计算机代写|机器学习代写machine learning代考|QBUS6850
如果你也在 怎样代写机器学习Machine Learning 这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。机器学习Machine Learning令人兴奋。这是有趣的,具有挑战性的,创造性的,和智力刺激。它还为公司赚钱,自主处理大量任务,并从那些宁愿做其他事情的人那里消除单调工作的繁重任务。
机器学习Machine Learning也非常复杂。从数千种算法、数百种开放源码包,以及需要具备从数据工程(DE)到高级统计分析和可视化等各种技能的专业实践者,ML专业实践者所需的工作确实令人生畏。增加这种复杂性的是,需要能够与广泛的专家、主题专家(sme)和业务单元组进行跨功能工作——就正在解决的问题的性质和ml支持的解决方案的输出进行沟通和协作。
statistics-lab™ 为您的留学生涯保驾护航 在代写机器学习 machine learning方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写机器学习 machine learning代写方面经验极为丰富,各种代写机器学习 machine learning相关的作业也就用不着说。
计算机代写|机器学习代写machine learning代考|Artifact management
Let’s imagine that we’re still working at the fire-risk department of the forest service introduced in chapter 15. In our efforts to effectively dispatch personnel and equipment to high-risk areas in the park system, we’ve arrived at a solution that works remarkably well. Our features are locked in and are stable over time. We’ve evaluated the performance of the predictions and are seeing genuine value from the model.
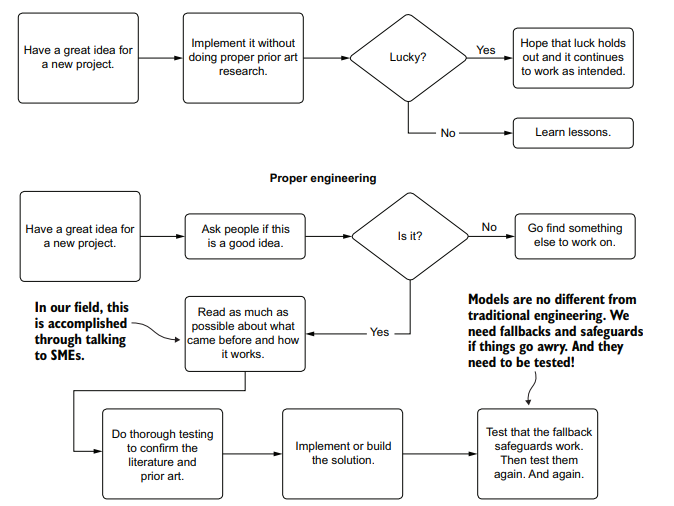
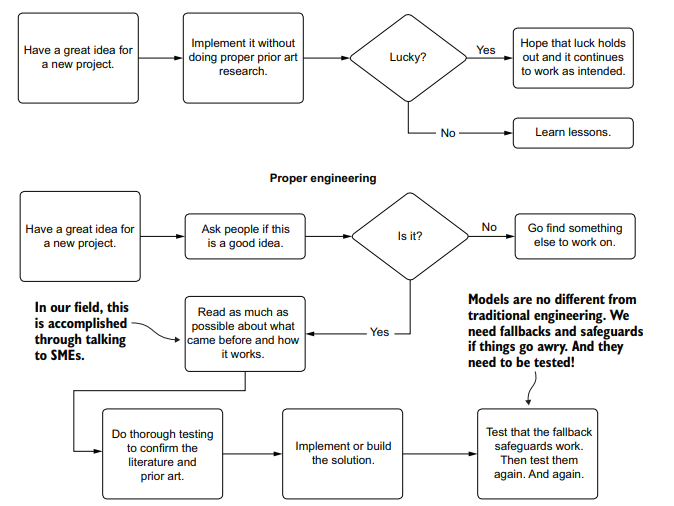
