CS代写|程序设计作业代写algorithm Programming代考|Not That Kind of Graph
Your task is to graph the price of a stock over time. In one unit of time, the stock can either Rise, Fall, or stay Constant. The stock’s price will be given to you as a string of R’s, F’s, and C’s. You need to graph it using the characters ‘ $/$ ‘ (slash), ‘ $R$ ‘ (backslash) and ‘_’ (underscore). Input The first line of input gives the number of cases, $N$. $N$ test cases follow. Each one contains a string of at least 1 and at most 50 uppercase characters ( $R, F$, or $C$ ). Output For each test case, output the line “Case #x:”, where $x$ is the number of the test case. Then print the graph, as shown in the sample output, including the $x$ – and $y$-axes. The $x$-axis should be one character longer than the graph, and there should be one space between the $y$-axis and the start of the graph. There should be no trailing spaces on any line. Do not print unnecessary lines. The $x$-axis should always appear directly below the graph. Finally, print an empty line after each test case.
CS代写|程序设计作业代写algorithm Programming代考|Factorial! You Must be Kidding
Arif has bought a supercomputer from Bongobazar. Bongobazar is a place in Dhaka where secondhand goods are available. So the supercomputer he bought is also secondhand and has some bugs. One of the bugs is that the range of unsigned long integers of this computer for a $\mathrm{C} / \mathrm{C}++$ compiler has changed. Now its new lower limit is 10000 and the upper limit is 6227020800 . Arif writes a program in C/C++ which determines the factorial of an integer. The factorial of an integer is defined recursively as: Factorial $(0)=1$ Factorial $(n)=n \times$ Factorial $(n-1)$. Of course, one can manipulate these expressions. For example, it can be written as: $$ \text { Factorial }(n)=n \times(n-1) \times \text { Factorial }(n-2) $$ This definition can also be converted to an iterative one. But Arif knows that his program will not behave correctly in the supercomputer. You are to write a program which will simulate that changed behavior in a normal computer. Input The input file contains several lines of input. Each line contains a single integer $n$. No integer has more than 6 digits. Input is terminated by end of file.
Tic Tac Toe is a child’s game played on a 3 by 3 grid. One player, X, starts by placing an $\mathrm{X}$ at an unoccupied grid position. Then the other player, $\mathrm{O}$, places an $\mathrm{O}$ at an unoccupied grid position. Play alternates between $X$ and $O$ until the grid is filled or one player’s symbols occupy an entire line (vertical, horizontal, or diagonal) in the grid.
We will denote the initial empty Tic Tac Toe grid with nine dots. Whenever $\mathrm{X}$ or $\mathrm{O}$ plays, we fill in an $\mathrm{X}$ or an $\mathrm{O}$ in the appropriate position. The example in Figure $1.4$ illustrates each grid configuration from the beginning to the end of game in which $X$ wins.
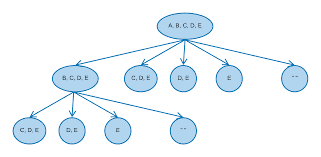
Your job is to read a grid and to determine whether or not it could possibly be part of a valid Tic Tac Toe game. That is, is there a series of plays that can yield this grid somewhere between the start and end of the game? Input The first line of input contains $N$, the number of test cases. $4 N-1$ lines follow, specifying $N$ grid configurations separated by empty lines.
CS代写|程序设计作业代写algorithm Programming代考|Rock, Scissors, Paper
Bart’s sister Lisa has created a new civilization on a two-dimensional grid. At the outset, each grid location may be occupied by one of three life forms: Rocks, Scissors,or Papers. Each day, differing life forms occupying horizontally or vertically adjacent grid locations wage war. In each war, Rocks always defeat Scissors, Scissors always defeat Papers, and Papers always defeat Rocks. At the end of the day, the victor expands its territory to include the loser’s grid position. The loser vacates the position.
Your job is to determine the territory occupied by each life form after $n$ days. Input The first line of input contains $t$, the number of test cases. Each test case begins with three integers not greater than $100: r$ and $c$, the number of rows and columns in the grid, and $n$. The grid is represented by the $r$ lines that follow, each with $c$ characters. Each character in the grid is $R, S$, or $P$, indicating that it is occupied by Rocks, Scissors, or Papers respectively.
Computer simulations often require random numbers. One way to generate pseudorandom numbers is via a function of the form: $\operatorname{seed}(x+1)=[\operatorname{seed}(x)+S T E P] \% M O D \quad$ where $” \%$ ” is the modulus operator. Such a function will generate pseudo-random numbers (seed) between 0 and $M O D-1$. One problem with functions of this form is that they will always generate the same pattern over and over. In order to minimize this effect, selecting the STEP and $M O D$ values carefully can result in a uniform distribution of all values between (and including) 0 and $M O D-1 .$
For example, if $S T E P=3$ and $M O D=5$, the function will generate the series of pseudo-random numbers $0,3,1,4,2$ in a repeating cycle. In this example, all of the numbers between and including 0 and $M O D-1$ will be generated every $M O D$ iterations of the function. Note that by the nature of the function to generate the same $\operatorname{seed}(x+1)$ every time, $\operatorname{seed}(x)$ occurs means that if a function will generate all the numbers between 0 and $M O D-1$, it will generate pseudo-random numbers uniformly with every $M O D$ iteration.
If $S T E P=15$ and $M O D=20$, the function generates the series $0,15,10,5$ (or any other repeating series if the initial seed is other than 0 ). This is a poor selection of $S T E P$ and $M O D$ because no initial seed will generate all of the numbers from 0 and $M O D-1$.
Your program will determine whether choices of $S T E P$ and $M O D$ will generate a uniform distribution of pseudo-random numbers.
CS代写|程序设计作业代写algorithm Programming代考|Minesweeper
The game Minesweeper is played on an $n$ by $n$ grid. In this grid are hidden $m$ mines, each at a distinct grid location. The player repeatedly touches grid positions. If a position with a mine is touched, the mine explodes and the player loses. If a position not containing a mine is touched, an integer between 0 and 8 appears, denoting the number of adjacent or diagonally adjacent grid positions that contain a mine. A sequence of moves in a partially played game is illustrated below in Figure 1.3. Here, $n$ is $8, m$ is 10 , blank squares represent the integer 0 , raised squares represent unplayed positions, and the figures resembling asterisks represent mines. The leftmost image represents the partially played game. From the first image to the second,the player has played two moves, each time choosing a safe grid position. From the second image to the third, the player is not so lucky; he chooses a position with a mine and therefore loses. The player wins if he continues to make safe moves until only $m$ unplayed positions remain; these must necessarily contain the mines.
Your job is to read the information for a partially played game and to print the corresponding board.
The first line of input contains a single positive integer $n \leq 10$. The next $n$ lines rep resent the positions of the mines. Each line represents the contents of a row using $n$ characters: a period indicates an unmined positon, while an asterisk indicates a mined position. The next $n$ lines are each $n$ characters long: touched positions are denoted by an $x$, and untouched positions by a period. The sample input corresponds to the middle section of Figure 1.3.
