机器人代写|SLAM代写机器人导航代考|Log FastSLAM
如果你也在 怎样代写SLAM这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
同步定位和测绘(SLAM)是构建或更新一个未知环境的地图,同时跟踪一个代理人在其中的位置的计算问题。虽然这最初似乎是一个鸡生蛋蛋生鸡的问题,但有几种已知的算法可以解决这个问题,至少是近似解决,在某些环境下是可行的。流行的近似解决方法包括粒子过滤器、扩展卡尔曼过滤器、协方差交叉和GraphSLAM。SLAM算法是基于计算几何和计算机视觉的概念,并被用于机器人导航、机器人测绘和虚拟现实或增强现实的里程测量。
statistics-lab™ 为您的留学生涯保驾护航 在代写SLAM方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写SLAM代写方面经验极为丰富,各种代写SLAM相关的作业也就用不着说。
我们提供的SLAM及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
机器人代写|SLAM代写机器人导航代考|Log FastSLAM
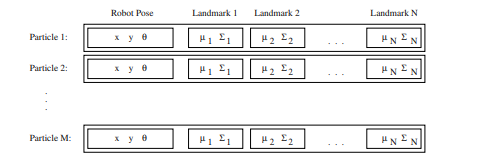
The computational complexity of the FastSLAM algorithm presented up to this point requires time $O(M, N)$ where $M$ is the number of particles, and $N$ is the number of landmarks in the map. The linear complexity in $M$ is unavoidable, given that we have to process $M$ particles for every update. This linear complexity in $N$ is due to the importance resampling step in Section 3.3.4. Since the sampling is done with replacement, a single particle in the weighted particle set may be duplicated several times in $S_{t}$. The simplest way to implement this is to repeatedly copy the entire particle into the new particle set. Since the length of the particles depends linearly on $N$, this copying operation is also linear in the size of the map.
The wholesale copying of particles from the old set into the new set is an overly conservative approach. The majority of the landmark filters remain unchanged at every time step. Indeed, since the sampling is done with replacement, many of the landmark filters will be completely identical.
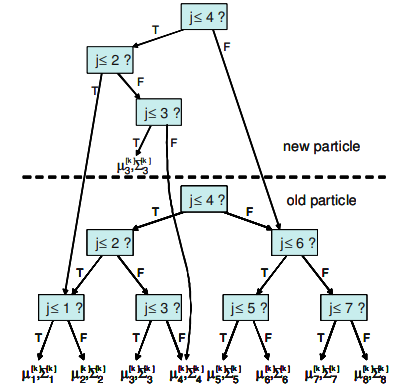
These observations suggest that with proper bookkeeping, a more efficient particle representation might allow duplicate landmark filters to be shared between particles, resulting in a more efficient implementation of FastSLAM. This can be done by changing the particle representation from an array of landmark filters to a binary tree. An example landmark tree is shown in Figure $3.11$ for a map with eight landmarks. In the figure, the landmarks are organized by an arbitrary landmark number $K$. In situations in which data association is unknown, the tree could be organized spatially as in a k-d tree.
Note that the landmark parameters $\mu_{n}, \Sigma_{n}$ are located at the leaves of the tree. Each non-leaf node in the tree contains pointers to up to two subtrees. Any subtree can be shared between multiple particles’ landmark trees. Sharing subtrees makes the update procedure more complicated to implement, but results in a tremendous savings in both memory and computation. Assuming that the tree is balanced, accessing a leaf requires a binary search, which will take $\log (N)$ time, on average.
The $\log (N)$ FastSLAM algorithm can be illustrated by tracing the effect of a control and an observation on the landmark trees. Each new particle in $S_{t}$ will differ from its generating particle in $S_{t-1}$ in two ways. First, each will posses a different pose estimate from (3.17), and second, the observed feature’s Gaussian will be updated as specified in (3.29)-(3.34). All other Gaussians will be equivalent to the generating particle. Thus, when copying the particle to $S_{t}$, only a single path from the root of the tree to the updated Gaussian needs to be duplicated. The length of this path is logarithmic in $N$, on average.
An example is shown in Figure $3.12$. Here we assume that $n_{t}=3$, that is, only the landmark Gaussian parameters $\mu_{3}^{[m]}, \Sigma_{3}^{[m]}$ are updated. Instead of duplicating the entire tree, a single path is duplicated, from the root to the third Gaussian. This path is an incomplete tree. The tree is completed by copying the missing pointers from the tree of the generating particle. Thus, branches that leave the modified path will point to the unmodified subtrees of the generating particle. Clearly, generating this modified tree takes time logarithmic in $N$. Moreover, accessing a Gaussian also takes time logarithmic in $N$, since the number of steps required to navigate to a leaf of the tree is equivalent to the length of the path. Thus, both generating and accessing a partial tree can be done in time $O(\log N)$. $M$ new particles are generated at every update step, so the resulting FastSLAM algorithm requires time $O(M \log N)$.
