计算机代写|C++作业代写C++代考|Small Overhead, Big Benefits for C++
如果你也在 怎样代写C++这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
C++ 是一种高级语言,它是由Bjarne Stroustrup 于1979 年在贝尔实验室开始设计开发的。 C++ 进一步扩充和完善了C 语言,是一种面向对象的程序设计语言。 C++ 可运行于多种平台上,如Windows、MAC 操作系统以及UNIX 的各种版本。
statistics-lab™ 为您的留学生涯保驾护航 在代写C++方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写C++代写方面经验极为丰富,各种代写C++相关的作业也就用不着说。
我们提供的C++及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
计算机代写|C++作业代写C++代考|Big Benefits for C++
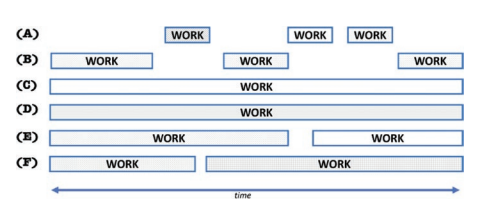
We do not mean to make too big a deal about performance loss, nor do we wish to deny it. For simple C++ code written in a “Fortran” style, with a single layer of wellbalanced parallel loops, the dynamic nature of TBB may not be needed at all. However, the limitations of such a coding style are an important factor in why TBB exists. TBB was designed to efficiently support nested, concurrent, and sequential composition of parallelism and to dynamically map this parallelism on to a target platform. Using a composable library like TBB, developers can build applications by combining components and libraries that contain parallelism without worrying that they will negatively interfere with each other. Importantly, TBB does not require us to restrict the parallelism we express to avoid performance problems. For large, complicated applications using $\mathrm{C}++$, TBB is therefore easy to recommend without disclaimers.
The TBB library has evolved over the years to not only adjust to new platforms but also to demands from developers that want a bit more control over the choices the library makes in mapping parallelism to the hardware. While TBB $1.0$ had very few performance controls for users, TBB 2019 has quite a few more – such as affinity controls,
constructs for work isolation, hooks that can be used to pin threads to cores, and so on. The developers of TBB worked hard to design these controls to provide just the right level of control without sacrificing composability.
The interfaces provided by the library are nicely layered – TBB provides high-level templates that suit the needs of most programmers, focusing on common cases. But it also provides low-level interfaces so we can drill down and create tailored solutions for our specific applications if needed. TBB has the best of both worlds. We typically rely on the default choices of the library to get great performance but can delve into the details if we need to.
计算机代写|C++作业代写C++代考|Evolving Support for Parallelism in TBB and C++
Both the TBB library and the $\mathrm{C}++$ language have evolved significantly since the introduction of the original TBB. In $2006, C_{++}$had no language support for parallel programming, and many libraries, including the Standard Template Library (STL), were not easily used in parallel programs because they were not thread-safe.
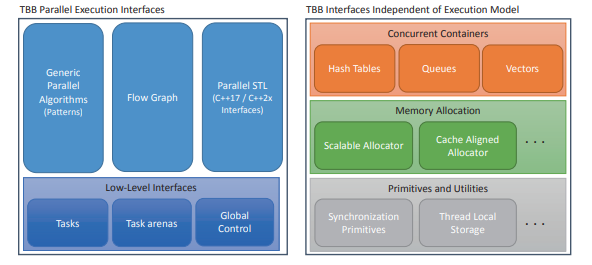
The $\mathrm{C}++$ language committee has been busy adding features for threading directly to the language and its accompanying Standard Template Library (STL). Figure 1-1 shows new and planned $\mathrm{C}_{++}$features that address parallelism. Even though we are big fans of TBB, we would in fact prefer if all of the fundamental support needed for parallelism is in the $\mathrm{C}++$ language itself. That would allow TBB to utilize a consistent foundation on which to build higher-level parallelism abstractions. The original versions of TBB had to address a lack of $\mathrm{C}++$ language support, and this is an area where the $\mathrm{C}++$ standard has grown significantly to fill the foundational voids
that TBB originally had no choice but to fill with features such as portable locks and atomics. Unfortunately, for $\mathrm{C}_{++}$developers, the standard still lacks features needed for full support of parallel programming. Fortunately, for readers of this book, this means that TBB is still relevant and essential for effective threading in $\mathrm{C}++$ and will likely stay relevant for many years to come.
It is very important to understand that we are not complaining about the $\mathrm{C}++$ standard process. Adding features to a language standard is best done very carefully, with careful review. The $\mathrm{C}++11$ standard committee, for instance, spent huge energy on a memory model. The significance of this for parallel programming is critical for every library that builds upon the standard. There are also limits to what a language standard should include, and what it should support. We believe that the tasking system and the flow graph system in TBB is not something that will directly become part of a language standard. Even if we are wrong, it is not something that will happen anytime soon.
计算机代写|C++作业代写C++代考|Recent C++ Additions for Parallelism
As shown in Figure 1-1, the $\mathrm{C}++11$ standard introduced some low-level, basic building blocks for threading, including std: : async, std:: future, and std:: thread. It also introduced atomic variables, mutual exclusion objects, and condition variables. These extensions require programmers to do a lot of coding to build up higher-level abstractions – but they do allow us to express basic parallelism directly in $\mathrm{C}++$. The C++11 standard was a clear improvement when it comes to threading, but it doesn’t provide us with the high-level features that make it easy to write portable, efficient parallel code. It also does not provide us with tasks or an underlying work-stealing task scheduler.
