统计代写|AP统计代写AP统计代考|MAZ611U
如果你也在 怎样代写AP统计这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
AP统计学与大学的统计学课程在核心内容上是一致的,只是涉及的深度稍浅,AP统计学主要包含以下四部分内容。 第一部分 如何获取数据,获取数据的方式有哪些呢? 获取数据的方式主要包括普查、抽样调查、观测研究和实验设计等。
statistics-lab™ 为您的留学生涯保驾护航 在代写AP统计方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写AP统计代写方面经验极为丰富,各种代写AP统计相关的作业也就用不着说。
我们提供的AP统计及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础

统计代写|AP统计代写AP统计代考|General Test-Taking Tips
Much of being good at test-taking is experience. Your own test-taking history and these tips should help you demonstrate what you know (and you know a lot) on the exam. The tips in this section are of a general nature-they apply to taking tests in general as well as to both multiple-choice and free-response type questions.
- Look over the entire exam first, whichever part you are working on. With the exception of, maybe, Question #1 in each section, the questions are not presented in order of difficulty. Find and do the easy questions first.
- Don’t spend too much time on any one question. Remember that you have an average of slightly more than two minutes for each multiple-choice question, $12-13$ minutes for Questions 1-5 of the free-response section, and 25-30 minutes for the investigative task. Some questions are very short and will give you extra time to spend on the more difficult questions. At the other time extreme, spending 10 minutes on one multiplechoice question (or 30 minutes on one free-response question) is not a good use of time-you won’t have time to finish.
- Become familiar with the instructions for the different parts of the exam before the day of the exam. You don’t want to have to waste time figuring out how to process the exam. You’ll have your hands full using the available time figuring out how to do the questions. Look at the Practice Exams at the end of this book so you understand the nature of the test.
- Be neat! On the Statistics exam, communication is very important. This means no smudges on the multiple-choice part of the exam and legible responses on the free-response. A machine may score a smudge as incorrect and readers will spend only so long trying to decipher your handwriting.
- Practice working as many exam-like problems as you can in the weeks before the exam. This will help you know which statistical technique to choose on each question. It’s a great feeling to see a problem on the exam and know that you can do it quickly and easily because it’s just like a problem you’ve practiced on.
- Make sure your calculator has new batteries. There’s nothing worse than a “Replace batteries now” warning at the start of the exam. Bring a spare calculator if you have or can borrow one (you are allowed to have two calculators).
- Bring a supply of sharpened pencils to the exam. You don’t want to have to waste time walking to the pencil sharpener during the exam. (The other students will be grateful for the quiet, as well.) Also, bring a good-quality eraser to the exam so that any erasures are neat and complete.
- Get a good night’s sleep before the exam. You’ll do your best if you are relaxed and confident in your knowledge. If you don’t know the material by the night before the exam, you aren’t going to learn it in one evening. Relax. Maybe watch an early movie. If you know your stuff and aren’t overly tired, you should do fine.
统计代写|AP统计代写AP统计代考|Tips for Multiple-Choice Questions
There are whole industries dedicated to teaching you how to take a test. In reality, no amount of test-taking strategy will replace knowledge of the subject. If you are on top of the subject, you’ll most likely do well even if you haven’t paid $\$ 500$ for a test-prep course.
The following tips, when combined with your statistics knowledge, should help you do well.
- Read the question carefully before beginning. A lot of mistakes get made because students don’t completely understand the question before trying to answer it. The result is that they will often answer a different question than they were asked.
- Try to answer the question before you look at the answers. Looking at the choices and trying to figure out which one works best is not a good strategy. You run the risk of being led astray by an incorrect answer. Instead, try to answer the question first, as if there was just a blank for the answer and no choices.
- Understand that the incorrect answers (which are called distractors) are designed to appear reasonable. Watch out for words like never and always in answer choices. These frequently indicate distractors. Don’t get suckered into choosing an answer just because it sounds good! The question designers try to make all the logical mistakes you might make and the answers they come up with become the distractors. For example, suppose you are asked for the median of the five numbers $3,4,6,7$, and 15 . The correct answer is 6 (the middle score in the ordered list). But suppose you misread the question and calculated the mean instead. You’d get 7 and, be assured, 7 will appear as one of the distractors.
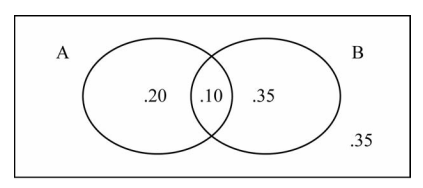
- Drawing a picture can often help visualize the situation described in the problem. Sometimes, relationships become clearer when a picture is used to display them. For example, using Venn diagrams can often help you “see” the nature of a probability problem. Another example would be using a graph or a scatterplot of some given data as part of doing a regression analysis.
