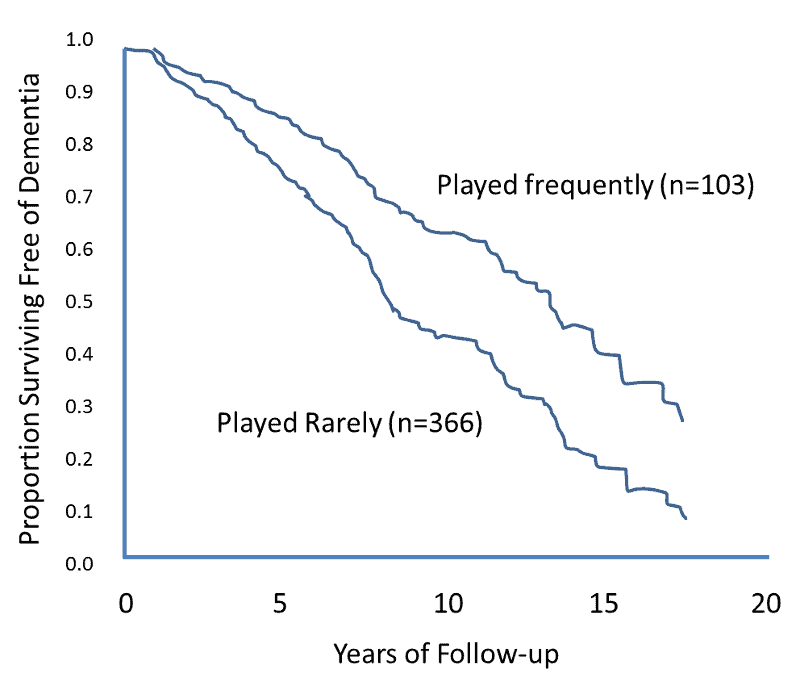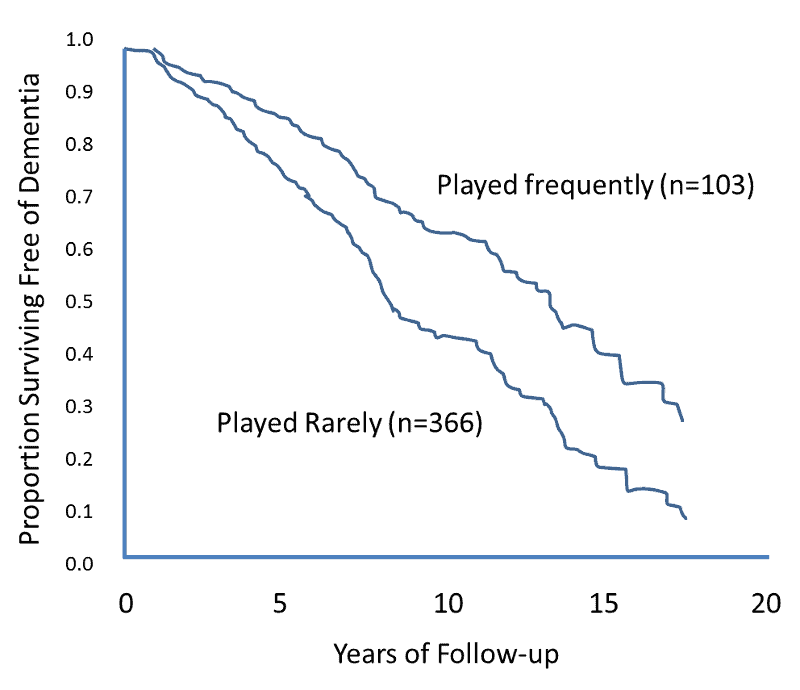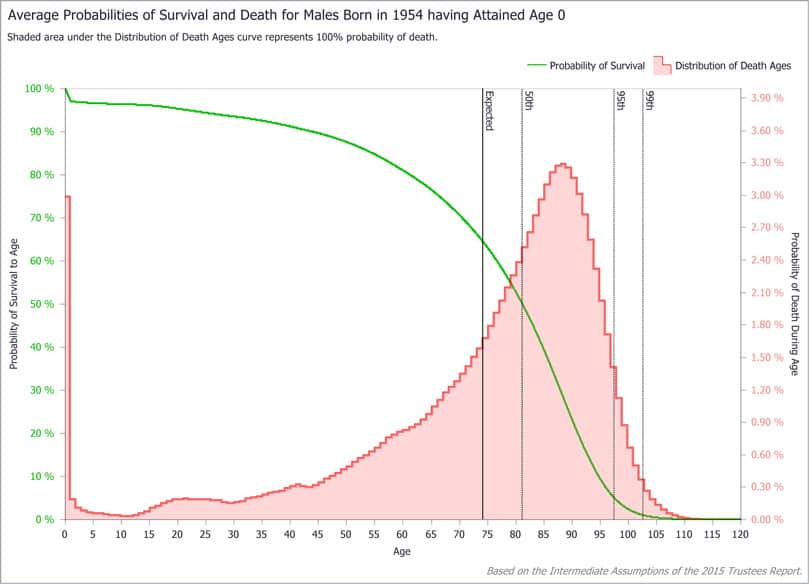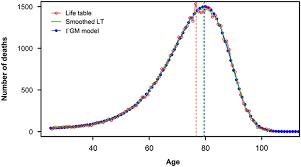
统计代写|生存模型代写survival model代考|STA628
如果你也在 怎样代写生存模型Survival Models这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。生存模型Survival Models在许多可用于分析事件时间数据的模型中,有4个是最突出的:Kaplan Meier模型、指数模型、Weibull模型和Cox比例风险模型。
生存模型Survival Models精算师和其他应用数学家使用预测人类或其他实体(有生命或无生命)生存模式的模型,并经常使用这些模型作为相当重要的财务计算的基础。具体来说,精算师使用这些模型来计算与个人人寿保险单、养老金计划和收入损失保险相关的财务价值。人口统计学家和其他社会科学家使用生存模型对该模型适用的人口的未来构成做出预测。
statistics-lab™ 为您的留学生涯保驾护航 在代写生存模型survival model方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写生存模型survival model代写方面经验极为丰富,各种代写生存模型survival model相关的作业也就用不着说。
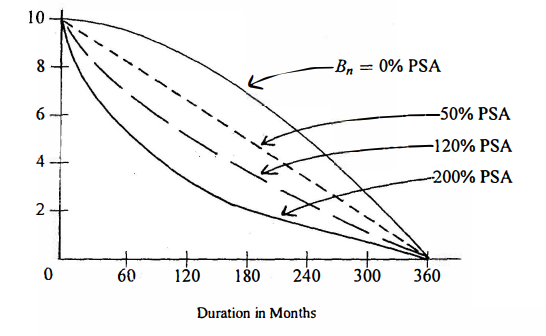
统计代写|生存模型代写survival model代考|Historical Approaches to Measuring Default Rates
The accurate measurement of the default risk is critical in the pricing of debt, measuring bond performance, and assessing bond market efficiency.
Early measurement approaches calculated the default rate in a particular year of a bond’s term by dividing the value of defaults by the original value of the bond issue, rather than by the surviving population of bonds at time of default. (The actuarial reader will recognize the former measure as an unconditional one, analogous to the life table concept denoted by ${ }_n \mid q_0$, and the latter measure as a conditional one, analogous to the life table concept denoted by $q_n$.) The former approach fails to consider that a bond can “die” in ways other than through default, such as by call redemption, sinking fund, or maturity. These annual default rates were then averaged over several years to obtain an average annual rate. For example, for the period 1978-87, the average annual default rate, measured in the traditional way, was $1.86 \%$ per year.
The traditional default rate measurement uses the par (or other) value of the defaulting bond in the numerator of the rate calculation. A more relevant measure for investors is not the rate of default, per se, but rather the rate of investment value actually lost (default loss rate measurement). Suppose an investor purchases a bond at par value. The bond defaults by failing to make a particular coupon payment, and the investor sells the bond immediately after the defaulted coupon date at $40 \%$ of its par value. Then the default loss rate calculation would use a loss of $60 \%$ of par plus one coupon in the numerator, whereas the traditional default rate calculation would use the entire par value. By taking into account that the defaulting bond can be sold, on the average, for about $40 \%$ of par, the 1978-87 average annual default loss rate was about $1.20 \%$ per year, compared to the $1.86 \%$ traditionally measured default rate.
