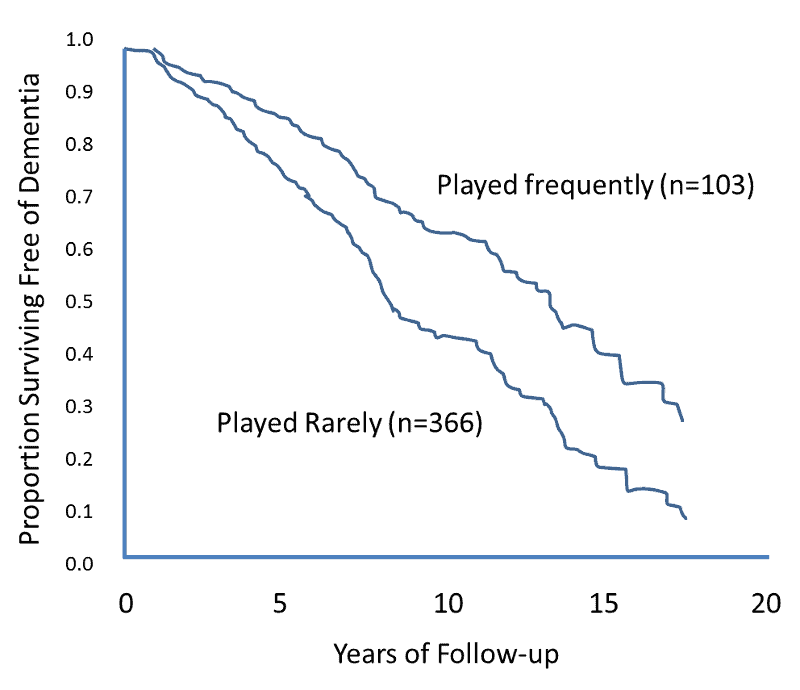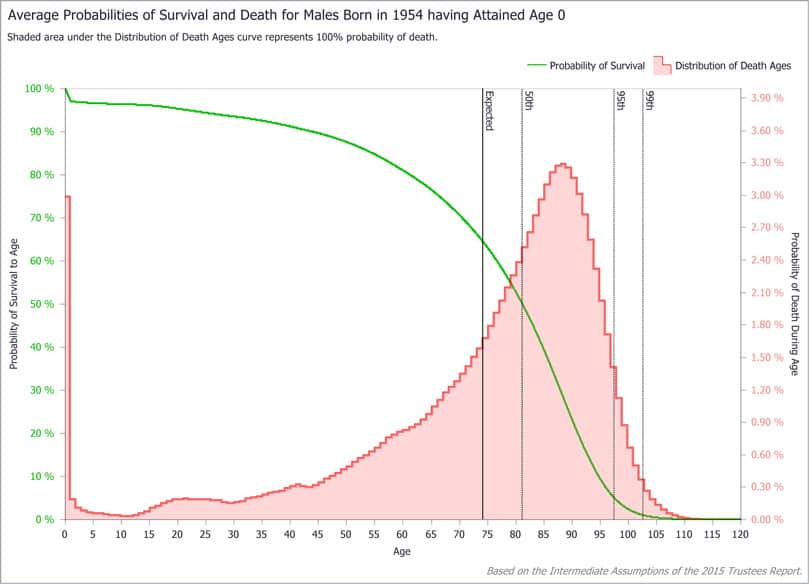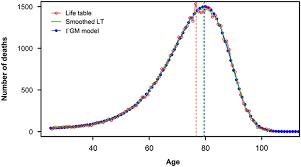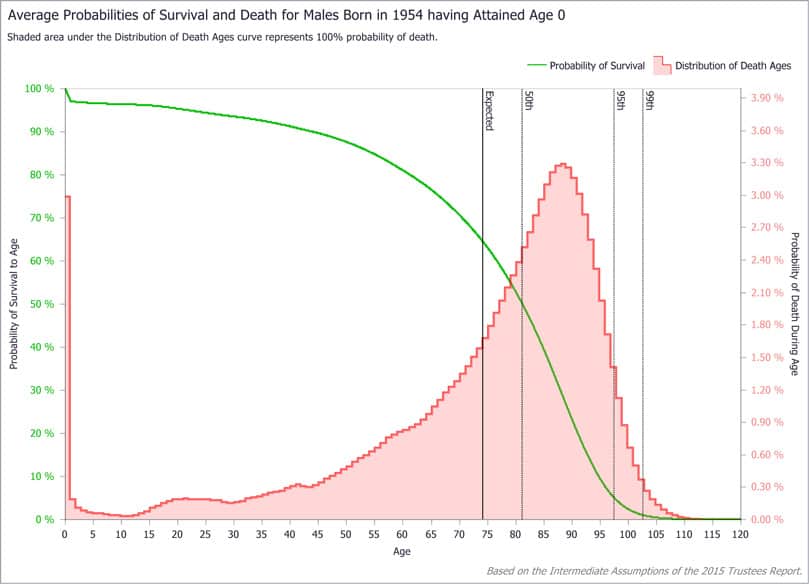
统计代写|生存模型代写survival model代考|FISCAL AGES
如果你也在 怎样代写生存模型Survival Models这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。生存模型Survival Models在许多可用于分析事件时间数据的模型中,有4个是最突出的:Kaplan Meier模型、指数模型、Weibull模型和Cox比例风险模型。
生存模型Survival Models精算师和其他应用数学家使用预测人类或其他实体(有生命或无生命)生存模式的模型,并经常使用这些模型作为相当重要的财务计算的基础。具体来说,精算师使用这些模型来计算与个人人寿保险单、养老金计划和收入损失保险相关的财务价值。人口统计学家和其他社会科学家使用生存模型对该模型适用的人口的未来构成做出预测。
statistics-lab™ 为您的留学生涯保驾护航 在代写生存模型survival model方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写生存模型survival model代写方面经验极为丰富,各种代写生存模型survival model相关的作业也就用不着说。
统计代写|生存模型代写survival model代考|FISCAL AGES
In the case of group insurance or group pension plans, a large number of individual persons are covered under a single policy or plan. There will exist a key date for such a plan, called the plan anniversary or plan valuation date. On such a date it will be necessary to calculate premium rates, actuarial present values of accrued benefits, or other financial values. For this purpose it will be convenient for all members of the plan to be an integral age on this key date. This integral age is called the fiscal age.
