计算机代写|机器学习代写machine learning代考|STAT3888
如果你也在 怎样代写机器学习Machine Learning 这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。机器学习Machine Learning令人兴奋。这是有趣的,具有挑战性的,创造性的,和智力刺激。它还为公司赚钱,自主处理大量任务,并从那些宁愿做其他事情的人那里消除单调工作的繁重任务。
机器学习Machine Learning也非常复杂。从数千种算法、数百种开放源码包,以及需要具备从数据工程(DE)到高级统计分析和可视化等各种技能的专业实践者,ML专业实践者所需的工作确实令人生畏。增加这种复杂性的是,需要能够与广泛的专家、主题专家(sme)和业务单元组进行跨功能工作——就正在解决的问题的性质和ml支持的解决方案的输出进行沟通和协作。
statistics-lab™ 为您的留学生涯保驾护航 在代写机器学习 machine learning方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写机器学习 machine learning代写方面经验极为丰富,各种代写机器学习 machine learning相关的作业也就用不着说。

计算机代写|机器学习代写machine learning代考|UCI Categorization
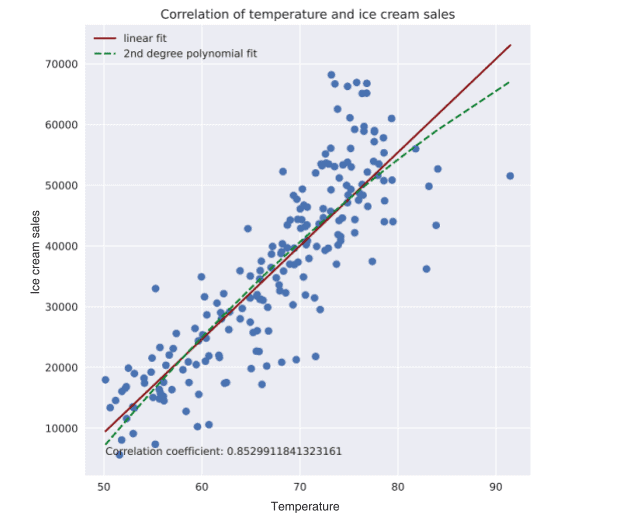
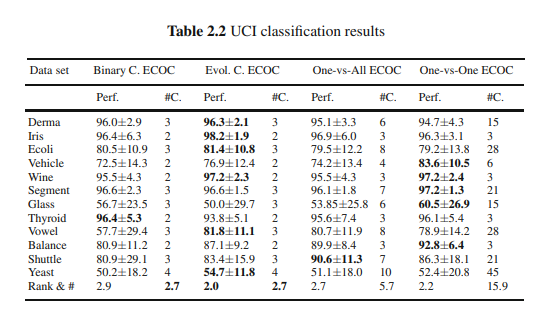
The classification results obtained for all the UCI data sets considering the different ECOC configurations are shown in Table 2.2. In order to compare the performances provided for each strategy, the table also shows the mean rank of each ECOC design considering the twelve different experiments. The rankings are obtained estimating each particular ranking $r_i^j$ for each problem $i$ and each ECOC configuration $j$, and computing the mean ranking $R$ for each design as $R_j=\frac{1}{N} \sum_i r_i^j$, where $N$ is the total number of data sets. We also show the mean number of classifiers (#) required for each strategy.
In order to analyze if the difference between ranks (and hence, the methods) is statistically significant, we apply a statistical test. In order to reject the null hypothesis (which implies no significant statistical difference among measured ranks and the mean rank), we use the Friedman test. The Friedman statistic value is computed as follows:
$$
X_F^2=\frac{12 N}{k(k+1)}\left[\sum_j R_j^2-\frac{k(k+1)^2}{4}\right] .
$$
In our case, with $k=4$ ECOC designs to compare, $X_F^2=-4.94$. Since this value is rather conservative, Iman and Davenport proposed a corrected statistic:
$$
F_F=\frac{(N-1) X_F^2}{N(k-1)-X_F^2}
$$
Applying this correction we obtain $F_F=-1.32$. With four methods and twelve experiments, $F_F$ is distributed according to the $F$ distribution with 3 and 33 degrees of freedom. The critical value of $F(3,33)$ for 0.05 is 2.89 . As the value of $F_F$ is no higher than 2.98 we can state that there is no statistically significant difference among the ECOC schemes. This means that all four strategies are suitable in order to deal with multi-class categorization problems. This result is very satisfactory and encourages the use of the compact approach since similar (or even better) results can be obtained with far less number of classifiers. Moreover, the GA evolutionary version of the compact design improves in the mean rank to the rest of classical coding strategies, and in most cases outperforms the binary compact approach in the present experiment. This result is expected since the evolutionary version looks for a compact ECOC matrix configuration that minimizes the error over the training data. In particular, the advantage of the evolutionary version over the binary one is more significant when the number of classes increases, since more compact matrices are available for optimization.
计算机代写|机器学习代写machine learning代考|Labelled Faces in the Wild Categorization
This dataset contains 13000 faces images taken directly from the web from over 1400 people. These images are not constrained in terms of pose, light, occlusions or any other relevant factor. For the purpose of this experiment we used a specific subset, taking only the categories which at least have four or more examples, having a total of 610 face categories. Finally, in order to extract relevant features from the images, we apply an Incremental Principal Component Analysis procedure [16], keeping $99.8 \%$ of the information. An example of face images is shown in Fig. 2.4.