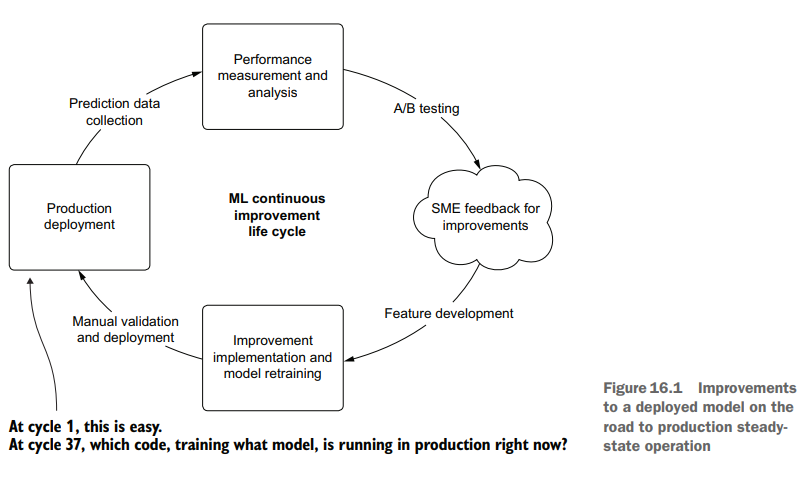
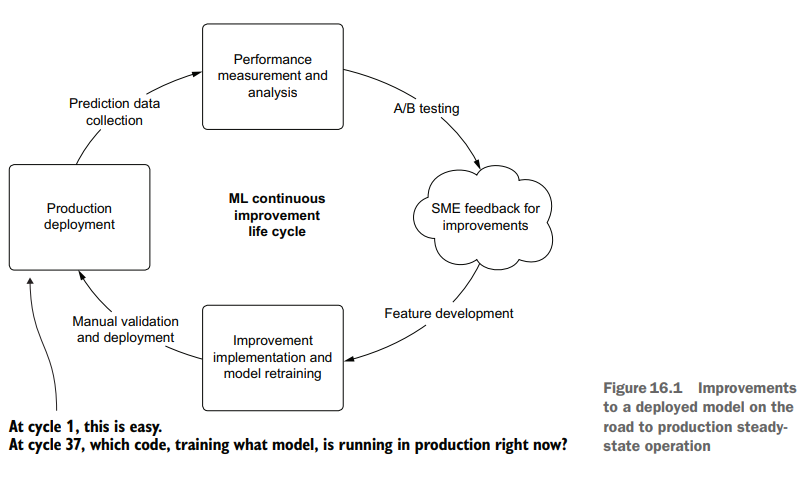
Throughout this process of getting the features into a good state, we’ve been iterating through the improvement cycle, shown in figure 16.1.
As this cycle shows, we’ve been iteratively releasing new versions of the model, testing against a baseline deployment, collecting feedback, and working to improve the predictions. At some point, however, we’ll be going into model-sustaining mode.
We’ve worked as hard as we can to improve the features going into the model and have found that the return on investment (ROI) of continuing to add new data elements to the project is simply not worth it. We’re now in the position of scheduled passive retraining of our model based on new data coming in over time.
When we’re at this steady-state point, the last thing that we want to do is to have one of the DS team members spend an afternoon manually retraining a model, manually comparing its results to the current production-deployed model with ad hoc analysis, and deciding on whether the model should be updated.
