如果你也在 怎样代写机器学习Machine Learning 这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。机器学习Machine Learning令人兴奋。这是有趣的,具有挑战性的,创造性的,和智力刺激。它还为公司赚钱,自主处理大量任务,并从那些宁愿做其他事情的人那里消除单调工作的繁重任务。
机器学习Machine Learning也非常复杂。从数千种算法、数百种开放源码包,以及需要具备从数据工程(DE)到高级统计分析和可视化等各种技能的专业实践者,ML专业实践者所需的工作确实令人生畏。增加这种复杂性的是,需要能够与广泛的专家、主题专家(sme)和业务单元组进行跨功能工作——就正在解决的问题的性质和ml支持的解决方案的输出进行沟通和协作。
statistics-lab™ 为您的留学生涯保驾护航 在代写机器学习 machine learning方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写机器学习 machine learning代写方面经验极为丰富,各种代写机器学习 machine learning相关的作业也就用不着说。
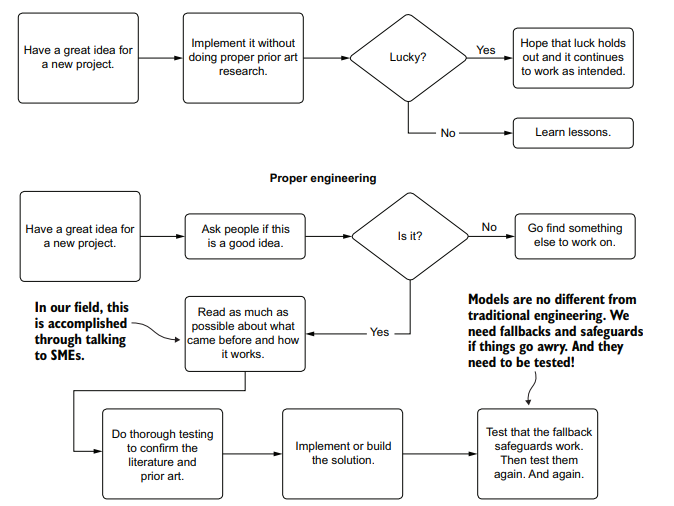
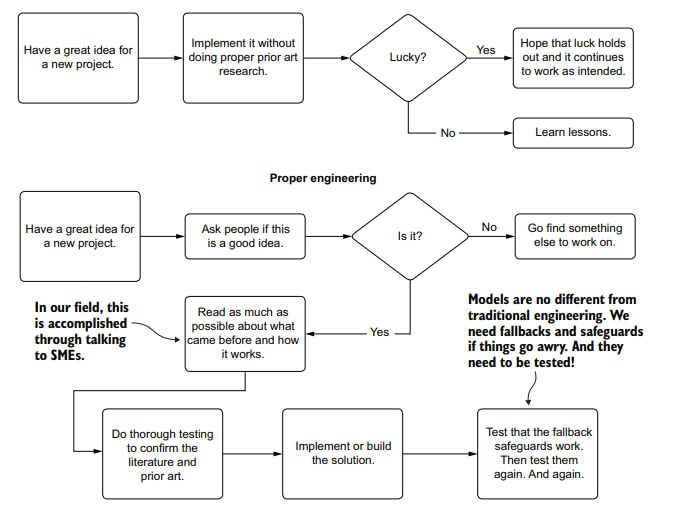
计算机代写|机器学习代写machine learning代考|Leaning heavily on prior art
We could use nearly any of the comical examples from table 15.1 to illustrate the first rule in creating fallback plans. Instead, let’s use an actual example from my own personal history.
I once worked on a project that had to deal with a manufacturing recipe. The goal of this recipe was to set a rotation speed on a ludicrously expensive piece of equipment while a material was dripped onto it. The speed of this unit needed to be adjusted periodically throughout the day as the temperature and humidity changed the viscosity of the material being dripped onto the product. Keeping this piece of equipment running optimally was my job; there were many dozens of these stations in the machine and many types of chemicals.
