数学代写|概率论代写Probability theory代考|RELATION TO THE POISSON APPROXIMATION
如果你也在 怎样代写概率论Probability Theory 这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。概率论Probability Theory作为统计学的数学基础,对许多涉及数据定量分析的人类活动至关重要。概率论的方法也适用于对复杂系统的描述,只对其状态有部分了解,如在统计力学或顺序估计。二十世纪物理学的一个伟大发现是量子力学中描述的原子尺度的物理现象的概率性质。
概率论Probability Theory Math37500的核心课题包括离散和连续随机变量、概率分布和随机过程(为非决定性或不确定的过程或测量量提供数学抽象,这些过程或测量量可能是单一发生的,或以随机方式随时间演变)。尽管不可能完美地预测随机事件,但对它们的行为可以有很多说法。概率论中描述这种行为的两个主要结果是大数法则和中心极限定理。概率论是与概率有关的数学分支。虽然有几种不同的概率解释,但概率论以严格的数学方式处理这一概念,通过一组公理来表达它。
statistics-lab™ 为您的留学生涯保驾护航 在代写概率论Probability theory方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写概率论Probability theory代写方面经验极为丰富,各种代写概率论Probability theory相关的作业也就用不着说。
数学代写|概率论代写Probability theory代考|RELATION TO THE POISSON APPROXIMATION
The error of the normal approximation will be small if $n p q$ is large. On the other hand, if $n$ is large and $p$ small, the terms $b(k ; n, p)$ will be found to be near the Poisson probabilities $p(k ; \lambda)$ with $\lambda=n p$. For small $\lambda$ only the Poisson approximation can be used, but for large $\lambda$ we can use either the normal or the Poisson approximation. This implies that for large values of $\lambda$ it must be possible to approximate the Poisson distribution by the normal distribution, and in example X, (1.c) we shall see that this is indeed so (cf. also problem 9). Here we shall be content to illustrate the point by a numerical and a practical example.
Examples. (a) The Poisson distribution with $\lambda=100$ attributes to the set of integers $a, a+1, \ldots, b$ the probability
$$
P(a, b)=p(a ; 100)+p(a+1 ; 100)+\cdots+p(b ; 100) .
$$
This Poisson distribution may be considered as an approximation to the binomial distribution with $n=100,000,000$ and $p=10^{-6}$. Then $n p q \approx 100$ and so it is not far-fetched to approximate this binomial distribution by the normal, at least for values close to the central term 100 . But this means that $P(a, b)$ is being approximated by
$$
\mathfrak{N}((b-99.5) / 10)-\mathfrak{N}((a-100.5) / 10) .
$$
The following sample gives an idea of the degree of approximation.
$\begin{array}{lcc} & \text { Correct values } & \text { Normal approximation } \ P(85,90) & 0.11384 & 0.11049 \ P(90,95) & 0.18485 & 0.17950 \ P(95,105) & 0.41763 & 0.41768 \ P(90,110) & 0.70652 & 0.70628 \ P(110,115) & 0.10738 & 0.11049 \ P(115,120) & 0.05323 & 0.05335\end{array}$
(b) A telephone trunking problem. The following problem is, with some simplifications, taken from actual practice. ${ }^8$ A telephone exchange $A$ is to serve 2000 subscribers in a nearby exchange $B$. It would be too expensive and extravagant to install 2000 trunklines from $A$ to $B$. It suffices to make the number $N$ of lines so large that, under ordinary conditions, only one out of every hundred calls will fail to find an idle trunkline immediately at its disposal. Suppose that during the busy hour of the day each subscriber requires a trunkline to $B$ for an average of 2 minutes. At a fixed moment of the busy hour we compare the situation to a set of 2000 trials with a probability $p=\frac{1}{30}$ in each that a line will be required. Under ordinary conditions these trials can be assumed to be independent (although this is not true when events like unexpected showers or earthquakes cause many people to call for taxicabs or the local newspaper; the theory no longer applies, and the trunks will be “jammed”). We have, then, 2000 Bernoulli trials with $p=\frac{1}{30}$, and the smallest number $N$ is required such that the probability of more than $N$ “successes” will be smaller than 0.01 ; in symbols $\mathbf{P}\left{\mathbf{S}_{2000} \geq N\right}<0.01$.