计算机代写|机器学习代写machine learning代考|MLflow’s model registry
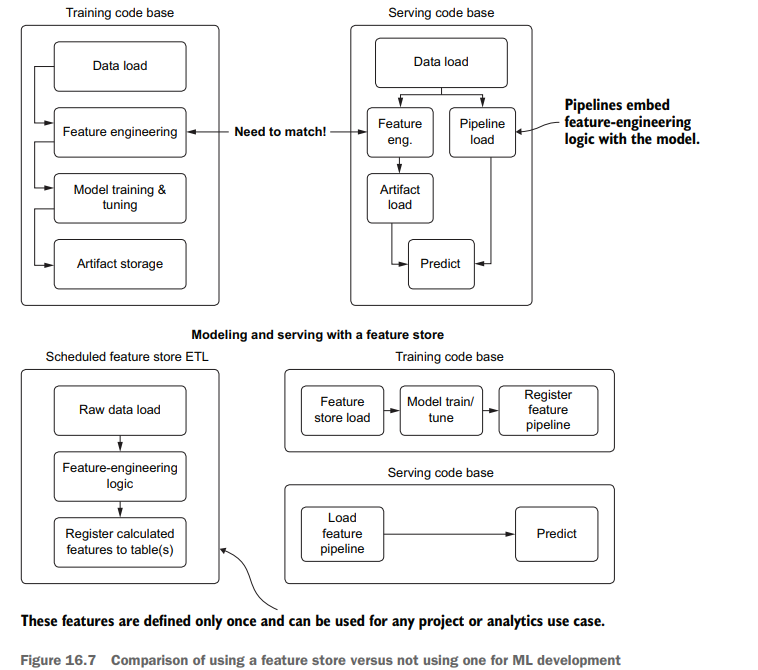
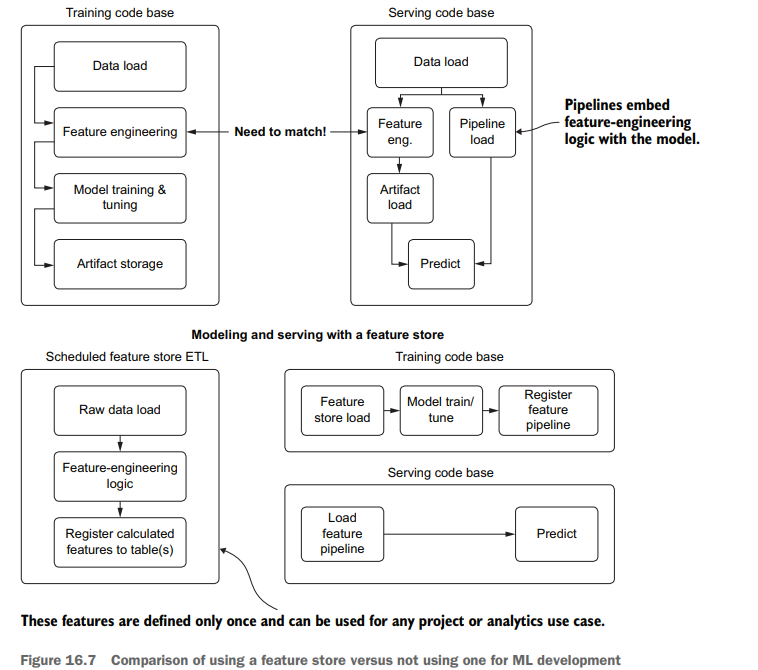
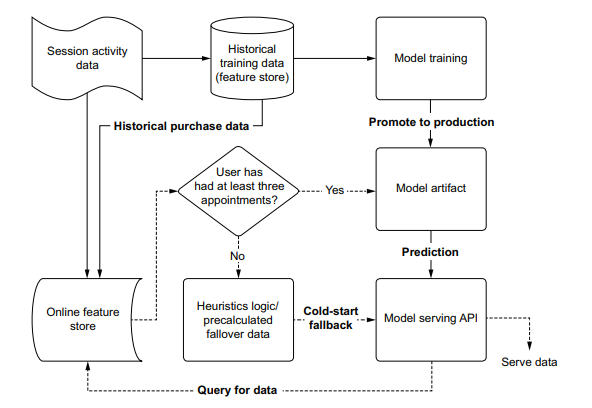
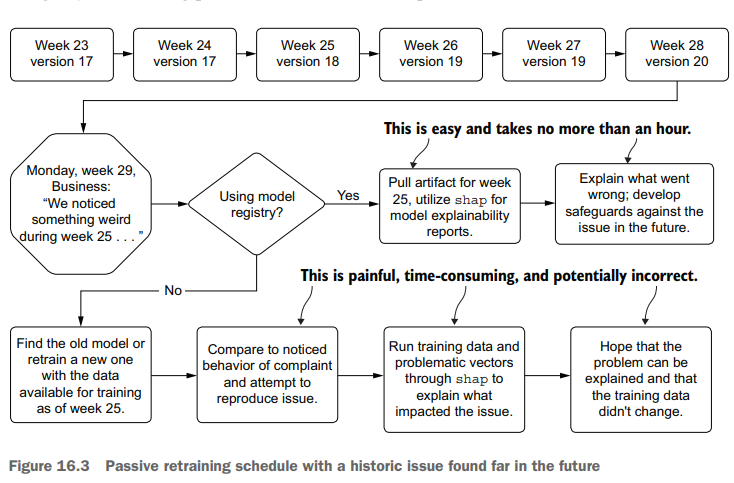
In this situation that we find ourselves in, with scheduled updates to a model happening autonomously, it is important for us to know the state of production deployment. Not only do we need to know the current state, but if questions arise about performance of a passive retraining system in the past, we need to have a means of investigating the historical provenance of the model. Figure 16.3 compares using and not using a registry for tracking provenance in order to explain a historical issue.