As in so many times in my career, I got really tired of doing a repetitive task. I figured there had to be some way to automate the spin speed of these units so I wouldn’t have to stand at the control station and adjust them every hour or so. Thinking myself rather clever, I wired up a few sensors to a microcontroller, programmed the programmable logic controller to receive the inputs from my little controller, wrote a simple program that would adjust the chuck speed according to the temperature and humidity in the room, and activated the system.
Everything went well, I thought, for the first few hours. I had programmed a simple regression formula into the microcontroller, checked my math, and even tested it on an otherwise broken piece of equipment. It all seemed pretty solid.
It wasn’t until around 3 a.m. that my pager (yes, it was that long ago) started going off. By the time I made it to the factory 20 minutes later, I realized that I had caused an overspeed condition in every single spin chuck system. They stopped. The rest of the liquid dosing system did not. As the chilly breeze struck the back of my head, and I looked out at the open bay doors letting in the $27^{\circ} \mathrm{F}$ night air, I realized my error.
I didn’t have a fallback condition. The regression line, taking in the ambient temperature, tried to compensate for the untested range of data (the viscosity curve wasn’t actually linear at that range), and took a chuck that normally rotated at around 2,800 RPM and tried to instruct it to spin at 15,000 RPM.
I spent the next four days and three nights cleaning up lacquer from the inside of that machine. By the time I was finished, the lead engineer took me aside and handed me a massive three-ring binder and told me to “read it before playing any more games.” (I’m paraphrasing. I can’t put into print what he said to me.) The book was filled with the materials science analysis of each chemical that the machine was using. It had the exact viscosity curves that I could have used. It had information on maximum spin speeds for deposition.
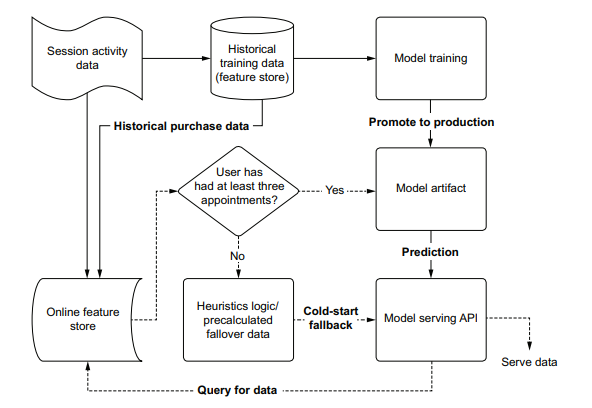
计算机代写|机器学习代写machine learning代考|Cold-start woes
For certain types of ML projects, model prediction failures are not only frequent, but also expected. For solutions that require a historical context of existing data to function properly, the absence of historical data prevents the model from making a prediction. The data simply isn’t available to pass through the model. Known as the cold-start problem, this is a critical aspect of solution design and architecture for any project dealing with temporally associated data.
As an example, let’s imagine that we run a dog-grooming business. Our fleets of mobile bathing stations scour the suburbs of North America, offering all manner of services to dogs at their homes. Appointments and service selection is handled through an app interface. When booking a visit, the clients select from hundreds of options and prepay for the services through the app no later than a day before the visit.
To increase our customers’ satisfaction (and increase our revenue), we employ a service recommendation interface on the app. This model queries the customer’s historical visits, finds products that might be relevant for them, and indicates additional services that the dog might enjoy. For this recommender to function correctly, the historical services history needs to be present during service selection.
This isn’t much of a stretch for anyone to conceptualize. A model without data to process isn’t particularly useful. With no history available, the model clearly has no data in which to infer additional services that could be recommended for bundling into the appointment.
What’s needed to serve something to the end user is a cold-start solution. An easy implementation for this use case is to generate a collection of the most frequently ordered services globally. If the model doesn’t have enough data to provide a prediction, this popularity-based services aggregation can be served in its place. At that point, the app IFrame element will at least have something in it (instead of showing an empty collection) and the user experience won’t be broken by seeing an empty box.