计算机模拟通常需要随机数。生成伪随机数的一种方法是通过以下形式的函数: $\operatorname{seed}(x+1)=[\operatorname{seed}(x)+S T E P] \% M O D \quad$ 在哪里” \%” 是模运算符。 这样的函数将生成 0 到 0 之间的伪随机数(种子) $M O D-1$. 这种形式的函数的一个问题是它们总是会一遍又一 遍地生成相同的模式。为了尽量减少这种影响,选择 STEP 和 $M O D$ 仔细考虑值可以导致所有值在 (包括) 0 和 $M O D-1 .$ 例如,如果 $S T E P=3$ 和 $M O D=5$ ,该函数将生成一系列伪随机数 $0,3,1,4,2$ 在一个重复的循环中。在这个 例子中,所有介于 0 和 $M O D-1$ 将生成每个 $M O D$ 函数的迭代。请注意,由函数的性质来生成相同的 $\operatorname{seed}(x+1)$ 每次, $\operatorname{seed}(x)$ 发生意味着如果一个函数将生成 0 到 $M O D-1$ ,它将均匀地生成伪随机数 $M O D$ 迭代。 如果 $S T E P=15$ 和 $M O D=20$ ,函数生成序列 $0,15,10,5$ (或任何其他重复序列,如果初始种子不是 0 )。 这是一个糟糕的选择 $S T E P$ 和 $M O D$ 因为没有初始种子会从 0 和 $M O D-1$. 您的程序将决定是否选择 $S T E P$ 和 $M O D$ 将生成伪随机数的均匀分布。
CS代写|程序设计作业代写algorithm Programming代考|THE ART OF FILE PROCESSING
CS代写|程序设计作业代写algorithm Programming代考|A file may generally
A file may generally be defined as an organized collection of well-ordered, well-related, and self-contained information held on a stable storage medium. The information in a file is placed in a specific way and read back in a specific way. The information must be kept together as a unit in the same sequence in a well-organized way. The different units of information must bear some relationship with one another for collective consideration. A file is self-contained in that it is complete in all respects. The stable storage medium may be a piece of paper, a magnetic or optical disk, or a magnetic tape or any other medium where the information can be kept for a long time for repeated use without any special aid. Thus, the information bearing the characteristics mentioned above stored in the main memory of a computer will not make a file because the main memory of a computer can hold it only as long as electricity is supplied to the main memory.
Depending on the nature of the information, files can be classified into two basic types: the program file and the data file. A program file is a file that contains a sequential set of instructions in a computer language that can direct a computer in the performance of some specific task. A data file is a collection of records about closely-related or similar entities. However, these types of files should possess all the features stated in the generalized definition above. A record is an ordered collection of the attribute values of an entity. An attribute is any characteristic or feature of an entity that tells something about the entity, where an entity is anything with a physical or conceptual existence. A fact is anything that is true about an entity. To collect facts about an entity, we first decide on some attributes of the entity and procure facts on those attributes. We normally choose a group of entities called an entity set, a collection of items that are considered together for some close relationship. We next select some of the attributes common to all the entities of the set and collect facts on those attributes in a predefined order to form a record for each of them and put all such records together to form the desired file. Let us consider a business enterprise, for instance. The employees of the enterprise form a closely related set of entities. If we consider the attributes EMPLOYEE-CODE-NUMBER, EMPLOYEE-NAME, EMPLOYEE-ADDRESS, DESIGNATION, and SALARY for each of the employees, then the values of these attributes in the mentioned order form a record of an employee of the enterprise and the collection of all the records of the employees of the enterprise forms the desired employee data file (if the records are kept on a stable storage medium).
CS代写|程序设计作业代写algorithm Programming代考|A file is typically considered
A file is typically considered a data file. The task of file processing is the set of activities performed on the records of a file to generate some desired information. Now depending on the organization of the records, the set of operations will vary. We next consider a discussion on file organization. Basically, file organization can be classified into three categories: (i) Sequential File Organization (ii) Indexed File Organization (iii) Hashed/Relative/Random File Organization Sequential file organization is one in which records are kept in a file, one after another, and processed in the same sequence in which they are written. The term sequential means one after another, and hence the name bears the nature of the organization of the file.
Indexed file organization is one in which sequentially organized records are associated with an index for the purpose of direct access to the records. An index is a special kind of file that contains records consisting of two attribute values, one that is a unique identifying attribute of the records in the sequential file and the other that contains the address of the records in the main file. The identifying attribute is also known as the key attribute or key field. The records in the index are kept in the ascending order of the key field values. When a user wishes to access a record from an indexed file, she initiates a binary search in the index for some key field value and the record found in the search process is then accessed to get the address of the desired record in the main file. Thus, any record in an indexed file can be accessed without reading the preceding or the following records in the file. This saves time and increases the speed of processing, if the number of records to be accessed in
one processing run is less than one-fourth of the total number of records in the file. The disadvantage of such a file organization is that it takes additional disk space for the index, and hence the file organization is more expensive than sequential file organization. The speed of accessing records also varies depending on the organization of the records in the index. For more details about the index file organization, please see any standard textbook on databases or file management systems.
A hashed or relative file organization is also a direct access file organization. In such a file organization, the key field or identifying attribute value is hashed or converted to some location address in the file space relative to the beginning of the file-record positions on the basis of some predefined function. The predefined function is called a hash routine and the method is called hashing. As the hashing is done dynamically during the creation of the file, no extra file space is needed for this purpose, rather, the records can be pointed to directly later by using the same hash function. The only problem with this type of organization is the proper selection of the hash function and its implementation through programming instructions. The programming efficiency of the developers is considered when selecting one of the two direct access file organizations. (The reader is again advised to read a textbook on file/database management systems for further details.) We now study different problems on file processing to illustrate the flowcharts and the algorithms corresponding to their solutions. The following problems involve sequential file organization.
CS代写|程序设计作业代写algorithm Programming代考|A file named EMPFL
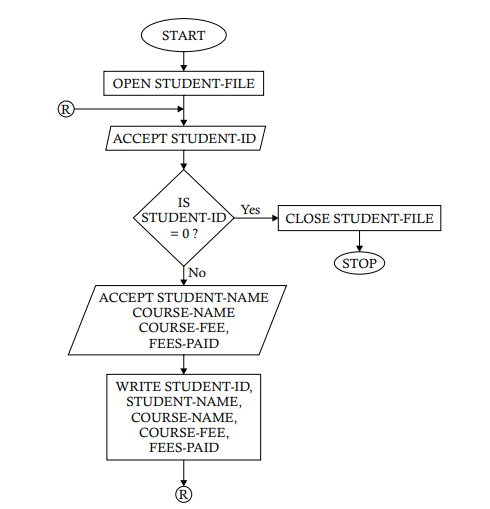
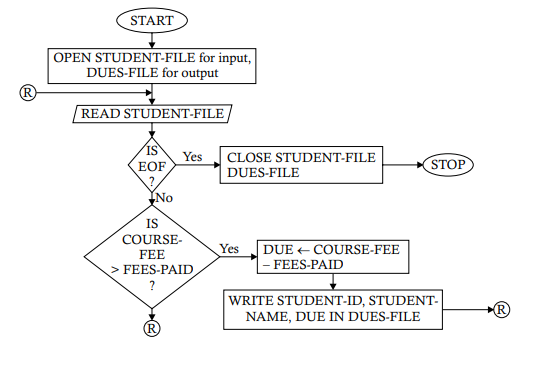
Problem 5.3. A file named EMPFL contains the records of the employees of an organization. Each record consists of data: EMP-CODE, EMP-NAME, and BASIC-PAY. The gross salary of an employee is calculated by using the following formula: Gross Salary = Basic Pay + DA + ADA + HRA + MA where $\quad D A=45 \%$ of Basic Pay $A D A=18 \%$ of Basic Pay subject to a minimum of $\$ 200$ and a maximum of $\$ 1000$. HRA $=25 \%$ of Basic Pay subject to a minimum of $\$ 500$ and a maximum of $\$ 5000$. $M A=10 \%$ of the Basic pay subject to a minimum of $\$ 100$. The net salary of an employee is calculated by the formula: Net Salary = Gross Salary $-$ Total Deduction where Total Deduction $=P F+P T$ where $\quad P F=12 \%$ of Basic Pay $P T=5 \%$ of Basic Pay subject to a maximum of $\$ 200$. Develop a flowchart and the algorithm to show how the salary for different employees is calculated to generate the pay slips for the employees of the organization.
