如果你也在 怎样代写机器学习Machine Learning 这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。机器学习Machine Learning令人兴奋。这是有趣的,具有挑战性的,创造性的,和智力刺激。它还为公司赚钱,自主处理大量任务,并从那些宁愿做其他事情的人那里消除单调工作的繁重任务。
机器学习Machine Learning也非常复杂。从数千种算法、数百种开放源码包,以及需要具备从数据工程(DE)到高级统计分析和可视化等各种技能的专业实践者,ML专业实践者所需的工作确实令人生畏。增加这种复杂性的是,需要能够与广泛的专家、主题专家(sme)和业务单元组进行跨功能工作——就正在解决的问题的性质和ml支持的解决方案的输出进行沟通和协作。
statistics-lab™ 为您的留学生涯保驾护航 在代写机器学习 machine learning方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写机器学习 machine learning代写方面经验极为丰富,各种代写机器学习 machine learning相关的作业也就用不着说。
计算机代写|机器学习代写machine learning代考|Process over technology
The success of a feature store implementation is not in the specific technology used to implement it. The benefit is in the actions it enables a company to take with its calculated and standardized feature data.
Let’s briefly examine an ideal process for a company that needs to update the definition of its revenue metric. For such a broadly defined term, the concept of revenue at a company can be interpreted in many ways, depending on the end-use case, the department concerned with the usage of that data, and the level of accounting standards applied to the definition for those use cases.
A marketing group, for instance, may be interested in gross revenue for measuring the success rate of advertising campaigns. The DE group may define multiple variations of revenue to handle the needs of different groups within the company. The DS team may be looking at a windowed aggregation of any column in the data warehouse that has the words “sales,” “revenue,” or “cost” in it to create feature data. The BI team might have a more sophisticated set of definitions that appeal to a broader set of analytics use cases.
Changing a definition of the logic of such a key business metric can have farreaching impacts to an organization if everyone is responsible for their group’s personal definitions. The likelihood of each group changing its references in each of the queries, code bases, reports, and models that it is responsible for is marginal. Fragmenting the definition of such an important metric across departments is problematic enough on its own. Creating multiple versions of the defining characteristics within each group is a recipe for complete chaos. With no established standard for how key business metrics are defined, groups within a company are effectively no longer speaking on even terms when evaluating the results and outputs from one another.
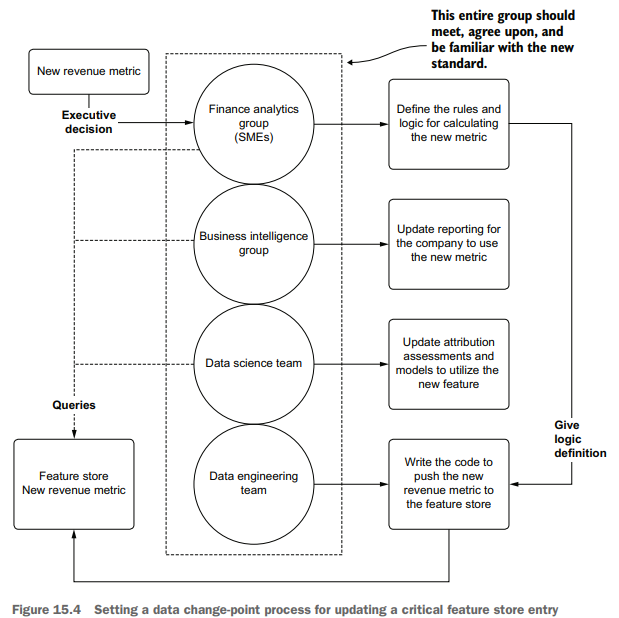
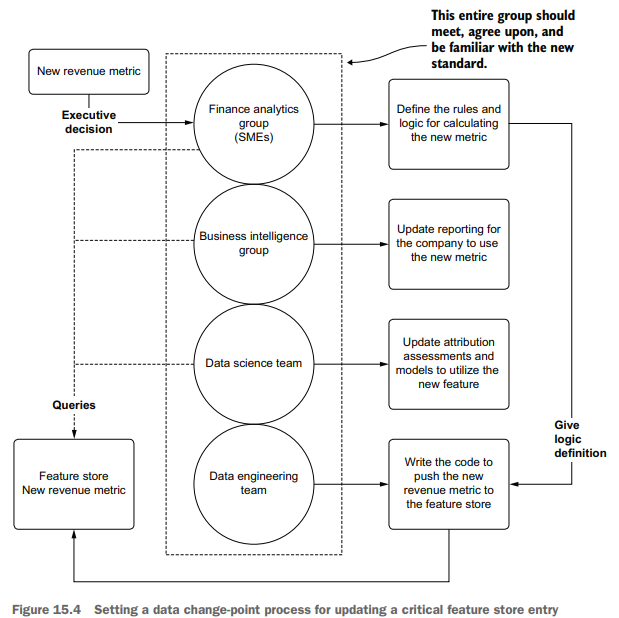
Regardless of the technology stack used to store the data for consumption, having a process built around change management for critical features can guarantee a frictionless and resilient data migration. Figure 15.4 illustrates such a process.