- Answer each question. You will earn one point for each correct answer. Incorrect answers are worth zero points and no points are earned for blank responses. If you aren’t sure of an answer, eliminate as many choices as you can, then guess.
- Double check that you have (a) answered the question you are working on, especially if you’ve left some questions blank (it’s horrible to realize at some point that all of your responses are one question off!) and (b) that you have filled in the correct bubble for your answer. If you need to make changes, make sure you erase completely and neatly.
AP统计代写
统计代写|AP统计代写AP统计代考|General Test-Taking Tips
擅长应试的很大一部分是经验。您自己的考试历史和这些提示应该可以帮助您展示您在考试中所知道的(并且您知道的很多)。本节中的提示具有一般性质——它们适用于一般考试以及多项选择题和自由回答题。
- 首先查看整个考试,无论您正在研究哪个部分。除了每个部分中的问题 #1 之外,这些问题没有按难度顺序排列。首先找到并做简单的问题。
- 不要在任何一个问题上花费太多时间。请记住,每个多项选择题的平均时间略多于两分钟,12−13自由回答部分的问题 1-5 分钟,调查任务 25-30 分钟。有些问题很短,会给你额外的时间来解决更难的问题。在另一个极端情况下,在一个多项选择题上花费 10 分钟(或在一个自由回答问题上花费 30 分钟)并不是一种很好的时间利用方式——你将没有时间完成。
- 在考试前熟悉考试不同部分的说明。您不想浪费时间弄清楚如何处理考试。您将充分利用可用的时间来弄清楚如何做这些问题。查看本书末尾的练习考试,以便了解考试的性质。
- 保持整洁!在统计学考试中,沟通非常重要。这意味着考试的多项选择部分没有污点,自由回答的答案清晰易读。机器可能会将污迹记为不正确,而读者只会花很长时间尝试破译您的笔迹。
- 在考试前的几周内尽可能多地练习解决类似考试的问题。这将帮助您了解在每个问题上选择哪种统计技术。在考试中看到一个问题并知道您可以快速轻松地完成它是一种很棒的感觉,因为它就像您练习过的问题一样。
- 确保您的计算器有新电池。没有什么比考试开始时出现“立即更换电池”警告更糟糕的了。如果您有或可以借用一个备用计算器(您可以拥有两个计算器)。
- 考试时带上削尖的铅笔。您不想在考试期间浪费时间走到卷笔刀旁。(其他学生也会因为安静而感激。)另外,考试时带上质量好的橡皮擦,这样任何擦除都整齐完整。
- 考试前睡个好觉。如果您对自己的知识感到放松和自信,您会尽力而为。如果你在考试前一晚还不知道这些材料,你就不会在一个晚上学会它。放松。也许看一部早期的电影。如果您知道自己的东西并且不太累,那么您应该做得很好。
统计代写|AP统计代写AP统计代考|Tips for Multiple-Choice Questions
整个行业都致力于教你如何参加考试。实际上,再多的应试策略也无法取代对这门学科的了解。如果你掌握了这个主题,即使你没有付钱,你也很可能会做得很好$500备考课程。
以下提示与您的统计知识相结合,应该可以帮助您做得更好。
- 在开始之前仔细阅读问题。因为学生在尝试回答之前没有完全理解问题,所以会犯很多错误。结果是他们经常会回答与他们被问到的不同的问题。
- 在查看答案之前尝试回答问题。查看选择并试图找出哪个最有效并不是一个好策略。你冒着被错误答案误导的风险。相反,试着先回答这个问题,好像答案只有一个空白,没有选择。
- 理解不正确的答案(称为干扰项)是为了显得合理而设计的。在答案选择中注意像从不和总是这样的词。这些经常表明干扰因素。不要仅仅因为听起来不错就选择一个答案!问题设计者试图犯下你可能犯的所有逻辑错误,而他们提出的答案会分散注意力。例如,假设您被要求输入五个数字的中位数3,4,6,7, 和 15 . 正确答案是 6(排序列表中的中间分数)。但是假设您误读了问题并计算了平均值。你会得到 7,而且,请放心,7 将作为干扰因素之一出现。
- 绘制图片通常可以帮助形象化问题中描述的情况。有时,当使用图片显示它们时,关系会变得更加清晰。例如,使用维恩图通常可以帮助您“了解”概率问题的本质。另一个例子是使用一些给定数据的图表或散点图作为回归分析的一部分。
- 回答每个问题。每答对一题,您将获得一分。不正确的答案是零分,空白回答不得分。如果您不确定答案,请消除尽可能多的选择,然后猜测。
- 仔细检查您是否 (a) 回答了您正在处理的问题,特别是如果您将一些问题留空(在某些时候意识到您的所有回答都是一个问题,这太可怕了!)和 (b) 您已为您的答案填入正确的气泡。如果您需要进行更改,请确保您完全整齐地擦除。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。