Task Analysis. The problem here is to print the pay slip for each of the employees whose records are contained in EMPFL. This can be done by reading the records of the employees one at a time and then calculating the DA, ADA, HRA, and MA values to determine the gross salary and then finding out the amounts of PF and PT for determining the total deduction. The net salary can then be obtained by subtracting the total deduction from the gross salary. The ADA is $18 \%$ of Basic Pay, subject to a minimum of $\$ 200$ and a maximum of $\$ 1,000$. This implies that if the $18 \%$ of the Basic Pay value happens to be less than $\$ 200$, then $\$ 200$ is the ADA amount; if, however, it exceeds $\$ 1,000$, then $\$ 1,000$ is the ADA amount. The conditions for HRA, MA, and PT can be handled in the same way.
CS代写|程序设计作业代写algorithm Programming代考|THE ART OF FILE PROCESSING
Think of a road with a row of houses on it. How would you get a unique address for a house on that road? You would take the name of the road and the house number of the lot. An array is similar to a road with a number of houses. The name of the road can be thought of as the name of the array and the number of the house can be thought of as the location number in the array. Formally speaking, an array is a finite collection of homogeneous data values usually stored in consecutive memory locations with a common name. The term finite implies that the number of data values of an array must be limited by its size. The term homogeneous means “having the same nature or characteristic.” The term usually implies that arrays are almost always implemented by using contiguous locations of the computer’s main memory in a linearly ordered fashion, but not always. The common name assigned to a set of adjacent memory locations to hold the data of a particular type is called the name of the array. The different data values of an array are mentioned by using the name of the array along with a subscript within brackets, such as $\mathrm{A}[1], \mathrm{A}(1)$, and $\mathrm{A}[2]$, or in general, $\mathrm{A}[i]$, where $i$ must be an integer. The value of $i$ is the location. The subscript is also called an index. This is why an array element such as $\mathrm{A}[i]$ is also called an indexed or subscripted variable. The following are some examples of arrays:
The roll numbers of the students of a class stored in a computer’s main memory in linear order
The names of the students of a class stored in the computer’s main memory in linear order
The maximum temperatures of different days of a month in a city stored in the computer’s memory in linear order
All of the data stored together are of the same type, i.e., homogeneous. For example, roll numbers are usually integers, names are usually strings of characters, and temperatures are usually fractional or floating point numbers. Hence, the first example is an array of integers, the second example is an array of strings, and the third example is an array of floating point numbers. Different computer languages use different notations to represent the array elements. However, we will use just one notation. If $\mathrm{A}$ is an array of size $n$, then we will point to an array element by the notation $\mathrm{A}(i)$, where the value of $i$ can vary from 1 to $n$.
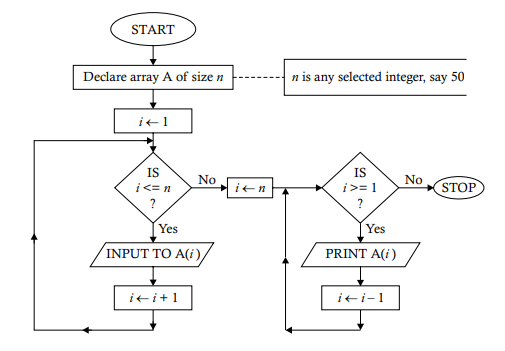
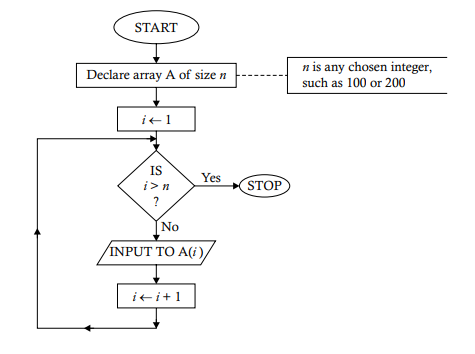
Problem 4.1. The goal here is to show you how to construct an array. The following algorithm will clarify the steps:
Decide the size of the array to be formed, say $n$.
Declare an array of size $n$ with some desired name, say A.
CS代写|程序设计作业代写algorithm Programming代考|The inputs are the grades obtained
Task Analysis. The inputs are the grades obtained by students on three tests. To identify the student, the student roll-number and name of each student are given as input. The final score of each student is obtained by determining the greater score of the first two tests and then adding it to that of the third test. The total score represents the percentage score because the total is based on the marks of two tests, each of which carries a maximum grade of 50 . At this stage, we shall have the Roll Number, Name, and Percentage of all the students. The next task is to sort the facts to get information about the students in a descending sequence of percentages. To sort the facts, we take the percentage of the first student and compare it with the percentage of all the other remaining students and interchange the student’s data whenever some student’s percentage is found to be less than the percentage of that of the first student’s percentage. Similarly, we take the percentage of the second student to compare it with the percentage of the third student to interchange the facts, if needed. This type of comparison is continued until we compare the percentage of the last two students.
CS代写|程序设计作业代写algorithm Programming代考|repeat these comparisons
We repeat these comparisons each time, considering one less element than that in the preceding step. It can be observed that after $(N-1)$ steps, the set of numbers will be in the sorted sequence. The algorithm of the above process is stated below: Step 1. FOR I = $1 \mathrm{TON}$ Step 2. INPUT TO A(I) Step 3. END-FOR Step 4. FOR I = 1 TO N $-1$ Step 5. FOR J=1 TO N – I Step 6. $\operatorname{IF~} \mathrm{A}(\mathrm{J})>\mathrm{A}(\mathrm{J}+1)$ THEN $\mathrm{T} \leftarrow \mathrm{A}(\mathrm{J})$ $\mathrm{A}(\mathrm{J}) \leftarrow \mathrm{A}(\mathrm{J}+1)$ $\mathrm{A}(\mathrm{J}+1) \leftarrow \mathrm{T}$ END-IF Step 7. END-FOR-J Step 8. END-FOR-I Step 9. FOR I = 1 TO N Step 10. PRINT A(I) Step 11. END-FOR-I Step 12. STOP Problem 4.10. Draw a flowchart to show how the product of two matrices can be obtained.