数学代写|概率论代写Probability theory代考|LARGE DEVIATIONS
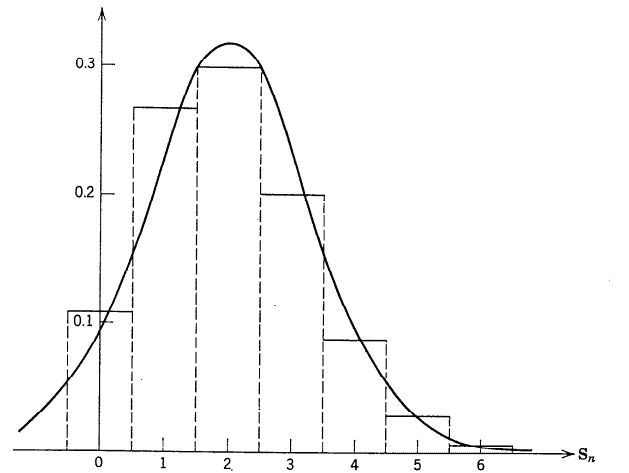
The DeMoivre-Laplace theorem describes the asymptotic behavior of $\mathbf{P}\left{z_1<\mathbf{S}_n^>z_1$. This is justified by the following lemma, which shows that when $z_1 \rightarrow \infty$ the upper limit $z_2$ plays no role. Lemma. If $x_n \rightarrow \infty$ then for every fixed $\eta>0$ $$ \frac{\mathbf{P}\left{\mathbf{S}_n^>x_n+\eta\right}}{\mathbf{P}\left{\mathbf{S}_n^>x_n\right}} \rightarrow 0 $$ that is, $$ \mathbf{P}\left{x_n<\mathbf{S}_n^ \leq x_n+\eta\right} \sim \mathbf{P}\left{\mathbf{S}_n^>x_n\right} . $$ In other words: When $\mathbf{S}_n^$ exceeds $x_n$ it is likely to be very close to $x_n$, and larger values play no role in the limit.
Proof. With the notation (3.2) for the binomial distribution we have
$$
\mathbf{P}\left{\mathbf{S}n^>x_n\right}=\sum{v=0}^{\infty} a_{r_n+v}, \quad \mathbf{P}\left{\mathbf{S}n^>x_n+\eta\right}=\sum{v=0}^{\infty} a_{s_n+v},
$$
where $r_n$ and $s_n$ are integers that differ at most by one unit from $x_n \sqrt{n p q}$ and $\left(x_n+\eta\right) \sqrt{n p q}$, respectively. Now it is obvious from (3.4)
that for large $n$
$$
\frac{a_{k+1}}{a_k}<1-p t_k<1-\frac{k}{n}<e^{k / n},
$$
and hence
$$
\frac{a_{s_n+v}}{a_{r_n+v}}<e^{-\left(s_n-r_n\right) r_n / n}<e^{-\frac{1}{2} \eta x_n p q} .
$$
By assumption $x_n \rightarrow \infty$, and so the terms of the second series in (6.3) tend to become negligible in comparison with the corresponding terms of the first series.
概率论代考
数学代写|概率论代写Probability theory代考|RELATION TO THE POISSON APPROXIMATION
如果$n p q$较大,则正态近似的误差较小。另一方面,如果$n$较大,$p$较小,则发现$b(k ; n, p)$项与$\lambda=n p$接近泊松概率$p(k ; \lambda)$。对于小的$\lambda$,只能使用泊松近似,但是对于大的$\lambda$,我们可以使用正态或泊松近似。这意味着,对于较大的$\lambda$值,一定可以用正态分布来近似泊松分布,在例X, (1.c)中,我们将看到确实是这样(同样参见问题9)。在这里,我们将满足于用一个数值和一个实际的例子来说明这一点。
例子。(a)具有$\lambda=100$属性的泊松分布为整数集$a, a+1, \ldots, b$的概率
$$
P(a, b)=p(a ; 100)+p(a+1 ; 100)+\cdots+p(b ; 100) .