机器人代写|SLAM代写机器人导航代考|Garbage Collection
Organizing particles as binary trees naturally raises the question of garbage collection. Subtrees are constantly being shared and split between particles. When a subtree is no longer referenced as a part of any particle description,
the memory allocated to this subtree must be freed. Otherwise, the memory required by FastSLAM will grow without bound.
Whenever landmarks are shared between particles, the shared landmarks always form complete subtrees. In other words, if a particular node of the landmark tree is shared between multiple particles, all of the nodes descendants will also be shared. This greatly simplifies garbage collection in FastSLAM, because the landmark trees can be freed recursively.
Garbage collection in FastSLAM can be implemented using reference counts attached to each node in the landmark tree. Each counter counts the number of times the given node is pointed to by other nodes. A newly created node, for example, receives a reference count of 1 . When a new reference is made to a node, the reference count is incremented. When a link is removed, the reference count is decremented. If the reference count reaches zero, the reference counts of the node’s children are decreased, and the node’s memory is freed. This process is then applied recursively to all children of the node with a zero reference count. This process will require $O(M \log N)$ time on average. Furthermore, it is an optimal deallocation algorithm, in that all unneeded memory is freed immediately when it is no longer referenced.
机器人代写|SLAM代写机器人导航代考|Victoria Park
The FastSLAM algorithm was tested on a benchmark SLAM data set from the University of Sydney [37]. An instrumented vehicle, shown in Figure 3.13, equipped with a laser range finder was repeatedly driven through Victoria Park, in Sydney, Australia. Victoria Park is an ideal setting for testing SLAM algorithms because the park’s trees are distinctive features in the robot’s laser scans. Encoders measured the vehicle’s velocity and steering angle. Range and bearing measurements to nearby trees were extracted from the laser data using a local minima detector. The vehicle was driven around for approximately 30 minutes, covering a distance of over $4 \mathrm{~km}$. The vehicle is also equipped with GPS in order to capture ground truth data. Due to occlusion by foliage and buildings, ground truth data is only available for part of the overall traverse. While ground truth is available for the robot’s path, no ground truth data is available for the locations of the landmarks.
Since the robot is driving over uneven terrain, the measured controls are fairly noisy. Figure $3.14$ (a) shows the path of the robot obtained by integrating the estimated controls. After 30 minutes of driving, the estimated position of the robot is well over 100 meters away from its true position measured by GPS. The laser data, on the other hand, is a very accurate measure of range and bearing. However, not all objects in the robot’s field of view are trees, or even static objects. As a result, the feature detector produced relatively accurate observations of trees, but also generated frequent outliers.
Data association for this experiment was done using per-particle ML data association. Since the accuracy of the observations is high relative to the average density of landmarks, data association in the Victoria Park data set is a relatively straightforward problem. In a later experiment, more difficult data association problems will be simulated by adding extra control noise.
The output of FastSLAM is shown in Figure $3.14(\mathrm{~b})$ and (c). The GPS path is shown as a dashed line, and the output of FastSLAM is shown as a solid line. The RMS error of the resulting path is just over 4 meters over the $4 \mathrm{~km}$ traverse. This experiment was run with 100 particles.