The $\mathrm{C}++17$ standard introduced features that raise the level of abstraction above these low-level building blocks, making it easier for us to express parallelism without having to worry about every low-level detail. As we discuss later in this book, there are still some significant limitations, and so these features are not yet sufficiently expressive or performant – there’s still a lot of work to do in the $\mathrm{C}++$ standard.
The most pertinent of these $\mathrm{C}++17$ additions are the execution policies that can be used with the Standard Template Library (STL) algorithms. These policies let us choose whether an algorithm can be safely parallelized, vectorized, parallelized and vectorized, or if it needs to retain its original sequenced semantics. We call an STL implementation that supports these policies a Parallel STL.
Looking into the future, there are proposals that might be included in a future $\mathrm{C}_{++}$ standard with even more parallelism features, such as resumable functions, executors, task blocks, parallel for loops, SIMD vector types, and additional execution policies for the STL algorithms.
C++/C代写
计算机代写|C++作业代写C++代考|Big Benefits for C++
我们无意在性能损失方面做太多,也不想否认。对于以“Fortran”风格编写的简单 C++ 代码,具有单层平衡良好的并行循环,可能根本不需要 TBB 的动态特性。然而,这种编码风格的局限性是 TBB 存在的一个重要因素。TBB 旨在有效地支持并行的嵌套、并发和顺序组合,并将这种并行动态映射到目标平台。使用像 TBB 这样的可组合库,开发人员可以通过组合包含并行性的组件和库来构建应用程序,而不必担心它们会相互干扰。重要的是,TBB 不需要我们限制我们表达的并行性以避免性能问题。对于大型、复杂的应用程序,使用C++, TBB 因此很容易在没有免责声明的情况下推荐。
TBB 库多年来不断发展,不仅可以适应新平台,还可以满足开发人员的需求,这些开发人员希望更好地控制库在将并行性映射到硬件时所做的选择。虽然待定1.0对用户的性能控制很少,TBB 2019 有更多——比如亲和力控制,
用于工作隔离的构造、可用于将线程固定到核心的钩子等等。TBB 的开发人员努力设计这些控件,以便在不牺牲可组合性的情况下提供恰到好处的控制级别。
库提供的接口很好地分层——TBB 提供了满足大多数程序员需求的高级模板,专注于常见情况。但它也提供了低级接口,因此如果需要,我们可以深入研究并为我们的特定应用程序创建量身定制的解决方案。TBB 拥有两全其美的优势。我们通常依靠库的默认选择来获得出色的性能,但如果需要,可以深入研究细节。
计算机代写|C++作业代写C++代考|Evolving Support for Parallelism in TBB and C++
TBB 库和C++自最初的 TBB 引入以来,语言已经发生了显着变化。在2006,C++没有对并行编程的语言支持,包括标准模板库 (STL) 在内的许多库都不容易在并行程序中使用,因为它们不是线程安全的。
这C++语言委员会一直忙于向语言及其随附的标准模板库 (STL) 添加用于直接线程化的功能。图 1-1 显示了新的和计划的C++解决并行性的功能。尽管我们是 TBB 的忠实拥护者,但事实上,如果并行性所需的所有基本支持都在C++语言本身。这将允许 TBB 使用一致的基础来构建更高级别的并行抽象。TBB 的原始版本必须解决缺乏C++语言支持,这是一个领域C++标准已显着增长以填补基础空白
TBB 原本别无选择,只能填充便携式锁和原子锁等功能。不幸的是,对于C++开发人员,该标准仍然缺乏完全支持并行编程所需的功能。幸运的是,对于本书的读者来说,这意味着 TBB 对于有效的线程化仍然是相关的和必不可少的。C++并且可能会在未来很多年保持相关性。
了解我们不是在抱怨C++标准流程。向语言标准添加功能最好非常小心,并仔细审查。这C++11例如,标准委员会在内存模型上花费了大量精力。这对于并行编程的重要性对于每个基于该标准的库来说都是至关重要的。语言标准应该包括什么以及它应该支持什么也有限制。我们相信 TBB 中的任务系统和流程图系统不会直接成为语言标准的一部分。即使我们错了,也不会很快发生。
计算机代写|C++作业代写C++代考|Recent C++ Additions for Parallelism
如图 1-1 所示,C++11标准引入了一些低级的、基本的线程构建块,包括 std::async、std::future 和 std::thread。它还引入了原子变量、互斥对象和条件变量。这些扩展需要程序员进行大量编码来构建更高级别的抽象——但它们确实允许我们直接在C++. C++11 标准在线程方面有了明显的改进,但它没有为我们提供易于编写可移植、高效的并行代码的高级特性。它也没有为我们提供任务或底层工作窃取任务调度程序。
这C++17标准引入了将抽象级别提高到这些低级构建块之上的特性,使我们更容易表达并行性,而不必担心每个低级细节。正如我们在本书后面讨论的那样,仍然存在一些明显的限制,因此这些功能还没有足够的表现力或性能——在C++标准。
其中最相关的C++17附加是可以与标准模板库 (STL) 算法一起使用的执行策略。这些策略让我们选择一个算法是否可以安全地并行化、向量化、并行化和向量化,或者它是否需要保留其原始的序列语义。我们将支持这些策略的 STL 实现称为并行 STL。
展望未来,未来可能会包含一些提案C++具有更多并行特性的标准,例如可恢复函数、执行器、任务块、并行 for 循环、SIMD 向量类型以及 STL 算法的附加执行策略。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。