如果你也在 怎样代写机器学习Machine Learning 这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。机器学习Machine Learning令人兴奋。这是有趣的,具有挑战性的,创造性的,和智力刺激。它还为公司赚钱,自主处理大量任务,并从那些宁愿做其他事情的人那里消除单调工作的繁重任务。
机器学习Machine Learning也非常复杂。从数千种算法、数百种开放源码包,以及需要具备从数据工程(DE)到高级统计分析和可视化等各种技能的专业实践者,ML专业实践者所需的工作确实令人生畏。增加这种复杂性的是,需要能够与广泛的专家、主题专家(sme)和业务单元组进行跨功能工作——就正在解决的问题的性质和ml支持的解决方案的输出进行沟通和协作。
statistics-lab™ 为您的留学生涯保驾护航 在代写机器学习 machine learning方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写机器学习 machine learning代写方面经验极为丰富,各种代写机器学习 machine learning相关的作业也就用不着说。
计算机代写|机器学习代写machine learning代考|Have you met your data?
What I mean by meeting isn’t the brief and polite nod of acknowledgment when passing your data on the way to refill your coffee. Nor is it the 30 -second rushed socially awkward introduction at a tradeshow meetup. Instead, the meeting that you should be having with your data is more like an hours-long private conversation in a quiet, wellfurnished speakeasy over a bottle of Macallan Rare Cask, sharing insights and delving into the nuances of what embodies the two of you as dram after silken dram caresses your digestive tracts: really and truly getting to know it.
TIP Before writing a single line of code, even for experimentation, make sure you have the data needed to answer the basic nature of the problem in the simplest way possible (an if/else statement). If you don’t have it, see if you can get it. If you can’t get it, move on to something you can solve.
As an example of the dangers of a mere passing casual rendezvous with data being used for problem solving, let’s pretend that we both work at a content provider company. Because of the nature of the business model at our little company, our content is listed on the internet behind a timed paywall. For the first few articles that are read, no ads are shown, content is free to view, and the interaction experience is bereft of interruptions. After a set number of articles, an increasingly obnoxious series of pop-ups and disruptions are presented to coerce a subscription registration from the reader.
The prior state of the system was set by a basic heuristic controlled through the counting of article pages that the end user had seen. Realizing that this would potentially be off-putting for someone browsing during their first session on the platform, this was then adjusted to look at session length and an estimate of how many lines of each article had been read. As time went on, this seemingly simple rule set became so unwieldy and complex that the web team asked our DS team to build something that could predict on a per-user level the type and frequency of disruptions that would maximize subscription rates.
We spend a few months, mostly using the prior work that was built to support the heuristics approach, having the data engineering team create mirrored ETL processes of the data structures and manipulation logic that the frontend team has been using to generate decision data. With the data available in the data lake, we proceed to build a highly effective and accurate model that seems to perform exceptionally well on all of our holdout tests.
计算机代写|机器学习代写machine learning代考|Make sure you have the data
This example might seem a bit silly, but I’ve seen this situation play out dozens of times. Having an inability to get at the right data for model serving is a common problem.
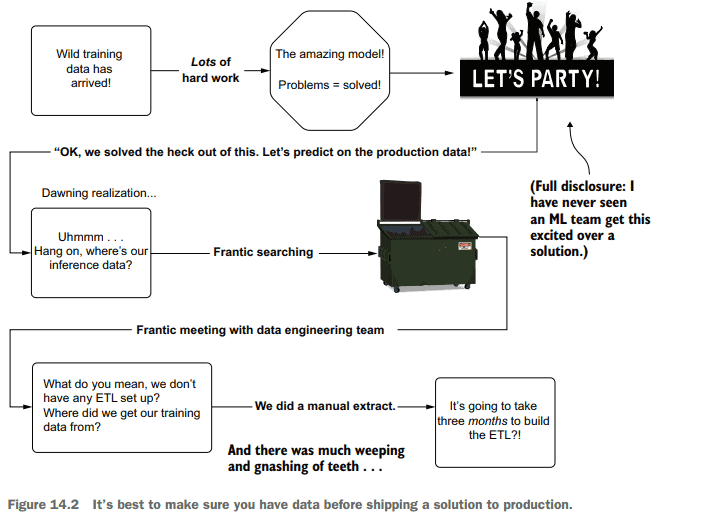
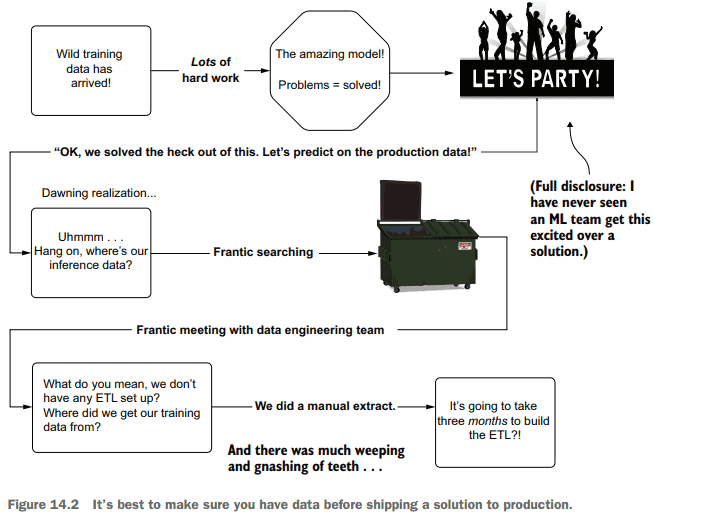
I’ve seen teams work with a manually extracted dataset (a one-time extract), build a truly remarkable solution with that data, and when ready to release the project to production, realize at the 11 th hour that the process for building that one-time extract required entirely manual actions by a DE team. The necessary data to make the solution effective was siloed off in a production infrastructure that the DS and DE teams had no ability to access. Figure 14.2 shows a rather familiar sight that I’ve borne witness to far too many times.