Task Analysis. We know that a matrix is a two-dimensional array. The multiplication of two matrices is possible if the number of columns of the first matrix is equal to the number of rows in the second matrix or if the number of rows in the first matrix equals the number of columns of the second matrix. If we consider the row-by-column multiplication of the two matrices, then each element of a row is taken sequentially to multiply with the corresponding column elements, taking one at a time, and the sum of these products is taken as an element of the resulting matrix. This is repeated for all the rows of the first matrix. The reverse process is carried out for the column by row multiplication. To describe the process mathematically, let $\mathrm{A}=\left[a_{i j}\right]$ be an $m \times n$ matrix and $\mathrm{B}=\left[b_{i j}\right]$ be an $n \times p$ matrix. Then the product A.B of these matrices is of the order $m \times p$ say, $\mathrm{C}=\left[c_{i j}\right]$. where $c_{i j}=a_{i 1} \cdot b_{1 j}+a_{i 2} \cdot b_{2 i}+\ldots \ldots+a_{i n} \cdot b_{n j}$ $$ \Rightarrow \quad c_{i j}=\sum_{k=1}^{n} a_{i k} \cdot b_{k j} $$
CS代写|程序设计作业代写algorithm Programming代考|repeat these comparisons
我们每次都重复这些比较,考虑比上一步中的元素少一个。可以观察到,之后(ñ−1)步骤,这组数字将按排序顺序排列。 上述过程的算法如下: Step 1. FOR I =1吨这ñ 步骤 2. 输入 A(I) 步骤 3. END-FOR 步骤 4. FOR I = 1 TO N−1 第 5 步。对于 J=1 TO N – I 第 6 步。一世F 一种(Ĵ)>一种(Ĵ+1) 然后吨←一种(Ĵ) 一种(Ĵ)←一种(Ĵ+1) 一种(Ĵ+1)←吨 END-IF 步骤 7. END-FOR-J 步骤 8. END-FOR-I 步骤 9. FOR I = 1 TO N 步骤 10. 打印 A(I) 步骤 11. END-FOR-I 步骤 12. 停止 问题 4.10 . 画一个流程图来说明如何得到两个矩阵的乘积。
任务分析。我们知道矩阵是一个二维数组。如果第一个矩阵的列数等于第二个矩阵的行数,或者如果第一个矩阵的行数等于第二个矩阵的列数,则两个矩阵相乘是可能的。如果我们考虑两个矩阵的逐列相乘,那么每一行的每个元素都依次与对应的列元素相乘,一次取一个,将这些乘积之和作为一个元素结果矩阵。这对第一个矩阵的所有行重复。对逐行乘法执行相反的过程。为了用数学方法描述这个过程,让一种=[一种一世j]豆米×n矩阵和乙=[b一世j]豆n×p矩阵。那么这些矩阵的乘积 AB 是有序的米×p说,C=[C一世j]. 在哪里C一世j=一种一世1⋅b1j+一种一世2⋅b2一世+……+一种一世n⋅bnj
CS代写|程序设计作业代写algorithm Programming代考|Construct a flowchart to show
CS代写|程序设计作业代写algorithm Programming代考|Construct a flowchart to show
Problem 3.23. Construct a flowchart to show how you can decide if a given number is prime or not.
Task Analysis. We know that a number can be called a prime number if, and only if, it has no divisor or factor except itself and unity, i.e., 1. In order to declare that a number is a prime number, we need to prove that the number is not divisible by any number starting from 2 to the half of the given number because we have already seen that if a number has some divisor at all, it must lie within the half of the number. A better, more efficient strategy is to limit the checking within the integer part of the square root of the number. For example, to check if the number 97 is a prime number, we need check whether there exists some divisor of 97 within 2 to 48 (both inclusive). This checking can be done from 2 to 9 , because 9 is the integer part of the square root of 97 . The number of checking is decreased to a large extent. The divisors can be generated automatically by changing the value of a variable location. Assuming that the procedure for determining the square root of a number is available, we can draw the flowchart for the task.
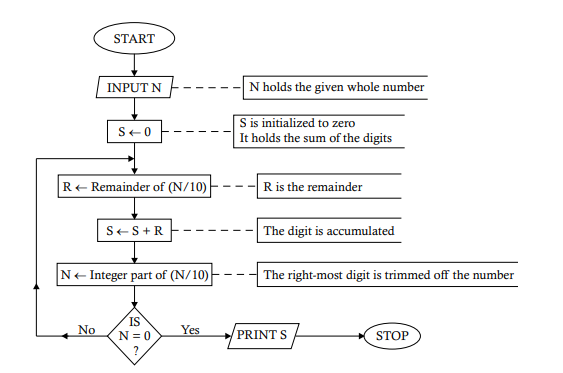
The following algorithm shows the steps leading to the solution for Problem 3.23: Step 1. INPUT TO N [ACCEPT THE NUMBER WHOSE SQUARE ROOT IS TO BE FOUND] Step 2. COMPUTE SR $\leftarrow$ SQUARE ROOT OF (N) Step 3. [INITIALIZE] I $\leftarrow 2, \mathrm{FLAG} \leftarrow 0$ [FLAG contains the divisibility status of the number] Step 4. WHILE I $<=S R$ DO (i) COMPUTE $\mathrm{R} \leftarrow$ REMAINDER OF (N/I) (ii) IF $\mathrm{R}=0$ THEN FLAG $\leftarrow 1$ EXIT END-IF (iii) COMPUTE I $\leftarrow$ I $+1$ (Increment I to obtain the next divisor] Step 5. IF FLAG =0 THEN PRINT “It is a prime number.” ELSE PRINT”It is not a prime number.” END-IF Step 6. STOP
CS代写|程序设计作业代写algorithm Programming代考|The algorithm below shows the solution of Problem
The algorithm below shows the solution of Problem $3.24$. Step 1. INPUT TO N [Establish N, the number of FIBONACCI NUMBERS to be generated] Step 2. [INITIALIZE VARIABLES WITH THE FIRST TWO FIBONACCI NUMBERS] $\mathrm{T} 1 \leftarrow 0, \quad \mathrm{~T} 2 \leftarrow 1$ Step 3. [INITIALIZE THE COUNTER VARIABLE] COUNT $\leftarrow 0$ Step 4. WHILE COUNT $<=\mathrm{N}$ (i) COMPUTE $\mathrm{T} \leftarrow \mathrm{T} 1+\mathrm{T} 2$ (ii) PRINT Tl (iii) COMPUTE COUNT $\leftarrow$ COUNT $+1$ (iv) $\mathrm{T} 1 \leftarrow \mathrm{T} 2$ (v) $\mathrm{T} 2 \leftarrow \mathrm{T}$ Step 5. STOP Problem 3.25. Construct a flowchart to show if a given year is leap year. Task Analysis. A given year is said to be a leap year if it is a non-century year (i.e., not like 1900,1800 , or 1600 ) and it is divisible by 4 . In case it is a century year, then it must be divisible by 400 to be a leap year. To determine whether a given year is a leap year, we determine whether the year is divisible by 4 but not by 100 or if it is divisible by 400 . The divisibility is tested again in the way as we have seen earlier, i.e., by checking whether the remainder in the division process is zero or not. Step 1. $\quad \mathrm{Y} \leftarrow 1$ Step 2. REPEAT STEPS 2 TO 8 UNTIL $\mathrm{Y}=0$ Step 3. INPUT TO Y [ACCEPT YEAR TO BE TESTED AND STORE IT IN Y] Step 4. IF $Y=0$ THEN EXIT END-IF Step 5. COMPUTE R $1 \leftarrow$ REMAINDER OF (Y/400) Step 6. $\quad$ IF Rl $=0$ THEN PRINT “THE GIVEN YEAR IS A LEAP YEAR” END-IF
CS代写|程序设计作业代写algorithm Programming代考|The square root of a number
Task Analysis. The square root of a number can be obtained by using the Newton Raphson Method. In this method, the square root of any positive number is initially set to 1 . Then the absolute value of the difference between
the square of the assumed square root and the given number is obtained. This value is then compared with some predefined small positive number. This small positive number is set in such a way that an error of magnitude less than that is made acceptable. If the difference is less than the small positive number, the assumed square root is used as the desired square root. For perfect squares, this difference becomes zero; for others, this difference is usually found to be of magnitude less than $.01, .001$, or .0001, depending upon the precision required. If the difference is greater than or equal to the small positive number like $.001$ or $.0001$, then the assumed value is increased to have a better guess by using the formula $$ \left(\text { Guessed Value }+\frac{\text { Number }}{\text { Guessed Value }}\right) / 2 $$ The procedure is repeated until we get a guessed value satisfying the condition specified. Algorithmically, we can express the procedure as shown below. Let X be the number whose square root is to be obtained.
