计算机代写|机器学习代写machine learning代考|MKTG6010
如果你也在 怎样代写机器学习Machine Learning 这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。机器学习Machine Learning令人兴奋。这是有趣的,具有挑战性的,创造性的,和智力刺激。它还为公司赚钱,自主处理大量任务,并从那些宁愿做其他事情的人那里消除单调工作的繁重任务。
机器学习Machine Learning也非常复杂。从数千种算法、数百种开放源码包,以及需要具备从数据工程(DE)到高级统计分析和可视化等各种技能的专业实践者,ML专业实践者所需的工作确实令人生畏。增加这种复杂性的是,需要能够与广泛的专家、主题专家(sme)和业务单元组进行跨功能工作——就正在解决的问题的性质和ml支持的解决方案的输出进行沟通和协作。
statistics-lab™ 为您的留学生涯保驾护航 在代写机器学习 machine learning方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写机器学习 machine learning代写方面经验极为丰富,各种代写机器学习 machine learning相关的作业也就用不着说。
计算机代写|机器学习代写machine learning代考|Local Binary Patterns
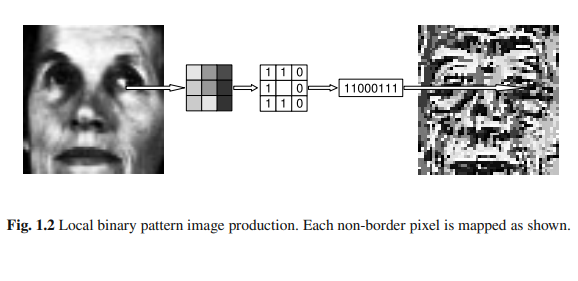
The local binary pattern (LBP) operator [14] is a powerful $2 \mathrm{D}$ texture descriptor that has the benefit of being somewhat insensitive to variations in the lighting and orientation of an image. The method has been successfully applied to applications such as face recognition [1] and facial expression recognition [16]. As illustrated in Fig. 1.2, the LBP algorithm associates each interior pixel of an intensity image with a binary code number in the range $0-256$. This code number is generated by taking the surrounding pixels and, working in a clockwise direction from the top left hand corner, assigning a bit value of 0 where the neighbouring pixel intensity is less than that of the central pixel and 1 otherwise. The concatenation of these bits produces an eight-digit binary code word which becomes the grey-scale value of the corresponding pixel in the transformed image. Figure 1.2 shows a pixel being compared with its immediate neighbours. It is however also possible to compare a pixel with others which are separated by distances of two, three or more pixel widths, giving rise to a series of transformed images. Each such image is generated using a different radius for the circularly symmetric neighbourhood over which the LBP code is calculated.
Another possible refinement is to obtain a finer angular resolution by using more than 8 bits in the code-word [14]. Note that the choice of the top left hand corner as a reference point is arbitrary and that different choices would lead to different LBP codes; valid comparisons can be made, however, provided that the same choice of reference point is made for all pixels in all images.
It is noted in [14] that in practice the majority of LBP codes consist of a concatenation of at most three consecutive sub-strings of $0 \mathrm{~s}$ and $1 \mathrm{~s}$; this means that when the circular neighbourhood of the centre pixel is traversed, the result is either all $0 \mathrm{~s}$, all $1 \mathrm{~s}$ or a starting point can be found which produces a sequence of 0 s followed by a sequence of $1 \mathrm{~s}$. These codes are referred to as uniform patterns and, for an 8 bit code, there are 58 possible values. Uniform patterns are most useful for texture discrimination purposes as they represent local micro-features such as bright spots, flat spots and edges; non-uniform patterns tend to be a source of noise and can therefore usefully be mapped to the single common value 59 .
In order to use LBP codes as a face expression comparison mechanism it is first necessary to subdivide a face image into a number of sub-windows and then compute the occurrence histograms of the LBP codes over these regions. These histograms can be combined to generate useful features, for example by concatenating them or by comparing corresponding histograms from two images.
计算机代写|机器学习代写machine learning代考|Fast Correlation-Based Filtering
Broadly speaking, feature selection algorithms can be divided into two groups: wrapper methods and filter methods [3]. In the wrapper approach different combinations of features are considered and a classifier is trained on each combination to determine which is the most effective. Whilst this approach undoubtedly gives good results, the computational demands that it imposes render it impractical when a very large number of features needs to be considered. In such cases the filter approach may be used; this considers the merits of features in themselves without reference to any particular classification method.
Fast correlation-based filtering (FCBF) has proved itself to be a successful feature selection method that can handle large numbers of features in a computationally efficient way. It works by considering the classification between each feature and the class label and between each pair of features. As a measure of classification the concept of symmetric uncertainty is used; for a pair random variables $X$ and $Y$ this is defined as:
$$
S U(X, Y)=2\left[\frac{I G(X, Y)}{H(X)+H(Y)}\right]
$$
where $H(\cdot)$ is the entropy of the random variable and $I G(X, Y)=H(X)-H(X \mid Y)=$ $H(Y)-H(Y \mid X)$ is the information gain between $X$ and $Y$. As its name suggests, symmetric uncertainty is symmetric in its arguments; it takes values in the range $[0,1]$ where 0 implies independence between the random variables and 1 implies that the value of each variable completely predicts the value of the other. In calculating the entropies of Eq. 1.6, any continuous features must first be discretised.
