如果你也在 怎样代写机器学习Machine Learning 这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。机器学习Machine Learning令人兴奋。这是有趣的,具有挑战性的,创造性的,和智力刺激。它还为公司赚钱,自主处理大量任务,并从那些宁愿做其他事情的人那里消除单调工作的繁重任务。
机器学习Machine Learning也非常复杂。从数千种算法、数百种开放源码包,以及需要具备从数据工程(DE)到高级统计分析和可视化等各种技能的专业实践者,ML专业实践者所需的工作确实令人生畏。增加这种复杂性的是,需要能够与广泛的专家、主题专家(sme)和业务单元组进行跨功能工作——就正在解决的问题的性质和ml支持的解决方案的输出进行沟通和协作。
statistics-lab™ 为您的留学生涯保驾护航 在代写机器学习 machine learning方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写机器学习 machine learning代写方面经验极为丰富,各种代写机器学习 machine learning相关的作业也就用不着说。
计算机代写|机器学习代写machine learning代考|Feature stores
We briefly touched on using a feature store in the preceding chapter. While it is important to understand the justification for and benefits of implementing a feature store (namely, that of consistency, reusability, and testability), seeing an application of a relatively nascent technology is more relevant than discussing the theory. Here, we’re going to look at a scenario that I struggled through, involving the importance of utilizing a feature store to enforce consistency throughout an organization leveraging both ML and advanced analytics.
Let’s imagine that we work at a company that has multiple DS teams. Within the engineering group, the main DS team focuses on company-wide initiatives. This team works mostly on large-scale projects involving critical services that can be employed by any group within the company, as well as customer-facing services. Spread among departments are a smattering of independent contributor DS employees who have been hired by and report to their respective department heads. While collaboration occurs, the main datasets used by the core DS team are not open for the independent DS employees’ use.
At the start of a new year, a department head hires a new DS straight out of a university program. Well-intentioned, driven, and passionate, this new hire immediately gets to work on the initiatives that this department head wants investigated. In the process of analyzing the characteristics of the customers of the company, the new hire come across a production table that contains probabilities for customers to make a call-center complaint. Curious, the new DS begins analyzing the predictions against the data that is in the data warehouse for their department.
Unable to reconcile any feature data to the predictions, the DS begins working on a new model prototype to try to improve upon the complaint prediction solution. After spending a few weeks, the DS presents their findings to their department head. Given the go-ahead to work on this project, the DS proceeds to build a project in their analytics department workspace. After several months, the DS presents their findings at a company all-hands meeting.
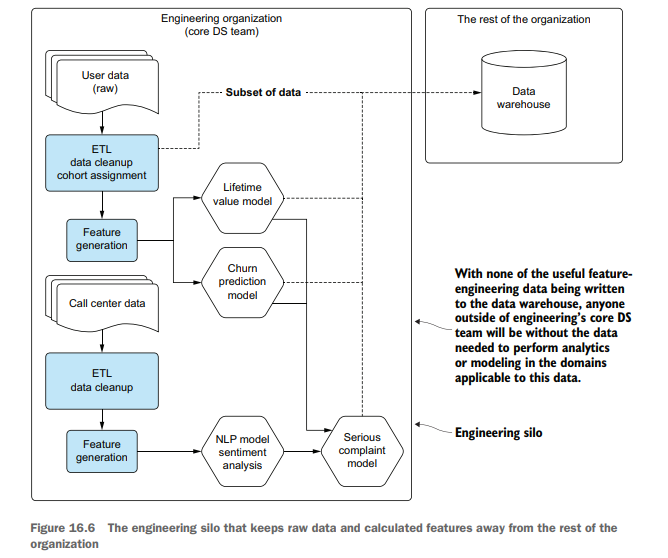
Confused, the core DS team asks why this project is being worked on and for further details on the implementation. In less than an hour, the core DS team is able to explain why the independent DS’s solution worked so well: they leaked the label. Figure 16.6 illustrates the core DS team’s explanation: the data required to build any new model or perform extensive analysis of the data collected from users is walled off by the silo surrounding the core DS team’s engineering department.
