nearly 1,000 binary variables and a larger number of continuous variables) were being solved successfully. And once again, this paper won a very prestigious award, the Orchard-Hays Prize given triannually by the Mathematical Programming Society.
In the 1991 paper, Karla Hoffman and Manfred Padberg followed up on the 1983 and 1985 papers by developing improved techniques for solving pure BIP problems. Using the name branch-and-cut algorithm for this algorithmic approach, they reported successfully solving problems with as many as 6,000 variables!
运筹学代考
数学代写|运筹学作业代写operational research代考|A BRANCH-AND-BOUND ALGORITHM FOR MIXED INTEGER PROGRAMMING
现在我们将考虑一般的MIP问题,其中一些变量(例如,$I$)被限制为整数值(但不一定只有0和1),而其余的则是普通的连续变量。为了表示方便,我们将对变量进行排序,以便第一个$I$变量是整数限制变量。因此,所考虑问题的一般形式是
$$
\text { Maximize } \quad Z=\sum_{j=1}^n c_j x_j,
$$
以
$$
\sum_{j=1}^n a_{i j} x_j \leq b_i, \quad \text { for } i=1,2, \ldots, m,
$$
和
$$
\begin{aligned}
& x_j \geq 0, \quad \text { for } j=1,2, \ldots, n, \
& x_j \text { is integer, for } j=1,2, \ldots, I ; I \leq n .
\end{aligned}
$$
(当$I=n$时,这个问题变成了纯粹的IP问题。)
我们将描述一个基本的分支定界算法来解决这个问题,该算法经过各种改进,为MIP提供了一个标准方法。该算法的结构首先由r.j. Dakin开发,${ }^1$基于a . H. Land和a . G. Doig的开创性分支定界算法。 ${ }^2$
该算法在结构上与前面介绍的BIP算法非常相似。求解LP松弛再次为边界和深度步骤提供了基础。实际上,在BIP算法中只需要进行四处更改就可以处理从二进制到一般整数变量以及从纯IP到混合IP的泛化。
其中一个变化涉及到分支变量的选择。在此之前,自然排序中的下一个变量$-x_1, x_2, \ldots, x_n$ -是自动选择的。现在,考虑的唯一变量是在当前子问题的LP松弛的最优解中具有非整数值的整数限制变量。我们在这些变量中选择的规则是按自然顺序选择第一个变量。(生产代码通常使用更复杂的规则。)
数学代写|运筹学作业代写operational research代考|OTHER DEVELOPMENTS IN SOLVING BIP PROBLEMS
自20世纪80年代中期以来,整数规划一直是OR的一个特别令人兴奋的领域,因为它的解决方法取得了巨大的进展。
背景信息
要正确看待这一进步,请考虑一下历史背景。随着分支绑定方法的发展和完善,在20世纪60年代和70年代初出现了一个重大突破。但随后,技术水平似乎陷入了停滞。相对较小的问题(远低于100个变量)可以非常有效地解决,但即使问题规模适度增加,也可能导致计算时间的激增,超出可行的限制。随着问题规模的增加,在克服这种计算时间的指数增长方面几乎没有取得进展。实践中出现的许多重要问题无法得到解决。
接着,在1980年代中期出现了下一个突破,主要在1983年、1985年、1987年和1991年发表的四篇论文中进行了报道。(参见参考文献3、6、10和5。)
在1983年的论文中,哈伦·克劳德、埃利斯·约翰逊和曼弗雷德·帕德伯格提出了一种新的算法方法来解决纯BIP问题,并成功地解决了具有多达2756个变量的没有明显特殊结构的问题!这篇论文获得了兰彻斯特奖,这是1983年由美国运筹学学会颁发的运筹学领域最著名的论文。在1985年的论文中,Ellis Johnson、Michael Kostreva和Uwe Suhl进一步完善了这种算法方法。
然而,这两篇论文都局限于纯BIP。在实践中出现的IP问题中,所有的整数限制变量都是二进制的情况是很常见的,但这些问题中有很大一部分是混合IP问题。我们迫切需要的是将这种算法方法扩展到混合BIP。这是1987年比利时的托尼·范·罗伊和劳伦斯·沃尔西发表的论文。再一次,非常大规模的问题(多达近1000个二进制变量和更多数量的连续变量)被成功地解决了。这篇论文再次获得了一个非常有声望的奖项,奥查德-海斯奖,由数学规划学会每三年颁发一次。
在1991年的论文中,Karla Hoffman和Manfred Padberg在1983年和1985年的论文的基础上,开发了解决纯BIP问题的改进技术。在这种算法方法中使用分支切断算法,他们成功地解决了多达6000个变量的问题!

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。