Set Guess to $1 .$
If $\mid$ GUESS*GUESS-X $\mid<$ Epsilon Then go to step 5 (Epsilon is a predefined small positive number)
Set Guess to $\left(\right.$ Guess $\left.+\frac{\mathrm{X}}{\text { Guess }}\right) / 2$
Go to Step 2
Guess is the square root of X. The flowchart corresponding to Problem $3.26$ is shown in next page. The algorithm for the solution of Problem $3.26$ is given below: Step 1. INPUT TO X Step 2. [INITIALIZE] GUESS $\leftarrow 1$, EPSILON $\leftarrow .001$ Step 3. WHILE absolute value of $(\mathrm{GUESS} * \mathrm{GUESS}-\mathrm{X})<=$ EPSILON DO $\mathrm{COMPUTE} \mathrm{GUESS} \leftarrow\left(\mathrm{GUESS}+\frac{\mathrm{X}}{\mathrm{GUESS}}\right) / 2$ Step 4. PRINT “THE SQUARE ROOT IS”, GUESS Step 5. STOP
CS代写|程序设计作业代写algorithm Programming代考|Construct a flowchart to show
以下算法显示了求解问题 3.23 的步骤: 步骤 1. 输入 N [接受要求平方根的数] 步骤 2. 计算 SR←(N) 的 平方根 步骤 3. [初始化] I←2,F大号一种G←0 [FLAG 包含数字的整除状态] Step 4. WHILE I<=小号R做 (i) 计算R←(N/I) (ii) IF的剩余部分R=0 然后标志←1 退出 END-IF (iii) 计算 I←一世+1 (增加 I 以获得下一个除数) Step 5. IF FLAG =0 THEN PRINT “It is a prime number.” ELSE PRINT“It is not a prime number.” END-IF Step 6. STOP
CS代写|程序设计作业代写algorithm Programming代考|The algorithm below shows the solution of Problem
Task Analysis. Natural numbers are those numbers that are obtained through sequential counting. The starting number here for the summation process is 1 , the next number is 2 and so on, until we reach $n$-the number of natural numbers to be summed. The numbers to be added are known as inputs and can be generated by instructing the computer. We assign the value 1 to a variable to simulate the first natural number. We then add the value of the variable to an accumulator. The accumulator must then contain some initial value to make the summation process semantically correct, i.e., meaningful. This initial value must be 0 in this case because we are adding the first number. We can then increase the value of the variable containing the first natural number by 1 . This next number, which is 2 in this case, can then be added to the current value of the accumulator to obtain the sum of first two natural numbers. In this way, we can continue the generation and summation process until we add up all the natural numbers, including $N$, for some given value of $\mathrm{N}$. But we must also keep a count of the numbers that are being added; otherwise we will not be able to decide whether we have added the desired $N$ numbers or not. A variable is used here as a counter. This counter must be initialized to zero first, from which we can increment its value each time by 1 when we add some number to the value of the accumulator.
The algorithm corresponding to Problem $3.6$ is shown below: Step 1. INPUT “ENTER NUMBER OF TERMS TO ADD” TO N Step 2. SUM $\leftarrow 0$ [INITIALIZATION] Step 3. I $\leftarrow 1$ [INITIALIZATION] Step 4. REPEAT STEPS 5 THROUGH 6 WHILE I <= N. Step 5. COMPUTE SUM $\leftarrow \mathrm{SUM}+\mathrm{I}$ Step 6. COMPUTE I $\leftarrow \mathrm{I}+1$ Step 7. PRINT “THE SUM IS”, SUM Step 8. STOP Problem 3.7. Draw a flowchart to show how to obtain the sum of the first 30 natural numbers.
Task Analysis. This problem is similar to Problem 3.6. The only difference is that the number of natural numbers to be added up is given as a constant (30). We do not need input from the user.
CS代写|程序设计作业代写algorithm Programming代考|We require the product of the first
Task Analysis. We require the product of the first 10 natural numbers. The natural numbers are defined in the task analysis of Problem $3.6$, so the natural numbers can be generated similarly. To hold the product, we require a location that is initialized with 1 so that we can specify how to obtain the new product by multiplying the current product by the natural number currently in use. This is because only the initial value 1 will keep the content of the location for the product unchanged when the value of the product location is multiplied by $1 .$ The algorithm showing solution to Problem $3.8$ is as follows: Step 1. PRODUCT $\leftarrow 1, \mathrm{NUM} \leftarrow 1, \mathrm{CNT} \leftarrow 0$ (Initialize the variables required) Step 2. REPEAT STEPS 3 THROUGH 5 WHILE CNT $<=10$ Step 3. COMPUTE PRODUCT $\leftarrow$ PRODUCT*NUM Step 4. COMPUTE CNT $\leftarrow \mathrm{CNT}+1$ (Increment the Counter) Step 5. COMPUTE NUM $\leftarrow \mathrm{NUM}+1$ (The next number is generated) Step 6. PRINT “THE PRODUCT IS”, PRODUCT Step 7. STOP Problem 3.9. Draw a flowchart to find the sum of first 15 even natural numbers.
Task Analysis. We know that the first natural even number is 2 and the next natural even number, i.e., the second even number, can be obtained by adding 2 to the first natural number. The successive natural even numbers can be obtained by adding 2 to the preceding natural even number. These even numbers can be accumulated in a location by adding the generated even number each time to the accumulator, which contains zero.