Note that this situation is similar to that under insuring ages, where each individual insured was an integral insuring age on that person’s policy anniversary. Here the same idea holds, with the further condition that the policy anniversary is the same date for all persons. It is traditional to refer to this date as the $\boldsymbol{T}$-date.
Historically the terms T-date and fiscal age were adopted to indicate that the T-date was the terminal date of the fiscal year of an enterprise. In this text we feel that the major application of the fiscal age concept is to studies of mortality under group insurance or pension plans. Thus the T-date is the plan anniversary. The term fiscal age is not particularly descriptive, but we will retain it for the sake of tradition.
统计代写|生存模型代写survival model代考|Fiscal Year of Birth
Analogous to the definitions of insuring age and valuation year of birth in Section 9.3, we assign each person in a group plan a fiscal age (FA) as of some particular T-date, say the T-date in calendar year $z$. This fiscal age would likely be the actual age nearest birthday on that date, or it could be the actual age last birthday, or the actual calendar age. Regardless of how it is assigned, we then define the fiscal year of birth (FYB) as
$$
F Y B=z-F A .
$$
Just as was true for $V Y B$ under insuring ages, $F Y B$ could be the same as the person’s actual $C Y B$, or it could be one year less or one year greater. Once $F Y B$ has been assigned, the T-date in the $F Y B$ is then the hypothetical date of birth for each person in the group plan.
The natural choice of an observation period is one that runs from the T-date in a certain year to the T-date in a later year. Note that the T-date is the anniversary for all members of the group plan, so a T-to-T study is both a dateto-date study and an anniversary-to-anniversary study.
The principal benefit of using a T-to-T observation period is that all members in the plan when the O.P. opens enter the study at an integral age $y_i$. Similarly, all members in the study sample will have an integral scheduled exit age $z_i$. In turn, we know that integral $y_i$ and $z_i$ imply $r_i=0$ and $s_i=1$ for any estimation interval $(x, x+1]$, and a Special Case A estimation problem.
Although dates other than T-dates can be used in date-to-date fiscal age studies, there is no particular advantage to this, and only T-to-T studies will be considered in this chapter.
生存模型代考
统计代写|生存模型代写survival model代考|FISCAL AGES
就团体保险或团体养恤金计划而言,一项政策或计划涵盖了大量个人。对于这样的计划,将存在一个关键日期,称为计划周年纪念日或计划估值日期。在该日期,将有必要计算保险费率、应计权益的精算现值或其他财务价值。为了达到这个目的,在这个关键的日子里,计划的所有成员都达到法定年龄是很方便的。这个积分年龄被称为财政年龄。
请注意,这种情况类似于投保年龄下的情况,其中每个被保险人都是该人的保单周年纪念日的完整投保年龄。在这里,同样的想法成立,但进一步的条件是,所有人的保单纪念日都是相同的日期。传统上将这个日期称为$\boldsymbol{T}$-date。
历史上使用“t日”和“会计年度”来表示“t日”是企业会计年度的结束日期。在本文中,我们认为财政年龄概念的主要应用是研究团体保险或养恤金计划下的死亡率。因此,t日期是计划周年纪念日。“财政年龄”一词并不是特别具有描述性,但为了传统,我们将保留它。
统计代写|生存模型代写survival model代考|Fiscal Year of Birth
与第9.3节中保险年龄和估价出生年份的定义类似,我们为集团计划中的每个人分配一个截至某个特定t日期的财务年龄(FA),例如日历年$z$中的t日期。该财务年龄可能是最接近该日期生日的实际年龄,也可能是上次生日的实际年龄,或者是实际日历年龄。无论如何分配,我们都将出生财政年度(FYB)定义为
$$
F Y B=z F A。
$$
就像在保险年龄下的V Y B一样,F Y B可以等于这个人实际的C Y B,也可以少一年或多一年。一旦分配了$F Y B$,则$F Y B$中的t日期就是组计划中每个人的假设出生日期。
观察期的自然选择是从某一年的t日期到以后一年的t日期。请注意,T-date是小组计划中所有成员的周年纪念日,因此T-to-T研究既是日期到日期的研究,也是周年到周年的研究。
使用T-to-T观察期的主要好处是,当op开放时,计划中的所有成员都以积分年龄$y_i$进入研究。同样,研究样本中的所有成员都有一个积分计划退出年龄$z_i$。反过来,我们知道积分$y_i$和$z_i$意味着$r_i=0$和$s_i=1$对于任何估计区间$(x, x+1]$,以及一个特殊情况a估计问题。
虽然除了t日期以外的日期也可以用于日期到日期的财政年龄研究,但这并没有特别的优势,本章只考虑t到t的研究。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。