SLAM代写
机器人代写|SLAM代写机器人导航代考|Log FastSLAM
至此提出的 FastSLAM 算法的计算复杂度需要时间这(米,ñ)在哪里米是粒子数,和ñ是地图中地标的数量。线性复杂度米是不可避免的,因为我们必须处理米每次更新的粒子。这种线性复杂度在ñ是由于第 3.3.4 节中的重要性重采样步骤。由于采样是通过替换完成的,因此加权粒子集中的单个粒子可能会在小号吨. 实现这一点的最简单方法是将整个粒子重复复制到新粒子集中。由于粒子的长度线性地取决于ñ,这个复制操作在地图大小上也是线性的。
将旧集合中的粒子批量复制到新集合中是一种过于保守的方法。大多数地标过滤器在每个时间步都保持不变。实际上,由于采样是通过替换完成的,因此许多地标过滤器将完全相同。
这些观察表明,通过适当的簿记,更有效的粒子表示可能允许在粒子之间共享重复的界标过滤器,从而更有效地实现 FastSLAM。这可以通过将粒子表示从地标过滤器数组更改为二叉树来完成。一个示例地标树如图所示3.11一张有八个地标的地图。在图中,地标由任意地标编号组织ķ. 在数据关联未知的情况下,可以像在 kd 树中一样在空间上组织树。
注意地标参数μn,Σn位于树的叶子上。树中的每个非叶节点都包含指向最多两个子树的指针。任何子树都可以在多个粒子的界标树之间共享。共享子树使更新过程的实现更加复杂,但会极大地节省内存和计算量。假设树是平衡的,访问叶子需要二分查找,这将花费日志(ñ)时间,平均而言。
这日志(ñ)FastSLAM 算法可以通过跟踪控制和观察对地标树的影响来说明。每个新粒子小号吨将不同于它的生成粒子小号吨−1有两种方式。首先,每个都将拥有与(3.17)不同的姿态估计,其次,观察到的特征的高斯将按照(3.29)-(3.34)中的规定进行更新。所有其他高斯将等价于生成粒子。因此,当将粒子复制到小号吨,只需要复制从树根到更新的高斯的单个路径。这条路径的长度是对数的ñ, 一般。
一个例子如图所示3.12. 这里我们假设n吨=3,即只有地标高斯参数μ3[米],Σ3[米]被更新。不是复制整个树,而是复制一条路径,从根到第三个高斯。这条路径是一棵不完整的树。通过从生成粒子的树中复制丢失的指针来完成树。因此,离开修改路径的分支将指向生成粒子的未修改子树。显然,生成这个修改过的树需要对数时间ñ. 此外,访问高斯也需要时间对数ñ,因为导航到树的叶子所需的步数等于路径的长度。因此,生成和访问部分树都可以及时完成这(日志ñ). 米每个更新步骤都会生成新粒子,因此生成的 FastSLAM 算法需要时间这(米日志ñ).
机器人代写|SLAM代写机器人导航代考|Garbage Collection
将粒子组织为二叉树自然会引发垃圾收集的问题。子树在粒子之间不断地被共享和分裂。当一个子树不再作为任何粒子描述的一部分被引用时,
必须释放分配给该子树的内存。否则,FastSLAM 所需的内存将无限增长。
每当粒子之间共享界标时,共享界标总是形成完整的子树。换句话说,如果地标树的特定节点在多个粒子之间共享,则所有节点的后代也将被共享。这极大地简化了 FastSLAM 中的垃圾收集,因为可以递归地释放地标树。
FastSLAM 中的垃圾收集可以使用附加到地标树中每个节点的引用计数来实现。每个计数器计算给定节点被其他节点指向的次数。例如,一个新创建的节点接收到的引用计数为 1 。当对节点进行新引用时,引用计数会增加。删除链接时,引用计数会减少。如果引用计数达到零,则该节点的子节点的引用计数减少,并且该节点的内存被释放。然后将此过程递归地应用于具有零引用计数的节点的所有子节点。这个过程将需要这(米日志ñ)平均时间。此外,它是一种最佳的释放算法,因为所有不需要的内存在不再被引用时都会立即释放。
机器人代写|SLAM代写机器人导航代考|Victoria Park
FastSLAM 算法在悉尼大学的基准 SLAM 数据集上进行了测试 [37]。如图 3.13 所示,配备激光测距仪的仪表车辆反复驶过澳大利亚悉尼的维多利亚公园。维多利亚公园是测试 SLAM 算法的理想场所,因为公园的树木是机器人激光扫描的独特特征。编码器测量车辆的速度和转向角。使用局部最小值检测器从激光数据中提取到附近树木的距离和方位测量值。车辆行驶了大约 30 分钟,行驶距离超过4 ķ米. 该车辆还配备了 GPS 以捕获地面实况数据。由于树叶和建筑物的遮挡,地面实况数据仅可用于整个遍历的一部分。虽然地面实况可用于机器人的路径,但没有地面实况数据可用于地标的位置。
由于机器人在不平坦的地形上行驶,因此测量的控制噪声很大。数字3.14(a) 显示了通过集成估计控制获得的机器人路径。行驶 30 分钟后,机器人的估计位置与 GPS 测得的真实位置相差 100 多米。另一方面,激光数据是对距离和方位的非常准确的测量。然而,并非机器人视野中的所有物体都是树木,甚至是静态物体。结果,特征检测器产生了相对准确的树木观察结果,但也产生了频繁的异常值。
该实验的数据关联是使用每粒子 ML 数据关联完成的。由于观测的准确性相对于地标的平均密度较高,因此维多利亚公园数据集中的数据关联是一个相对简单的问题。在以后的实验中,将通过添加额外的控制噪声来模拟更困难的数据关联问题。
FastSLAM的输出如图3.14( b)(c)。GPS路径显示为虚线,FastSLAM的输出显示为实线。所得路径的 RMS 误差仅超过 4 米。4 ķ米遍历。该实验使用 100 个粒子进行。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。