计算机代写|机器学习代写machine learning代考|The dangers of a data silo
Data silos are deceptively dangerous. Isolating data in a walled-off, private location that is accessible only to a certain select group of individuals stifles the productivity of other teams, causes a large amount of duplicated effort throughout an organization, and frequently (in my experience of seeing them, at least) leads to esoteric data definitions that, in their isolation, depart wildly from the general accepted view of a metric for the rest of the company.
It may seem like a really great thing when an ML team is granted a database of its own or an entire cloud object store bucket to empower the team to be self-service. The seemingly geologically scaled time spent for the DE or warehousing team to load required datasets disappears. The team members are fully masters of their domain, able to load, consume, and generate data with impunity. This can definitely be a good thing, provided that clear and soundly defined processes govern the management of this technology.
But clean or dirty, an internal-use-only data storage stack is a silo, the contents squirreled away from the outside world. These silos can generate more problems than they solve.
To show how a data silo can be disadvantageous, let’s imagine that we work at a company that builds dog parks. Our latest ML project is a bit of a moon shot, working with counterfactual simulations (causal modeling) to determine which amenities would be most valuable to our customers at different proposed construction sites. The goal is to figure out how to maximize the perceived quality and value of the proposed parks while minimizing our company’s investment costs.
To build such a solution, we have to get data on all of the registered dog parks in the country. We also need demographic data associated with the localities of these dog parks. Since the company’s data lake contains no data sources that have this information, we have to source it ourselves. Naturally, we put all of this information in our own environment, thinking it will be far faster than waiting for the DE team’s backlog to clear enough to get around to working on it.
After a few months, questions began to arise about some of the contracts that the company had bid on in certain locales. The business operations team is curious about why so many orders for custom paw-activated watering fountains are being ordered as part of some of these construction inventories. As the analysts begin to dig into the data available in the data lake, they can’t make sense of why the recommendations for certain contracts consistently recommended these incredibly expensive components.
机器学习代考
计算机代写|机器学习代写machine learning代考|Process over technology
功能库实现的成功不在于实现它所使用的特定技术。其好处在于,它使公司能够利用其计算和标准化的特征数据采取行动。
让我们简要地研究一下需要更新收入指标定义的公司的理想流程。对于这样一个定义广泛的术语,公司收入的概念可以用多种方式解释,这取决于最终用例、与该数据的使用有关的部门,以及应用于这些用例定义的会计标准的级别。
例如,一个营销团队可能对毛收入感兴趣,以衡量广告活动的成功率。DE组可以定义多种收入变化来处理公司内不同组的需求。DS团队可能会查看数据仓库中包含“销售”、“收入”或“成本”字样的任何列的窗口聚合,以创建特征数据。BI团队可能拥有更复杂的定义集,以吸引更广泛的分析用例集。
如果每个人都对其团队的个人定义负责,那么更改此类关键业务度量的逻辑定义可以对组织产生深远的影响。每个组在其负责的每个查询、代码库、报告和模型中更改其引用的可能性很小。跨部门划分如此重要的度量标准的定义本身就有足够的问题。在每个组中创建定义特征的多个版本会导致完全的混乱。由于没有关于如何定义关键业务指标的既定标准,公司内部的团队在评估彼此的结果和输出时,实际上不再以平等的方式说话。
无论使用何种技术堆栈来存储供消费的数据,围绕关键特性的变更管理构建流程都可以保证无摩擦且有弹性的数据迁移。图15.4说明了这样一个过程。
计算机代写|机器学习代写machine learning代考|The dangers of a data silo
数据孤岛看起来很危险。将数据隔离在一个封闭的私有位置,只有特定的一组个人可以访问,这会扼杀其他团队的生产力,在整个组织中导致大量的重复工作,并且经常(至少在我看到他们的经验中)导致深奥的数据定义,在他们的隔离中,与公司其他部分普遍接受的度量标准观点背道而驰。
当ML团队被授予自己的数据库或整个云对象存储桶以授权团队进行自助服务时,这似乎是一件非常棒的事情。DE或仓库团队加载所需数据集所花费的时间似乎是按地质比例计算的。团队成员完全掌握了他们的领域,能够不受惩罚地加载、使用和生成数据。这绝对是一件好事,前提是该技术的管理有清晰而完善的流程定义。
但是,无论是干净的还是脏的,仅供内部使用的数据存储堆栈都是一个筒仓,其内容与外部世界隔绝。这些竖井产生的问题比它们解决的问题要多。
为了说明数据孤岛是多么的不利,让我们想象一下,我们在一家建造狗公园的公司工作。我们最新的机器学习项目有点像登月,使用反事实模拟(因果模型)来确定在不同的拟建工地,哪些设施对我们的客户最有价值。我们的目标是找出如何最大限度地提高拟建公园的质量和价值,同时最大限度地降低公司的投资成本。
为了建立这样的解决方案,我们必须获得全国所有注册狗公园的数据。我们还需要与这些狗公园所在地相关的人口统计数据。由于公司的数据湖不包含包含此信息的数据源,因此我们必须自己查找。很自然地,我们把所有这些信息放在我们自己的环境中,认为这样做比等待DE团队的待办事项清理干净以便腾出时间进行工作要快得多。
几个月后,该公司在某些地区投标的一些合同开始出现问题。业务运营团队很好奇,为什么这么多定制的爪动喷水器订单被订购,作为这些建筑库存的一部分。当分析师开始挖掘数据湖中的可用数据时,他们无法理解为什么某些合同的建议总是推荐这些非常昂贵的组件。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。