A count of the numbers added will enable us to check whether first 15 even natural numbers have been added up or not. No input is required from the user during the time of execution. The algorithm showing the solution of Problem 3.9. is given below: Step 1. [Initialize the accumulator, counter and variable] $\mathrm{SUMM} \leftarrow 0, \mathrm{CNT} \leftarrow 0, \mathrm{NUM} \leftarrow 2$ Step 2. REPEAT STEPS 3 THROUGH 5 WHILE CNT $<15$ Step 3. COMPUTE SUMM $\leftarrow \mathrm{SUMM}+\mathrm{NUM}$ Step 4. COMPUTE CNT $\leftarrow \mathrm{CNT}+1$ Step 5. COMPUTE NUM $\leftarrow \mathrm{NUM}+2$ Step 6. PRINT “THE DESIRED SUM IS”, SUMM Step 7. STOP
CS代写|程序设计作业代写algorithm Programming代考|The solution of Problem
Problem 3.15. Draw a flowchart to show how to find all even natural numbers that are divisible by 7 in a given range.
Task Analysis. We require two numbers that can serve as boundary values between all the desired numbers to be generated. If a number within the given range is divisible by 7 , then it is printed. As the range may include many numbers, each of the numbers need not be accepted as input from the terminal because it will slow down the whole process. We can generate natural numbers one by one based on the lower range given, and then we test the divisibility by 7 . A number is said to be divisible by 7 if it leaves no remainder when divided by 7 . The input is the numbers forming the lower and the upper ranges between which we test all the numbers, including the numbers forming the ranges. A loop is required to perform the same task of divisibility checking with a newly generated number.
Problem 3.16. Construct a flowchart to find the sum of the squares of the first 9 natural numbers that are divisible by $3 .$
Task Analysis. The problem requires the natural numbers divisible by 3 to obtain their square values and then to accumulate 9 such consecutive square values as the sum of the values.
Our procedure to obtain the sum should encompass generating natural numbers one by one, testing each for divisibility by 3 . If one is found to be divisible, we need to obtain the square of the number to determine the desired sum.
In the flowcharts of the preceding chapter, we demonstrated the sequence and selection logic structures. We now move to the iteration logic structure. The term iteration means repetition. Sometimes, a procedure should be executed repeatedly. All procedures should be built so that they can be repeated as many times as needed. We should not develop procedures to execute only once. Otherwise, calculators could be sufficient to obtain the results. An iterative logic structure is also known as a loop. Looping means repeating a set of operations to obtain a result repeatedly.
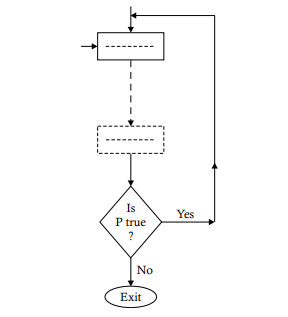
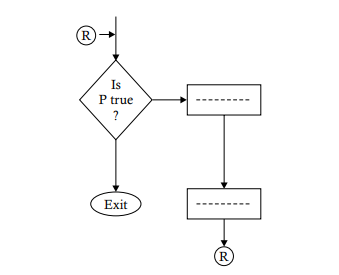
An iteration may be implemented in two ways: a pre-test iteration and post-test iteration. In case of a pre-test iteration, a predicate is tested to decide whether a set of operations is to be performed or not. If the condition implied by the predicate is true, then the desired operations are performed. If it is false, then the iteration is terminated. This is shown in the following diagram.For a post-test iteration, the predicate is tested after performing a set of operations once to decide whether to repeat the set of operations or to terminate the repetition. If the condition happens to be true, then the set of operations is repeated; otherwise, it is not repeated. The diagrammatic structure of this logic is as follows.
CS代写|程序设计作业代写algorithm Programming代考|The concept of looping
The concept of looping is demonstrated in the following flowchart. Of course, there should be a condition for normal termination. Let us assume that the repetitive task of calculating the discounts and net prices is terminated when we provide negative or zero as the price for the input. Such absurd values are justified for the termination of loops so that the procedure can remain valid for any possible value of the price. We usually use out-connectors and in-connectors with the same label to demonstrate the end point and start point of a loop. These are shown in the flowchart of Problem $2.11 .$ The algorithm corresponding to the flowchart is below: Step 1. REPEAT STEPS 2 THROUGH 6 (Start Loop) Step 2. INPUT TO P Step 3. IF $\mathrm{P} \leq 0$ THEN EXIT (Stop Repetition, i.e., transfer the control to STOP).
Step 4. If $\mathrm{P}<100$ THEN COMPUTE D $\leftarrow \mathrm{P} * 0.12$ ELSE COMPUTE D $\leftarrow \mathrm{P}^{*} 0.18$ END-IF Step 5. COMPUTE NET_PRICE $\leftarrow \mathrm{P}-\mathrm{D}$ Step 6. PRINT D, NET_PRICE (End of loop) Step 7. STOP Note that the out-connector $R$ shows the end point of the loop and the in-connector. R $R \rightarrow$ shows the start point of the loop. The operations starting from the point of the accepting the input price up to the points of printing the output discount and net price are within the loop. It could have been demonstrated without using connectors.
However, we prefer the first flowchart to the following one, because if the flowchart cannot be accommodated on a single page (or in a continuous structure on a single page), it would be difficult or impossible difficult to connect the start point and the end point.
CS代写|程序设计作业代写algorithm Programming代考|The allowances are based
Problem 3.5. The cost of living $(C L)$, the travel allowance (TA), and medical allowance (MA) of the employees of a company are decided according to the following rules: $C L=123.75 \%$ of the Basic Pay, subject to a minimum of $\$ 2,000$ and a maximum of $\$ 5,000$. TA $=57.5 \%$ of the Basic Pay, subject to a minimum of $\$ 300$. $M A=73.5 \%$ of the Basic Pay, subject to a maximum of $\$ 2,000$. Draw a flowchart to show how $C L, T A$, and MA are calculated. Task Analysis. The allowances are based on the Basic Pay of an employee. Our input will be the basic pay of the employee for whom the allowances are to be determined. The statement ” $123.75 \%$ of the basic pay subject to a minimum of $\$ 2,000$ and a maximum of $\$ 5,000 “$ implies that $123.75 \%$ of the basic bay is calculated first and then the calculated value is compared with 2,000 ; if it is less than $\$ 2,000$, then the company promises to pay $\$ 2,000$; if it is not less than $\$ 2,000$ then it will be compared with $\$ 5,000$; if it exceeds $\$ 5,000$, the company will not pay the excess amount, i.e., it agrees to pay, at most, $\$ 5,000$ : If the calculated value lies in between the two given limits, then that amount will be given as CL. Similarly, the other allowances will be determined. This is demonstrated in the flowchart given on next page.