机器学习代考
计算机代写|机器学习代写machine learning代考|Leaning heavily on prior art
我们几乎可以使用表15.1中的任何一个有趣的例子来说明创建后备计划的第一条规则。相反,让我们用我个人经历中的一个实际例子。
我曾经做过一个项目,必须处理一个制造配方。这个配方的目标是在一个昂贵得离谱的设备上设定一个旋转速度,同时把一种材料滴在上面。该装置的速度需要在一天中周期性地调整,因为温度和湿度改变了被滴到产品上的材料的粘度。保持这台设备的最佳运行状态是我的工作;机器里有几十个这样的工作站和许多种类的化学品。
在我的职业生涯中有很多次,我真的厌倦了做重复的工作。我想一定有某种方法可以自动控制这些装置的旋转速度,这样我就不必站在控制站,每隔一小时左右就调整一次。我觉得自己很聪明,于是在一个微控制器上安装了几个传感器,给可编程逻辑控制器编程,让它接收来自我的小控制器的输入,然后写了一个简单的程序,根据房间里的温度和湿度来调整卡盘的速度,然后启动了系统。
我想,在最初的几个小时里,一切都很顺利。我在微控制器中编写了一个简单的回归公式,检查了我的数学计算,甚至在一个坏掉的设备上进行了测试。一切似乎都很可靠。
直到凌晨3点左右,我的呼机才开始响(是的,那是很久以前的事了)。20分钟后,当我到达工厂时,我意识到我已经在每个旋转卡盘系统中造成了超速状态。他们停止了。液体加药系统的其余部分没有。当冷风吹过我的后脑勺时,我望着敞开的门,让27美元的夜晚空气进来,我意识到自己的错误。
我没有退路。回复线考虑了环境温度,试图补偿未测试的数据范围(粘度曲线在该范围内实际上不是线性的),并选择了一个通常以2800转/分左右旋转的卡盘,并试图指示它以15,000转/分旋转。
接下来的四天三夜我都在清理机器里面的漆。当我完成游戏时,首席工程师把我叫到一边,递给我一个巨大的三环活页夹,并告诉我“在继续玩游戏之前先阅读它。”(我套用。我不能把他对我说的话付梓。)这本书里写满了机器所使用的每种化学物质的材料科学分析。它有我可以用的粘度曲线。它有关于沉积的最大旋转速度的信息。
计算机代写|机器学习代写machine learning代考|Cold-start woes
对于某些类型的ML项目,模型预测失败不仅频繁,而且是意料之中的。对于需要现有数据的历史上下文才能正常工作的解决方案,缺少历史数据会阻止模型进行预测。数据根本无法通过模型。这被称为冷启动问题,对于任何处理临时关联数据的项目来说,这是解决方案设计和体系结构的一个关键方面。
举个例子,假设我们经营一家狗狗美容公司。我们的移动洗浴站遍布北美郊区,为狗狗提供各种上门服务。约会和服务选择是通过应用程序界面处理的。当预约参观时,客户可以从数百个选项中进行选择,并在参观前一天通过应用程序预付服务费用。
为了提高客户的满意度(并增加我们的收入),我们在应用程序上使用了一个服务推荐界面。这个模型会查询客户的历史访问记录,找到可能与他们相关的产品,并指出狗可能喜欢的其他服务。要使此推荐程序正确运行,在服务选择期间需要提供历史服务历史。
这对任何人来说都不是很容易理解的。没有数据要处理的模型并不是特别有用。由于没有可用的历史记录,该模型显然没有数据来推断可以推荐绑定到约会中的其他服务。
为最终用户提供服务所需要的是冷启动解决方案。此用例的一个简单实现是生成全局最频繁订购的服务的集合。如果模型没有足够的数据来提供预测,则可以使用这种基于流行度的服务聚合。在这一点上,应用程序的IFrame元素至少会有一些东西在里面(而不是显示一个空的集合),用户体验不会因为看到一个空框而被破坏。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。