As you can see, the process for attempting to re-create a past run is fraught with peril; we have a high risk of being unable to reproduce the issue that the business found in historical predictions. With no registry to record the artifacts utilized in production, manual work must be done to re-create the model’s original conditions. This can be incredible challenging (if not impossible) in most companies because changes may have occurred to the underlying data used to train the model, rendering it impossible to re-create that state.
The preferred approach, as shown in figure 16.3 , is to utilize a model registry service. MLflow, for instance, offers exactly this functionality within its APIs, allowing us to log details of each retraining run to the tracking server, handle production promotion if the scheduled retraining job performs better on holdout data, and archive the older model for future reference. If we had used this framework, the process of testing conditions of a model that had at one point run in production would be as simple as recalling the artifact from the registry entry, loading it into a notebook environment, and generating the explainable correlation reports with tools such as shap.
机器学习代考
计算机代写|机器学习代写machine learning代考|Artifact management
让我们想象一下,我们仍然在第15章介绍的森林服务部门的火灾风险部门工作。在我们努力有效地向公园系统的高风险区域派遣人员和设备的过程中,我们已经找到了一个非常有效的解决方案。随着时间的推移,我们的功能被锁定并保持稳定。我们已经评估了预测的表现,并从模型中看到了真正的价值。
在使特性进入良好状态的整个过程中,我们一直在迭代改进周期,如图16.1所示。
正如这个周期所示,我们一直在迭代地发布模型的新版本,针对基线部署进行测试,收集反馈,并努力改进预测。然而,在某种程度上,我们将进入模型维持模式。
我们已经尽我们所能地改进模型中的特性,并且发现继续向项目中添加新数据元素的投资回报(ROI)根本不值得。我们现在处于计划中的被动再训练位置,这是基于随着时间的推移输入的新数据。
当我们处于这个稳定状态点时,我们最不想做的事情就是让DS团队中的一个成员花一个下午的时间手动地重新训练模型,手动地将其结果与当前生产部署的模型进行特别分析比较,并决定是否应该更新模型。
计算机代写|机器学习代写machine learning代考|MLflow’s model registry
在我们发现自己所处的这种情况下,对模型的计划更新是自主发生的,因此了解生产部署的状态对我们来说非常重要。我们不仅需要知道当前状态,而且如果过去被动再训练系统的性能出现问题,我们需要有一种方法来调查模型的历史来源。图16.3比较了使用和不使用注册表跟踪来源的情况,以便解释历史问题。
正如你所看到的,试图重现过去的运行过程充满了危险;我们有很高的风险无法重现业务在历史预测中发现的问题。由于没有注册中心来记录生产中使用的工件,因此必须进行手工工作来重新创建模型的原始条件。在大多数公司中,这可能是一个难以置信的挑战(如果不是不可能的话),因为用于训练模型的底层数据可能已经发生了变化,使得无法重新创建该状态。
如图16.3所示,首选的方法是利用模型注册中心服务。例如,MLflow在其api中提供了这种功能,允许我们将每次再培训运行的详细信息记录到跟踪服务器,如果计划的再培训工作在保留数据上表现更好,则处理生产提升,并存档旧模型以供将来参考。如果我们使用了这个框架,那么在生产环境中运行的模型的测试过程就会非常简单,只需从注册表项中召回工件,将其加载到笔记本环境中,并使用诸如shape之类的工具生成可解释的相关报告。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。