The data being used for training that was present in the department’s data warehouse was being fed from the core DS team’s production solution. Each source feature used to train the core model was inaccessible to anyone apart from engineering and production processes.
计算机代写|机器学习代写machine learning代考|What a feature store is used for
Solving the data silo issue in our scenario is among the most compelling reasons to use a feature store. When dealing with a distributed DS capability throughout an organization, the benefits of standardization and accessibility are seen through a reduction in redundant work, incongruous analyses, and general confusion surrounding the veracity of solutions.
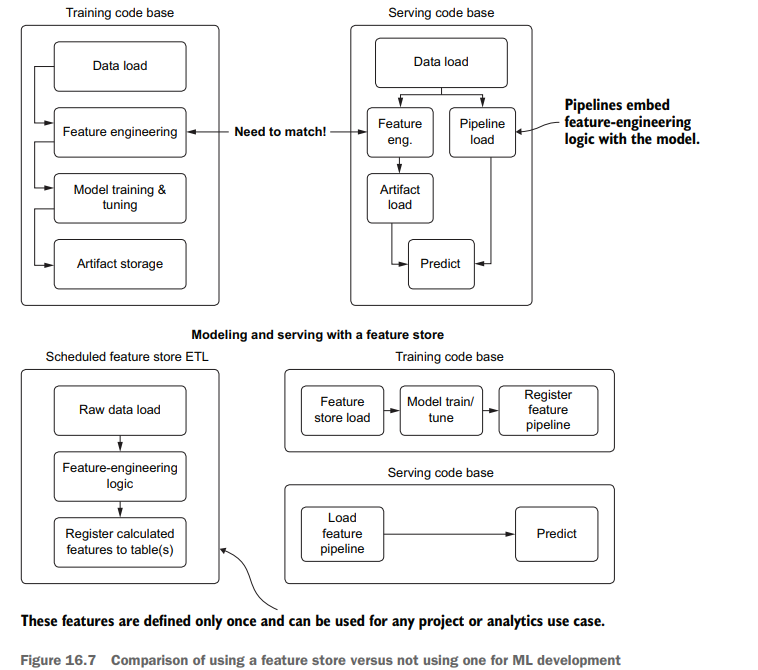
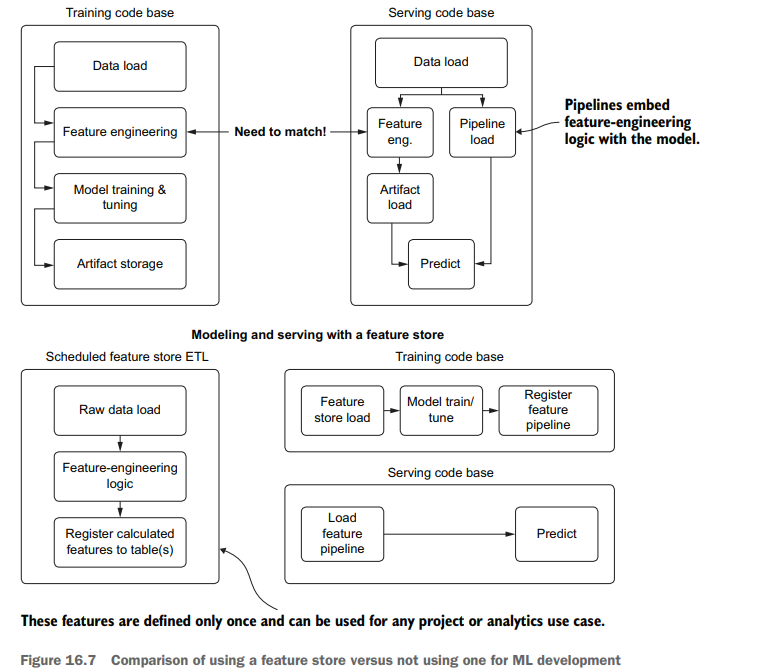
However, having a feature store enables an organization to do far more with its data than just quality-control it. To illustrate these benefits, figure 16.7 shows a highlevel code architecture for model building and serving with and without a feature store.