The algorithm corresponding to the above problem has been given below: Step 1. $\mathrm{CH} \leftarrow{ }^{” \mathrm{Y}} “$ Step 2. REPEAT STEPS 3 THROUGH 14 WHILE $\mathrm{CH}=$ ” $\mathrm{Y}$ “ Step 3. INPUT TO BASIC Step 4. COMPUTE CL $\leftarrow$ BASIC* $123.75 / 100$ Step 5. IF CL $<2000$ THEN CL $\leftarrow 2000$ ELSE $\mathrm{IFCL}>5000$ THEN CL $\leftarrow 5000$ END-IF END-IF Step 6. PRINT CL Step 7. COMPUTE TA $\leftarrow$ BASIC $* 57.5 / 100$ Step 8. IF TA $<300$ THEN TA $\leftarrow 300$ END-IF
CS代写|程序设计作业代写algorithm Programming代考|This chapter deals with problems
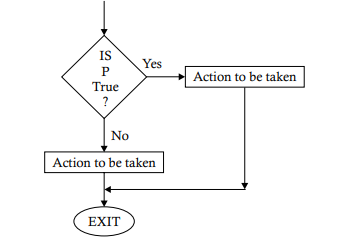
This chapter deals with problems involving decision-making. This process of decision-making is implemented through a logic structure called selection. Here a predicate, also called a condition, is tested to see if it is true or false, If it is true, a course of action is specified for it; if it is found to be false, an alternative course of action is expressed. We can express this process using flowchart notation. Note that a course of action may involve one or more sequences of operations, and there should be a common meeting point to satisfy the single rule
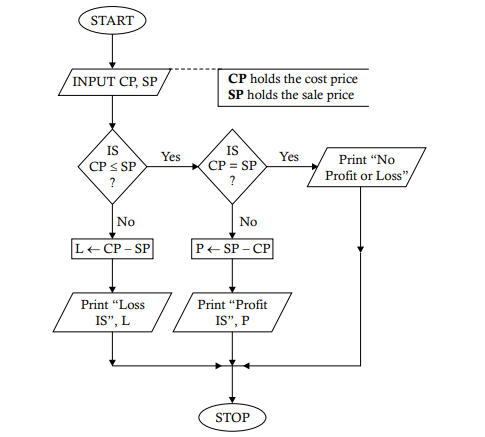
pointed to by the connector containing the word “Exit.” A flowchart may contain any number of decision boxes depending on the processing requirements, and the boxes may appear in any sequence depending on the program logic decided. For example, a number of decision boxes may follow one another. The following flowcharts provide an explanation of the logic to clarify this concept. Problem 2.1. Develop a flowchart to show how the profit or loss for a sale can be obtained.
Task Analysis. The profit or loss for a sale can be obtained if the cost price and sale price are known. However, there is a need to make a decision here. If the cost price is more than the sale price, then it indicates a loss in the process; otherwise, there will be either zero profit (no profit or a loss) or some profit.
Task Analysis. We need to calculate the sales tax first by taking one of the two given rates. For this purpose, we require two inputs: the sale price of the item under consideration and the origin of the item. Let us assume that we provide ” $\mathrm{N}$ ” or ” $\mathrm{F}$ ” as the input to indicate “national” or “foreign,” respectively. The algorithm corresponding to Problem $2.4$ is shown below: Step 1. INPUT TO SP Step 2. INPUT TO CHOICE (“N” for national and “F” for foreign) Step 3. IF CHOICE = “N” THEN COMPUTE ST $\leftarrow$ SP* $.08$ ELSE COMPUTE ST $\leftarrow \mathrm{SP} * .18$ END-IF COMPUTE NP $\leftarrow \mathrm{NP}+\mathrm{ST}$ Step 4. PRINT NP Step 5. STOP Problem 2.5. An equation with the form $a x^{2}+b x+c=0$ is known as a quadratic equation. Draw a flowchart to show how to solve a quadratic equation. Task Analysis. The values $a, b$, and $c$ in the equation represent constant values. So $4 x^{2}-17 x-15=0$ represents a quadratic equation where $a=4$, $b=-17$, and $c=-15$. The values of $x$ that satisfy a particular quadratic equation are known as the roots of the equation. The roots may be calculated by substituting the values of $a, b$, and $c$ into the following two formulas: $$ \begin{aligned} &x_{1}=\left(-b+\sqrt{b^{2}-4 a c}\right) / 2 a \ &x_{2}=\left(-b+\sqrt{b^{2}-4 a c}\right) / 2 a \end{aligned} $$ The expression $b^{2}-4 a c$ is called the determinant of the equation because it determines the nature of the roots of the equation. If the value of the determinant is less than zero, then the roots of the equation $x_{1}$ and $x_{2}$, are imaginary (complex) numbers. To solve a quadratic equation, we should allow the user to enter the values for $a, b$, and $c$. If the discriminant is less than zero, then a message should be displayed stating that the roots are imaginary; otherwise, the program should proceed to calculate and display the two roots of the equation. The algorithm corresponding to Problem $2.5$ is as follows: Step 1. INPUT TO A, B, C Step 2. COMPUTE D $\leftarrow(\mathrm{B} * \mathrm{~B}-4 * \mathrm{~A} * \mathrm{C})$ (Calculate the value of the discriminant) and store in $D$
CS代写|程序设计作业代写algorithm Programming代考|Construct flowcharts for the following problems
Construct flowcharts for the following problems: (i) Print a currency conversion table for pounds, francs, marks, and lire to dollars. (ii) Find whether a given year is a leap year. Hint. A year is said to be a leap year if it is either divisible by 4 but not by 100 or divisible by 400 . (iii) Validate a given year. Hints. The year in the date must be greater than zero, the months must lie between 1 and 12 , and the days must lie between 1 and 31 , depending on the month numbers. (iv) Show the time required by an advertising agency for its advertising program to run in Boston and on National Public Radio and to display the amount to be paid by the agency for its advertisement.
(v) Calculate the commission of a salesman when sales and the region of the sales are given as input. The commission is calculated with the rules as follows: (a) No commission, if sales $<\$ 9,000$ in Region A (b) $5.5 \%$ of sales $<\$ 7,000$ in Region B and when sales $<\$ 13,000$ in Region A (c) $7.5 \%$ of sales when sales $>=\$ 14,000$ in Region A and when sales $>$ $=\$ 13,000$ in Region B. (vi) Accept three integers representing the angles of a triangle in degrees to determine whether they form a valid set of angles of a triangle. If it is not a valid set, then generate a message and terminate the process. If it is a valid set, then the process determines whether it is equiangular (all three angles are the same). It also determines if the triangle is right angled (has one angle with 90 degrees), obtuse angled (one angle above $90)$, or acute angled (all three angles are below 90 degrees). Finally, it shows conclusion about the triangle. (vii) Accept the lengths of the three sides of a triangle to validate whether they can be the sides of a triangle and then classify the triangle as equilateral (all three sides are equal), scalene (all three sides are different), or isosceles (exactly two sides are equal), and then to see whether it is a right angled triangle (the sum of the squares of two sides is equal to the square of the third side.)
Hint. Three numbers are valid as the sides of a triangle if each one is positive and the sum of every two numbers is greater than the third.