With no infrastructure present to bring the data into a usable form for predictions, as shown in figure 14.2, an entire project needs to be created for the DE team to build the ETL needed to materialize the data in a scheduled manner. Depending on the complexity of the data sources, this could take a while. Building hardened productiongrade ETL jobs that pull from multiple production relational databases and in-memory key-value stores is not a trivial reconciliation act, after all. Delays like this could lead (and have led) to project abandonment, regardless of the predictive capabilities of the DS portion of the solution.
This problem of complex ETL job creation becomes even more challenging if the predictions need to be conducted online. At that point, it’s not a question of the DE team working to get ETL processes running; rather, disparate groups in the engineering organization will have to accumulate the data into a single place in order to generate the collection of attributes that can be fed into a REST API request to the ML service.
This entire problem is solvable, though. During the time of EDA, the DS team should be evaluating the nature of the data generation, asking pointed questions to the data warehousing team:
- Can the data be condensed to the fewest possible tables to reduce costs?
-What is the team’s priority for fixing these sources if something breaks down? - Can I access this data from both the training and serving layers?
-Will querying this data for serving meet the project SLA?
机器学习代考
计算机代写|机器学习代写machine learning代考|Have you met your data?
我所说的会面,并不是在你传递数据、去续杯咖啡的路上,简短而礼貌地点头致意。也不是在展会上匆忙的30秒尴尬的自我介绍。相反,你应该与你的数据进行的会议更像是在一个安静、设备完善的地下酒吧里,喝着一瓶麦卡伦稀有酒桶(Macallan Rare Cask),进行长达数小时的私人谈话,分享见解,深入研究体现你们两人的细微差别,就像一杯又一杯柔滑的威士忌抚摸着你的消化道:真正真正地了解它。
提示:在编写一行代码之前,即使是为了进行实验,也要确保您拥有以最简单的方式(if/else语句)回答问题的基本性质所需的数据。如果你没有,看看你能不能得到它。如果你不能得到它,那就转向你能解决的问题。
为了说明与用于解决问题的数据仅仅是偶然相遇的危险,让我们假设我们都在一家内容提供商公司工作。由于我们这个小公司的商业模式的性质,我们的内容是在互联网上按时间收费的。对于阅读的前几篇文章,没有广告显示,内容可以自由查看,并且交互体验没有中断。在读完一定数量的文章后,会出现一系列令人讨厌的弹出窗口和干扰,迫使读者注册订阅。
系统的先验状态由一个基本的启发式设置,该启发式通过计算最终用户看过的文章页数来控制。意识到这可能会让那些在平台上的第一次浏览期间浏览的人感到不快,然后调整到查看会话长度和每篇文章的阅读行数估计。随着时间的推移,这个看似简单的规则集变得如此笨拙和复杂,以至于网络团队要求我们的DS团队构建一些东西,可以在每个用户的层面上预测中断的类型和频率,从而最大化订阅率。
我们花了几个月的时间,主要是使用之前为支持启发式方法而构建的工作,让数据工程团队创建数据结构和操作逻辑的镜像ETL流程,前端团队一直使用这些流程来生成决策数据。有了数据湖中可用的数据,我们继续构建一个非常有效和准确的模型,该模型似乎在我们所有的holdout测试中都表现得非常好。
计算机代写|机器学习代写machine learning代考|Make sure you have the data
这个例子可能看起来有点傻,但我已经看到这种情况发生过几十次了。无法为模型服务获取正确的数据是一个常见的问题。
我见过一些团队使用手动提取的数据集(一次性提取),使用该数据构建真正出色的解决方案,并在准备将项目发布到生产环境时,在第11个小时意识到构建一次性提取的过程完全需要DE团队的手动操作。使解决方案有效的必要数据被隔离在生产基础设施中,DS和DE团队无法访问这些数据。图14.2显示了一个相当熟悉的场景,我已经见过太多次了。
如图14.2所示,由于没有基础设施将数据转换为可用于预测的形式,因此需要为DE团队创建一个完整的项目,以构建以预定方式实现数据所需的ETL。根据数据源的复杂性,这可能需要一段时间。毕竟,构建从多个生产关系数据库和内存中的键值存储中提取的坚固的生产级ETL作业并不是一个微不足道的协调行为。不管解决方案的DS部分的预测能力如何,像这样的延迟可能导致(并且已经导致)项目放弃。
如果预测需要在线进行,那么复杂的ETL创造就业机会的问题就变得更具挑战性。在这一点上,这不是DE团队努力使ETL进程运行的问题;相反,工程组织中的不同组必须将数据积累到一个地方,以便生成可以提供给ML服务的REST API请求的属性集合。
不过,整个问题是可以解决的。在EDA期间,DS团队应该评估数据生成的性质,向数据仓库团队提出尖锐的问题:
能否将数据压缩到尽可能少的表中以降低成本?
-如果有东西坏了,团队修复这些源的首要任务是什么?
我可以从训练层和服务层访问这些数据吗?
-为服务而查询这些数据是否符合项目SLA?

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。