$$
这种泊松分布可以看作是$n=100,000,000$和$p=10^{-6}$的二项分布的近似。然后是$n p q \approx 100$所以用正态分布近似这个二项分布并不牵强,至少对于接近中心项100的值。但这意味着$P(a, b)$被近似为
$$
\mathfrak{N}((b-99.5) / 10)-\mathfrak{N}((a-100.5) / 10) .
$$
下面的示例给出了近似程度的概念。
$\begin{array}{lcc} & \text { Correct values } & \text { Normal approximation } \ P(85,90) & 0.11384 & 0.11049 \ P(90,95) & 0.18485 & 0.17950 \ P(95,105) & 0.41763 & 0.41768 \ P(90,110) & 0.70652 & 0.70628 \ P(110,115) & 0.10738 & 0.11049 \ P(115,120) & 0.05323 & 0.05335\end{array}$
(b)电话干线问题。下面的问题经过一些简化,是根据实际情况提出的。${ }^8$电话交换机$A$将为附近交换机$B$的2000名用户提供服务。安装2000条从$A$到$B$的干线太昂贵和奢侈了。它足以使线路数量$N$如此之大,以至于在通常情况下,每100个呼叫中只有一个不能立即找到空闲的干线供其使用。假设在一天的繁忙时段,每个用户平均需要2分钟的主干线路到$B$。在繁忙时段的一个固定时刻,我们将这种情况与一组2000次试验进行比较,每次试验需要一条线路的概率为$p=\frac{1}{30}$。在一般情况下,这些试验可以被认为是独立的(尽管当诸如意外的阵雨或地震等事件导致许多人要求出租车或当地报纸时,情况并非如此;这个理论不再适用,后备箱将被“卡住”)。然后,我们有2000次伯努利试验$p=\frac{1}{30}$,并且需要最小的数字$N$,以便超过$N$的“成功”概率将小于0.01;用符号$\mathbf{P}\left{\mathbf{S}_{2000} \geq N\right}<0.01$表示。
数学代写|概率论代写Probability theory代考|LARGE DEVIATIONS
DeMoivre-Laplace定理描述了$\mathbf{P}\left{z_1<\mathbf{S}_n^>z_1$的渐近行为。下面的引理证明了这一点,即当$z_1 \rightarrow \infty$上限$z_2$不起作用时。引理。如果$x_n \rightarrow \infty$,那么对于每个固定的$\eta>0$$$ \frac{\mathbf{P}\left{\mathbf{S}_n^>x_n+\eta\right}}{\mathbf{P}\left{\mathbf{S}_n^>x_n\right}} \rightarrow 0 $$,即$$ \mathbf{P}\left{x_n<\mathbf{S}_n^ \leq x_n+\eta\right} \sim \mathbf{P}\left{\mathbf{S}_n^>x_n\right} . $$,换句话说:当$\mathbf{S}_n^$超过$x_n$时,它很可能非常接近$x_n$,较大的值在限制中不起作用。
证明。用(3.2)表示二项分布
$$
\mathbf{P}\left{\mathbf{S}n^>x_n\right}=\sum{v=0}^{\infty} a_{r_n+v}, \quad \mathbf{P}\left{\mathbf{S}n^>x_n+\eta\right}=\sum{v=0}^{\infty} a_{s_n+v},
$$
其中$r_n$和$s_n$是整数,它们与$x_n \sqrt{n p q}$和$\left(x_n+\eta\right) \sqrt{n p q}$的差别不超过1个单位。从(3.4)中可以明显看出
对于大的$n$
$$
\frac{a_{k+1}}{a_k}<1-p t_k<1-\frac{k}{n}<e^{k / n},
$$
因此
$$
\frac{a_{s_n+v}}{a_{r_n+v}}<e^{-\left(s_n-r_n\right) r_n / n}<e^{-\frac{1}{2} \eta x_n p q} .
$$
通过假设$x_n \rightarrow \infty$,因此(6.3)中第二个系列的项与第一个系列的相应项相比,往往变得可以忽略不计。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。