The results in the first row of Table 2.3 show that the best performance is obtained by the Evolutionary GA and PBIL compact strategies. One important observation is that Evolutionary strategies outperform the classical one-versus-all approach, with far less number of classifiers (10 instead of 610). Note that in this case we omitted the one-vs-one strategy since it requires 185745 classifiers for discriminating 610 face categories.
For this second computer vision experiment, we use the video sequences obtained from the Mobile Mapping System of [1] to test the ECOC methodology on a real traffic sign categorization problem. In this system, the position and orientation of the different traffic signs are measured with video cameras fixed on a moving vehicle. The system has a stereo pair of calibrated cameras, which are synchronized with a GPS/INS system. The result of the acquisition step is a set of stereo-pairs of images with their position and orientation information. From this system, a set of 36 circular and triangular traffic sign classes are obtained. Some categories from this data set are shown in Fig. 2.5. The data set contains a total of 3481 samples of size $32 \times 32$, filtered using the Weickert anisotropic filter, masked to exclude the background pixels, and equalized to prevent the effects of illumination changes. These feature vectors are then projected into a 100 feature vector by means of PCA.
The classification results obtained when considering the different ECOC configurations are shown in the second row of Table 2.3. The ECOC designs obtain similar classification results with an accuracy of over $90 \%$. However, note that the compact methodologies use six times less classifiers than the one-versus-all and 105 less times classifiers than the one-versus-one approach, respectively.
机器学习代考
计算机代写|机器学习代写machine learning代考|UCI Categorization
考虑不同ECOC配置的所有UCI数据集的分类结果如表2.2所示。为了比较每种策略提供的性能,下表还显示了考虑到12种不同实验的每种ECOC设计的平均排名。通过估计每个问题$i$和每个ECOC配置$j$的每个特定排名$r_i^j$得到排名,并计算每个设计的平均排名$R$为$R_j=\frac{1}{N} \sum_i r_i^j$,其中$N$为数据集的总数。我们还展示了每种策略所需的分类器的平均数量(#)。
为了分析等级之间的差异(以及方法之间的差异)是否具有统计显著性,我们应用了统计检验。为了拒绝零假设(这意味着测量秩和平均秩之间没有显著的统计差异),我们使用弗里德曼检验。弗里德曼统计值计算公式如下:
$$
X_F^2=\frac{12 N}{k(k+1)}\left[\sum_j R_j^2-\frac{k(k+1)^2}{4}\right] .
$$
在我们的案例中,与$k=4$ ECOC设计进行比较,$X_F^2=-4.94$。由于这个值相当保守,Iman和Davenport提出了一个修正后的统计:
$$
F_F=\frac{(N-1) X_F^2}{N(k-1)-X_F^2}
$$
应用这个修正,我们得到$F_F=-1.32$。通过4种方法和12个实验,$F_F$按照$F$的3自由度和33自由度分布进行分布。$F(3,33)$对0.05的临界值为2.89。由于$F_F$的值不大于2.98,我们可以认为ECOC方案之间没有统计学上的显著差异。这意味着这四种策略都适用于处理多类分类问题。这个结果非常令人满意,并鼓励使用紧凑方法,因为使用更少的分类器可以获得类似(甚至更好)的结果。此外,遗传进化版本的紧凑设计在平均秩上优于其他经典编码策略,并且在大多数情况下优于本实验中的二进制紧凑方法。这个结果是预期的,因为进化版本寻找一个紧凑的ECOC矩阵配置,使训练数据上的误差最小化。特别是,当类的数量增加时,进化版本相对于二进制版本的优势更加显著,因为可以使用更紧凑的矩阵进行优化。
计算机代写|机器学习代写machine learning代考|Labelled Faces in the Wild Categorization
该数据集包含13000张直接从网络上取自1400多人的人脸图像。这些图像不受姿势、光线、遮挡或任何其他相关因素的限制。为了这个实验的目的,我们使用了一个特定的子集,只取至少有四个或更多例子的类别,总共有610个面部类别。最后,为了从图像中提取相关特征,我们应用增量主成分分析程序[16],保留99.8%的信息。一个人脸图像的例子如图2.4所示。
表2.3第一行的结果表明,进化遗传算法和PBIL压缩策略的性能最好。一个重要的观察结果是,进化策略优于经典的“一对全”方法,它的分类器数量要少得多(10个而不是610个)。注意,在这种情况下,我们省略了一对一策略,因为它需要185745个分类器来区分610个人脸类别。
对于第二个计算机视觉实验,我们使用从[1]的移动地图系统获得的视频序列来测试ECOC方法在实际交通标志分类问题上的应用。在这个系统中,不同的交通标志的位置和方向是通过固定在移动车辆上的摄像机来测量的。该系统有一对立体校准相机,与GPS/INS系统同步。采集步骤的结果是一组具有位置和方向信息的立体图像对。从这个系统中,得到了一组36个圆形和三角形交通标志类。该数据集中的一些类别如图2.5所示。该数据集共包含3481个大小为$32 × 32$的样本,使用Weickert各向异性滤波器进行滤波,屏蔽以排除背景像素,并进行均衡以防止光照变化的影响。然后通过PCA将这些特征向量投影成100个特征向量。
考虑不同ECOC配置得到的分类结果如表2.3第二行所示。ECOC设计获得了类似的分类结果,准确率超过90%。但是,请注意,紧凑方法使用的分类器比单对全方法少6倍,比单对一方法少105倍。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。