如果你也在 怎样代写C++这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
C++ 是一种高级语言,它是由Bjarne Stroustrup 于1979 年在贝尔实验室开始设计开发的。 C++ 进一步扩充和完善了C 语言,是一种面向对象的程序设计语言。 C++ 可运行于多种平台上,如Windows、MAC 操作系统以及UNIX 的各种版本。
statistics-lab™ 为您的留学生涯保驾护航 在代写C++方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写C++代写方面经验极为丰富,各种代写C++相关的作业也就用不着说。
我们提供的C++及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
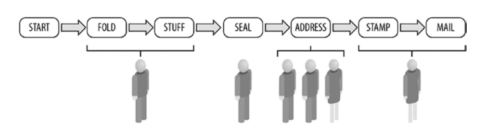
计算机代写|C++作业代写C++代考|Achieving Parallelism
Coordinating people around the job of preparing and mailing the envelopes is easily expressed by the following two conceptual steps:
- Assign people to tasks (and feel free to move them around to balance the workload).
- Start with one person on each of the six tasks but be willing to split up a given task so that two or more people can work on it together.
The six tasks are folding, stuffing, sealing, addressing, stamping, and mailing. We also have six people (resources) to help with the work. That is exactly how TBB works best: we define tasks and data at a level we can explain and then split or combine data to match up with resources available to do the work.
The first step in writing a parallel program is to consider where the parallelism is. Many textbooks wrestle with task and data parallelism as though there were a clear choice. TBB allows any combination of the two that we express. If we are lucky, our program will have an abundant amount of data parallelism available for us to exploit. To simplify this work, TBB requires only that we specify tasks and how to split them. For a completely data-parallel task, in TBB we will define one task to which we give all the data. That task will then be split up automatically
to use the available hardware parallelism. The implicit synchronization (as opposed to synchronization we directly ask for with coding) will often eliminate the need for using locks to achieve synchronization. Referring back to our enemies list, and the fact that we hate locks, the implicit synchronization is a good thing. What do we mean by “implicit” synchronization? Usually, all we are saying is that synchronization occurred but we did not explicitly code a synchronization. At first, this should seem like a “cheat.” After all, synchronization still happened – and someone had to ask for it! In a sense, we are counting on these implicit synchronizations being more carefully planned and implemented. The more we can use the standard methods of TBB, and the less we explicitly write our own locking code, the better off we will be – in general.
By letting TBB manage the work, we hand over the responsibility for splitting up the work and synchronizing when needed. The synchronization done by the library for us, which we call implicit synchronization, in turn often eliminates the need for an explicit coding for synchronization (see Chapter 5 ).
We strongly suggest starting there, and only venturing into explicit synchronization (Chapter 5 ) when absolutely necessary or beneficial. We can say, from experience, even when such things seem to be necessary – they are not. You’ve been warned. If you are like us, you’ll ignore the warning occasionally and get burned. We have.
People have been exploring decomposition for decades, and some patterns have emerged. We’ll cover this more later when we discuss design patterns for parallel programming.
计算机代写|C++作业代写C++代考|Terminology: Scaling and Speedup
The scalability of a program is a measure of how much speedup the program gets as we add more computing capabilities. Speedup is the ratio of the time it takes to run a program without parallelism vs. the time it takes to run in parallel. A speedup of $4 \times$ indicates that the parallel program runs in a quarter of the time of the serial program. An example would be a serial program that takes 100 seconds to run on a one-processor machine and 25 seconds to run on a quad-core machine.
As a goal, we would expect that our program running on two processor cores should run faster than our program running on one processor core. Likewise, running on four processor cores should be faster than running on two cores.
Any program will have a point of diminishing returns for adding parallelism. It is not uncommon for performance to even drop, instead of simply leveling off, if we force the use of too many compute resources. The granularity at which we should stop subdividing a problem can be expressed as a grain size. TBB uses a notion of grain size to help limit the splitting of data to a reasonable level to avoid this problem of dropping in performance. Grain size is generally determined automatically, by an automatic partitioner within TBB, using a combination of heuristics for an initial guess and dynamic refinements as execution progresses. However, it is possible to explicitly manipulate the grain size settings if we want to do so. We will not encourage this in this book, because we seldom will do better in performance with explicit specifications than the automatic partitioner in TBB, it tends to be somewhat machine specific, and therefore explicitly setting grain size reduces performance portability.
As Thinking Parallel becomes intuitive, structuring problems to scale will become second nature.
计算机代写|C++作业代写C++代考|Amdahl’s Law
Renowned computer architect, Gene Amdahl, made observations regarding the maximum improvement to a computer system that can be expected when only a portion of the system is improved. His observations in 1967 have come to be known as Amdahl’s Law. It tells us that if we speed up everything in a program by $2 x$, we can expect the
resulting program to run $2 \times$ faster. However, if we improve the performance of only $2 / 5$ th of the program by $2 \times$, the overall system improves only by $1.25 \times$.