The top portion of figure 16.7 shows the historical reality of ML development for projects. Tightly coupled feature-engineering code is developed inline to the model tuning and training code to generate models that are more effective than they would be if trained on the raw data. While this architecture makes sense from a development perspective of generating a good model, it creates an issue when developing the prediction code base (as shown at the top right of figure 16.7).
Any operations that are done to the raw data now need to be ported over to this serving code, presenting an opportunity for errors and inconsistencies in the model vector. Alternatives to this approach can help eliminate the chances of data inconsistency, however:
” Use a pipeline (most major ML frameworks have them).
Abstract feature-engineering code into a package that training and serving can both call.
“Write traditional ETL to generate features and store them.
机器学习代考
计算机代写|机器学习代写machine learning代考|Feature stores
在前一章中,我们简要地谈到了使用功能库。虽然理解实现特性存储(即一致性、可重用性和可测试性)的理由和好处很重要,但看到一个相对新兴技术的应用比讨论理论更有意义。在这里,我们将看到一个我曾经历过的场景,涉及到利用特性存储来在组织中同时利用ML和高级分析来加强一致性的重要性。
让我们想象一下,我们在一家拥有多个DS团队的公司工作。在工程团队中,主要的DS团队专注于公司范围内的计划。该团队主要从事涉及关键服务的大型项目,这些服务可以由公司内的任何团队使用,以及面向客户的服务。分散在各个部门之间的是一小部分独立贡献者DS员工,他们被各自的部门主管雇用并向其报告。当协作发生时,核心DS团队使用的主要数据集不开放给独立的DS员工使用。
新年伊始,一位部门主管直接从大学项目中招聘了一名新的副主任。这位新员工动机良好、干劲十足、充满激情,他立即着手部门主管希望调查的项目。在分析公司客户特征的过程中,新员工看到了一张生产表,上面写着客户向呼叫中心投诉的概率。奇怪的是,新的DS开始根据数据仓库中的数据分析预测。
由于无法将任何特征数据与预测相一致,DS开始研究一个新的模型原型,试图改进投诉预测解决方案。经过几周的调查后,副警长将他们的调查结果提交给部门主管。在这个项目上工作的许可下,DS继续在他们的分析部门工作空间中构建一个项目。几个月后,董事总经理在公司全体会议上公布了他们的调查结果。
核心DS团队感到很困惑,他们问为什么要做这个项目,并想知道更多关于实现的细节。在不到一个小时的时间里,核心DS团队能够解释为什么独立DS的解决方案如此有效:他们泄露了标签。图16.6说明了核心DS团队的解释:构建任何新模型或对从用户收集的数据进行广泛分析所需的数据被核心DS团队的工程部门周围的筒仓隔离开来。
部门数据仓库中用于培训的数据来自核心DS团队的生产解决方案。用于训练核心模型的每个源特征除了工程和生产过程之外,任何人都无法访问。
计算机代写|机器学习代写machine learning代考|What a feature store is used for
在我们的场景中,解决数据竖井问题是使用特性存储最令人信服的原因之一。在整个组织中处理分布式DS功能时,通过减少冗余工作、不一致的分析和围绕解决方案准确性的普遍混淆,可以看到标准化和可访问性的好处。
然而,拥有一个功能商店使组织能够对其数据做更多的事情,而不仅仅是对其进行质量控制。为了说明这些好处,图16.7显示了用于模型构建和使用或不使用特性库的高级代码体系结构。
图16.7的顶部显示了项目ML开发的历史现实。紧密耦合的特征工程代码与模型调优和训练代码内联开发,以生成比在原始数据上训练更有效的模型。虽然从生成良好模型的开发角度来看,这种体系结构是有意义的,但是在开发预测代码库时,它会产生一个问题(如图16.7的右上角所示)。
对原始数据所做的任何操作现在都需要移植到此服务代码中,这就为模型向量中的错误和不一致提供了机会。然而,这种方法的替代方法可以帮助消除数据不一致的可能性:
“使用管道(大多数主流ML框架都有管道)。
将特征工程代码抽象为培训和服务都可以调用的包。
“编写传统的ETL来生成特征并存储它们。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。