(v) 当销售额和销售区域作为输入时,计算推销员的佣金。佣金的计算规则如下: (a) 没有佣金,如果销售<$9,000在 A 区 (b)5.5%销售额<$7,000在 B 区和销售时<$13,000在 A 区 (c)7.5%销售时的销售>=$14,000在 A 区和销售时> =$13,000在区域 B 中。 (vi) 接受以度为单位表示三角形角度的三个整数,以确定它们是否构成三角形的一组有效角度。如果它不是有效集合,则生成一条消息并终止该过程。如果它是一个有效集合,则该过程确定它是否是等角的(所有三个角都相同)。它还确定三角形是直角(有一个角与 90 度角),钝角(一个角在上面90),或锐角(所有三个角度都低于 90 度)。最后,它显示了关于三角形的结论。 (vii) 接受三角形三边的长度以验证它们是否可以是三角形的边,然后将三角形分类为等边(三边相等)、不等边(三边都不同)或等腰三角形(正好两条边相等),然后看是否是直角三角形(两条边的平方和等于第三条边的平方。)
CS代写|程序设计作业代写algorithm Programming代考|INTRODUCTION TO PROGRAMMING
CS代写|程序设计作业代写algorithm Programming代考|FLOWCHARTING AND ALGORITHMS
A computer program is a sequential set of instructions written in a computer language that is used to direct the computer to perform a specific task of computation.
Observe that the definition demands that any set of instructions must be such that the tasks will usually be performed sequentially unless directed otherwise. Each instruction in the set will express a unit of work that a computer language can support. In general, high level languages, also known as 3GLs, support one human activity at a time. For example, if a computational task involves the determination of the average of three numbers, then it will require at least three human activities, viz., getting the numbers, obtaining the sum of the numbers, and then obtaining the average. The process will therefore require three instructions in a computer language. However, it can be done using two instructions, also: first by obtaining the numbers and second by obtaining the sum and the average.
The objective of programming is to solve problems using computers quickly and accurately.
CS代写|程序设计作业代写algorithm Programming代考|A problem is something the result of which is not readily available
A problem is something the result of which is not readily available. A set of steps involving arithmetic computation and/or logical manipulation is required to obtain the desired result. There is a law called the law of equifinality that states that the same goal can be achieved through different courses of action and a variety of paths, so the same result can be derived in a number of ways. For example, consider the task of sending a message to one of your friends. There are many ways in which this can be done. First, you can convey the message over the phone if your friend possesses a phone. Second, you can send it by post. Third, you can send it through a courier service. If the message is urgent, then you can try to use the quickest means for sending it. If it is not urgent, then you will choose to send it in the least expensive but most reliable way of doing it. Depending upon the urgency, you will decide the most effective way of doing it. This most effective way is called the optimum way. The different ways of solving a problem are called solution strategies. The optimum way of solving a problem to get the desired result can be achieved by analyzing different strategies for the solution and then selecting the way that can yield the result in the least time using the minimum amount of resources. The selection process will depend on the efficiency of the person and his/her understanding of the problem. He/she must also be familiar with different problem-solving techniques. Determining the set of steps required to solve a given problem is an art. It shows how well a person can arrange a set of steps so that others can follow it. A type of analysis called task analysis is required to reach the solution from a problem definition that states what is to be achieved.
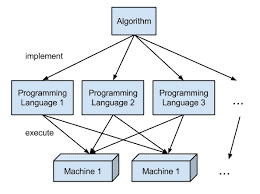
A set of steps that generates a finite sequence of elementary computational operations leading to the solution of a given problem is called an algorithm. An algorithm may be too verbose to follow. The textual description of an algorithm may not be understood quickly and easily. This is why a pictorial representation may be used as a substitute for an algorithm. Such a pictorial representation is called a flowchart. Formally speaking, a flowchart is a diagrammatic representation of the steps of an algorithm. In a flowchart, boxes of different shapes are used to denote different types of operations. These boxes are then connected by lines with arrows denoting the flow or direction to which one should proceed to know the next step. The connecting lines are known as flow lines. Flowcharts may be classified into two categories: (i) Program Flowchart (ii) System Flowchart
Program flowcharts act like mirrors of computer programs in terms of flowcharting symbols. They contain the steps of solving a problem unit for a specific result.
System flowcharts contain the solutions of many problem units together that are closely related to each other and interact with each other to achieve a goal. We will first focus on program flowcharts.
A program flowchart is an extremely useful tool in program development. First, any error or omission can be more easily detected from a program flowchart than it can be from a program because a program flowchart is a pictorial representation of the logic of a program. Second, a program flowchart can be followed easily and quickly. Third, it serves as a type of documentation, which may be of great help if the need for program modification arises in future. The following five rules should be followed while creating program flowcharts.
Only the standard symbols should be used in program flowcharts.
The program logic should depict the flow from top to bottom and from left to right.
Each symbol used in a program flowchart should contain only one entry point and one exit point, with the exception of the decision symbol. This is known as the single rule.
The operations shown within a symbol of a program flowchart should be expressed independently of any particular programming language.
All decision branches should be well-labeled. The following are the standard symbols used in program flowcharts:
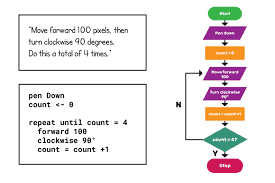
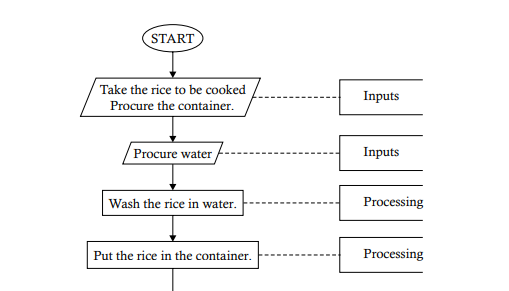
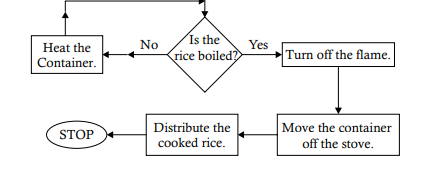
Flowcharts can be used to show the sequence of steps for doing any job. A set of simple operations involving accepting inputs, performing arithmetic operation on the inputs, and showing them to the users demonstrate the sequence logic structure of a program. The following flowchart shows the steps in cooking rice and then utilizing the cooked rice. The algorithm for the flowchart about cooking rice is as follows: Step 1. Take the rice to be cooked. Step 2. Procure the container. Step 3. Procure the water. Step 4. Wash the rice in the water. Step 5. Put the rice into the container. Step 6. Pour water into the container. Step 7. IF WATER LEVEL = I INCH ABOVE THE RICE THEN GOTO STEP 8 ELSE GOTO STEP 6 ENDIF
CS代写|程序设计作业代写algorithm Programming代考|INTRODUCTION TO PROGRAMMING
生成有限序列的基本计算操作以解决给定问题的一组步骤称为算法。算法可能过于冗长而无法遵循。算法的文字描述可能无法快速轻松地理解。这就是为什么图形表示可以用作算法的替代品。这样的图形表示称为流程图。从形式上讲,流程图是算法步骤的图解表示。在流程图中,不同形状的方框用于表示不同类型的操作。然后将这些框通过带有箭头的线连接起来,箭头表示人们应该继续了解下一步的流程或方向。连接线称为流线。流程图可以分为两类: (i) 程序流程图 (ii) 系统流程图