统计代写|生存模型代写survival model代考|Altman ‘s BondMortality Rate Concept
As suggested in part (c) of Example 11.7, the “actuarial method” advocated by Altman tracks the survival pattern of a cohort group of bonds over time. In his model, bonds can exit from the original population by either default, calls, sinking funds, or maturities, so that we have a multiple-decrement environment. (To measure default rates, the non-default exits can be combined so that the model becomes double-decrement only.) Then if $D(t)$ denotes the value of defaulting debt in year $t$ and $P(t)$ denotes the value of the surviving population of bonds at the start of year $t$, then
$$
M M R_{\ell}=\frac{D(t)}{P(t)}
$$
gives the marginal mortality rate for year $t$.
Altman further defines
$$
S R_t=1-M M R_t
$$
to be the bond survival rate in year $t$, and
$$
C M R_t=1-\prod_{j=1}^t S R_j
$$
to be the cumulative mortality rate over the interval $(0, t)$.
Finally, Altman considers the mortality/survival experience of various classes of bonds over the seventeen-year sample period of 1971 through 1987. Since the values of $M M R_t$ were calculated at each duration $t$ for each separate issue year, then they must be combined to reach a rate for duration $t$ for the entire study. The combining is done on a value-weighted basis, since an unweighted average could be misleading if new issue amounts varied significantly from year to year. The reader interested in Altman’s numerical results is referred to [2].
生存模型代考
统计代写|生存模型代写survival model代考|Historical Approaches to Measuring Default Rates
准确衡量违约风险对于债券定价、衡量债券绩效和评估债券市场效率至关重要。
早期的衡量方法是通过将违约价值除以债券发行的原始价值来计算债券期限内特定年份的违约率,而不是用违约时幸存的债券数量来计算。(精算读者会认识到,前一个度量是无条件的度量,类似于用${ }_n \mid q_0$表示的生命表概念,后一个度量是有条件的度量,类似于用$q_n$表示的生命表概念。)前一种方法没有考虑到债券可以通过违约以外的方式“死亡”,例如赎回、偿债基金或到期。然后将这些年度违约率在几年内取平均值,以获得平均年利率。例如,在1978年至1987年期间,以传统方式衡量的平均年违约率为每年$1.86 \%$。
传统的违约率度量方法在利率计算的分子中使用违约债券的票面(或其他)值。对投资者来说,更相关的衡量标准不是违约率本身,而是投资价值实际损失的比率(违约损失率衡量标准)。假设投资者以票面价值购买债券。债券因未能支付特定的票息而违约,投资者在票息违约日期后立即以票面价值$40 \%$的价格出售债券。那么,违约损失率的计算将使用面值的损失$60 \%$加上一张息票作为分子,而传统的违约率计算将使用整个面值。考虑到违约债券的平均售价约为面值的$40 \%$, 1978-87年的平均年违约损失率约为每年$1.20 \%$,而传统上衡量的违约率为$1.86 \%$。
统计代写|生存模型代写survival model代考|Altman ‘s BondMortality Rate Concept
如例11.7 (c)部分所示,Altman提倡的“精算方法”跟踪一组债券的长期生存模式。在他的模型中,债券可以通过违约、赎回、偿债基金或到期退出原始人口,因此我们有一个多重递减的环境。(为了衡量违约率,可以将非违约出口组合起来,这样模型就变成了只有双减量。)那么,如果$D(t)$表示$t$年违约债务的价值,$P(t)$表示$t$年开始时幸存的债券数量的价值,则
$$
M M R_{\ell}=\frac{D(t)}{P(t)}
$$
给出了年的边际死亡率$t$。
Altman进一步定义
$$
S R_t=1-M M R_t
$$
为债券成活率$t$年,和
$$
C M R_t=1-\prod_{j=1}^t S R_j
$$
为间隔$(0, t)$内的累积死亡率。
最后,Altman考虑了1971年至1987年这17年样本期内各种债券的死亡/生存经验。由于$M M R_t$的值是在每个单独发行年的每个持续时间$t$上计算的,因此它们必须结合起来以达到整个研究持续时间$t$的比率。合并是在价值加权的基础上进行的,因为如果新发行金额每年变化很大,则未加权的平均值可能会产生误导。对Altman的数值结果感兴趣的读者可参考[2]。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。