The FCBF algorithm applies heuristic principles that aim to achieve a balance between using relevant features and avoiding redundant features. It does this by selecting features $f$ that satisfy the following properties:
- $S U(f, c) \geq \delta$ where $c$ is the class label and $\delta$ is a threshold value chosen to suit the application.
- $\forall g: S U(f, g) \geq S U(f, c) \Rightarrow S U(f, c) \geq S U(g, c)$ where $g$ is any feature other than $f$.
Here, property 1 ensures that the selected features are relevant, in that they are correlated with the class label to some degree, and property 2 eliminates redundant features by discarding those that are strongly correlated with a more relevant feature.
机器学习代考
计算机代写|机器学习代写machine learning代考|Local Binary Patterns
局部二元模式(LBP)算子[14]是一种功能强大的$2 \mathrm{D}$纹理描述符,其优点是对图像的光照和方向变化不敏感。该方法已成功应用于人脸识别[1]、面部表情识别[16]等应用。如图1.2所示,LBP算法将强度图像的每个内部像素与范围为$0-256$的二进制码数相关联。这个代码号是通过取周围的像素,从左上角开始顺时针方向工作,在邻近像素强度小于中心像素时分配位值0,否则分配位值1来生成的。这些位的连接产生一个8位二进制码字,它成为转换后的图像中相应像素的灰度值。图1.2显示了一个像素与其近邻的比较。然而,也可以将一个像素与被两个、三个或更多像素宽度的距离隔开的其他像素进行比较,从而产生一系列转换后的图像。每个这样的图像都是使用不同半径的圆对称邻域来生成的,LBP代码是在这个邻域上计算的。
另一种可能的改进是通过在码字中使用超过8位来获得更精细的角度分辨率[14]。注意,左上角作为参考点的选择是任意的,不同的选择将导致不同的LBP代码;然而,只要对所有图像中的所有像素选择相同的参考点,就可以进行有效的比较。
在[14]中指出,在实践中,大多数LBP码由最多三个连续的$0 \mathrm{~s}$和$1 \mathrm{~s}$子串组成;这意味着当遍历中心像素的圆形邻域时,结果要么是全部$0 \mathrm{~s}$,全部$1 \mathrm{~s}$,要么可以找到一个起点,它产生一个0 s序列,后面是一个$1 \mathrm{~s}$序列。这些代码被称为统一模式,对于一个8位的代码,有58个可能的值。均匀的图案在纹理识别中最有用,因为它们代表了局部的微特征,如亮点、平斑和边缘;不均匀的模式往往是噪声源,因此可以有效地映射到单一的公共值59。
为了使用LBP码作为人脸表情比较机制,首先需要将人脸图像细分为多个子窗口,然后计算这些区域上LBP码的出现直方图。这些直方图可以组合起来生成有用的特征,例如通过连接它们或比较来自两幅图像的相应直方图。
计算机代写|机器学习代写machine learning代考|Fast Correlation-Based Filtering
包装器方法考虑了不同的特征组合,并在每种组合上训练分类器,以确定哪种组合最有效。虽然这种方法无疑给出了很好的结果,但当需要考虑非常大量的特征时,它所施加的计算需求使其不切实际。在这种情况下,可以使用过滤器方法;这考虑了特征本身的优点,而不参考任何特定的分类方法。
快速相关滤波(Fast correlation-based filtering, FCBF)是一种成功的特征选择方法,能够以高效的计算方式处理大量特征。它通过考虑每个特征与类标号之间以及每对特征之间的分类来工作。作为分类的度量,对称不确定性的概念被使用;对于一对随机变量$X$和$Y$,定义为:
$$
S U(X, Y)=2\left[\frac{I G(X, Y)}{H(X)+H(Y)}\right]
$$
其中$H(\cdot)$为随机变量的熵,$I G(X, Y)=H(X)-H(X \mid Y)=$$H(Y)-H(Y \mid X)$为$X$与$Y$之间的信息增益。顾名思义,对称不确定性在其参数中是对称的;它的取值范围为$[0,1]$,其中0表示随机变量之间的独立性,1表示每个变量的值完全预测另一个变量的值。在计算Eq. 1.6的熵时,必须首先对任何连续特征进行离散。
FCBF算法采用启发式原则,目的是在使用相关特征和避免冗余特征之间取得平衡。它通过选择满足以下属性的功能$f$来实现这一点:
$S U(f, c) \geq \delta$ 其中$c$是类标签,$\delta$是为适应应用程序而选择的阈值。
$\forall g: S U(f, g) \geq S U(f, c) \Rightarrow S U(f, c) \geq S U(g, c)$ 其中$g$是除$f$之外的任何特性。
在这里,属性1确保所选择的特征是相关的,因为它们在某种程度上与类标签相关,而属性2通过丢弃那些与更相关的特征强烈相关的特征来消除冗余特征

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。