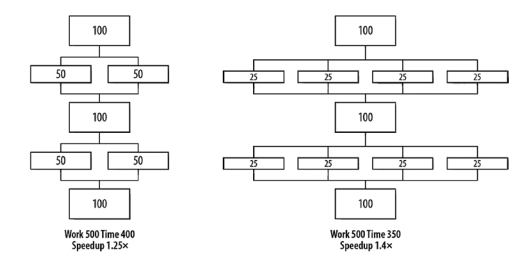
Amdahl’s Law is easy to visualize. Imagine a program, with five equal parts, that runs in 500 seconds, as shown in Figure P-10. If we can speed up two of the parts by $2 \times$ and $4 \times$, as shown in Figure P-11, the 500 seconds are reduced to only 400 (1.25 × speedup) and 350 seconds (1.4× speedup), respectively. More and more, we are seeing the limitations of the portions that are not speeding up through parallelism. No matter how many processor cores are available, the serial portions create a barrier at 300 seconds that will not be broken (see Figure P-12) leaving us with only $1.7 \times$ speedup. If we are limited to parallel programming in only $2 / 5$ th of our execution time, we can never get more than a $1.7 \times$ boost in performance!
C++/C代写
计算机代写|C++作业代写C++代考|Achieving Parallelism
在准备和邮寄信封的工作中协调人们很容易通过以下两个概念性步骤来表达:
- 将人员分配给任务(并随意调动他们以平衡工作量)。
- 从一个人开始处理六项任务中的每一项,但愿意将给定的任务分开,以便两个或更多人可以一起工作。
这六项任务是折叠、填充、密封、寻址、盖章和邮寄。我们还有六个人(资源)来帮助工作。这正是 TBB 的最佳工作方式:我们在可以解释的级别定义任务和数据,然后拆分或组合数据以匹配可用于完成工作的资源。
编写并行程序的第一步是考虑并行性在哪里。许多教科书都在与任务和数据并行性作斗争,好像有一个明确的选择。TBB 允许我们表达的两者的任意组合。如果幸运的话,我们的程序将有大量的数据并行性可供我们利用。为了简化这项工作,TBB 只需要我们指定任务以及如何拆分它们。对于完全数据并行的任务,在 TBB 中,我们将定义一个任务,我们将向其提供所有数据。然后该任务将自动拆分
使用可用的硬件并行性。隐式同步(与我们直接通过编码要求的同步相反)通常会消除使用锁来实现同步的需要。回顾我们的敌人列表,以及我们讨厌锁的事实,隐式同步是一件好事。“隐式”同步是什么意思?通常,我们所说的只是发生了同步,但我们没有明确编码同步。起初,这应该看起来像是一个“作弊”。毕竟,同步仍然发生了——而且必须有人提出要求!从某种意义上说,我们指望这些隐式同步得到更仔细的计划和实施。我们越能使用 TBB 的标准方法,越少地显式编写自己的锁定代码,我们就会越好——总的来说。
通过让 TBB 管理工作,我们移交了拆分工作并在需要时进行同步的责任。库为我们完成的同步,我们称之为隐式同步,反过来通常消除了对同步的显式编码的需要(参见第 5 章)。
我们强烈建议从那里开始,并且仅在绝对必要或有益时才尝试显式同步(第 5 章)。根据经验,我们可以说,即使这些事情似乎是必要的——它们不是。你已经被警告过了。如果您像我们一样,偶尔会忽略警告并被烧毁。我们有。
几十年来,人们一直在探索分解,并出现了一些模式。稍后我们将在讨论并行编程的设计模式时详细介绍这一点。
计算机代写|C++作业代写C++代考|Terminology: Scaling and Speedup
程序的可扩展性是衡量程序在我们添加更多计算能力时获得多少加速的量度。加速比是在没有并行性的情况下运行程序所需的时间与并行运行所需的时间之比。一个加速4×表示并行程序的运行时间是串行程序的四分之一。例如,一个串行程序在单处理器机器上运行需要 100 秒,在四核机器上运行需要 25 秒。
作为一个目标,我们希望在两个处理器内核上运行的程序应该比在一个处理器内核上运行的程序运行得更快。同样,在四个处理器内核上运行应该比在两个内核上运行更快。
任何程序都会有一个增加并行性的收益递减点。如果我们强制使用过多的计算资源,性能甚至会下降,而不是简单地趋于平稳,这种情况并不少见。我们应该停止细分问题的粒度可以表示为粒度。TBB 使用粒度概念来帮助将数据拆分限制在合理的水平,以避免性能下降的问题。粒度通常由 TBB 中的自动分区器自动确定,结合使用启发式算法进行初始猜测和执行过程中的动态细化。但是,如果我们愿意,可以显式地操纵粒度设置。我们不会在本书中鼓励这样做,
随着平行思考变得直观,按比例构建问题将成为第二天性。
计算机代写|C++作业代写C++代考|Amdahl’s Law
著名的计算机架构师 Gene Amdahl 对计算机系统的最大改进进行了观察,如果只改进系统的一部分,则可以预期这种改进。他在 1967 年的观察被称为阿姆达尔定律。它告诉我们,如果我们通过以下方式加速程序中的所有内容2X,我们可以期待
结果程序运行2×快点。但是,如果我们只提高2/5该计划的第2×,整个系统仅通过以下方式改进1.25×.
阿姆达尔定律很容易形象化。想象一个程序,有五个相等的部分,在 500 秒内运行,如图 P-10 所示。如果我们可以通过以下方式加速其中的两个部分2×和4×,如图 P-11 所示,500 秒分别减少到仅 400(1.25 倍加速)和 350 秒(1.4 倍加速)。越来越多的,我们看到了没有通过并行加速的部分的局限性。无论有多少可用的处理器内核,串行部分都会在 300 秒时创建一个不会被打破的屏障(参见图 P-12),我们只剩下1.7×加速。如果我们仅限于并行编程2/5th 我们的执行时间,我们永远不能得到超过1.7×性能提升!

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。